 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotIO: A Python Library for Robot Manipulation Experiments
Aug 16, 2022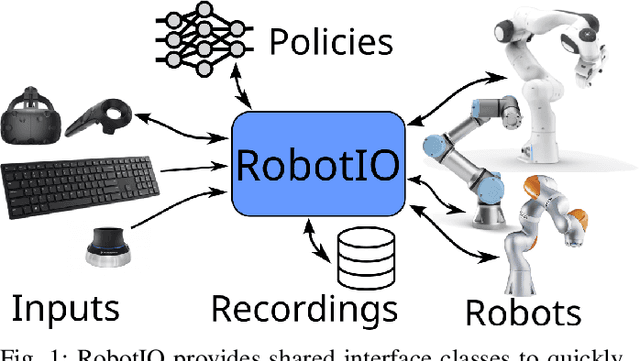
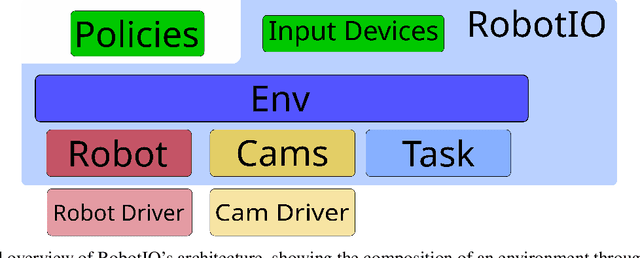

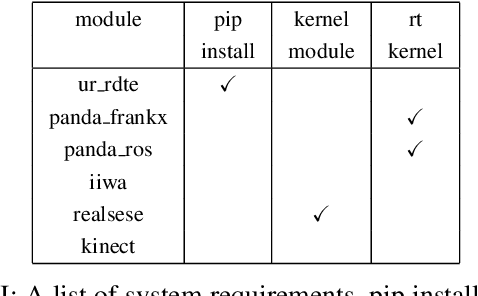
Setting up robot environments to quickly test newly developed algorithms is still a difficult and time consuming process. This presents a significant hurdle to researchers interested in performing real-world robotic experiments. RobotIO is a python library designed to solve this problem. It focuses on providing common, simple, and well structured python interfaces for robots, grippers, and cameras, etc. These are provided with implementations of these interfaces for common hardware. This enables code using RobotIO to be portable across different robot setups. In terms of architecture, RobotIO is designed to be compatible with OpenAI gym environments, as well as ROS; examples of both of these are provided. The library comes together with a number of helpful tools, such as camera calibration scripts and episode recording functionality that further support algorithm development.
What Matters in Language Conditioned Robotic Imitation Learning
Apr 13, 2022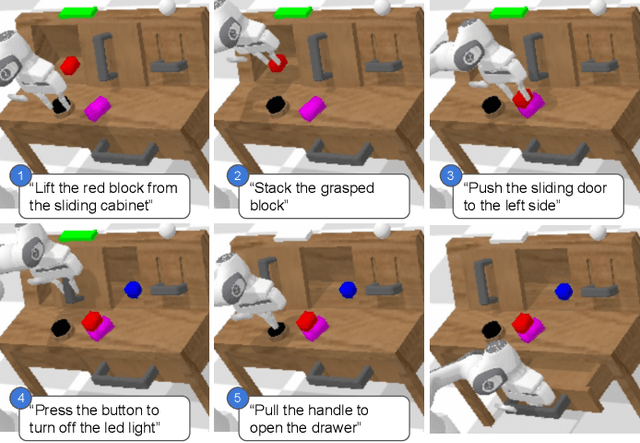
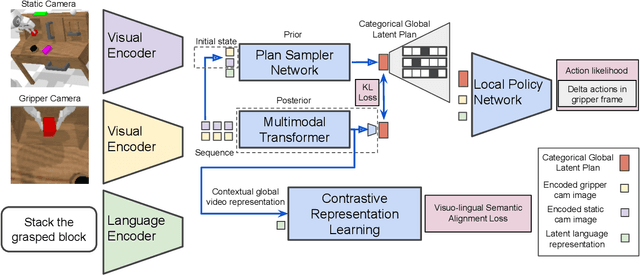
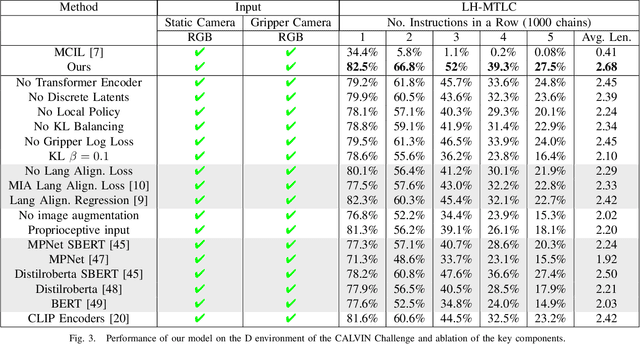
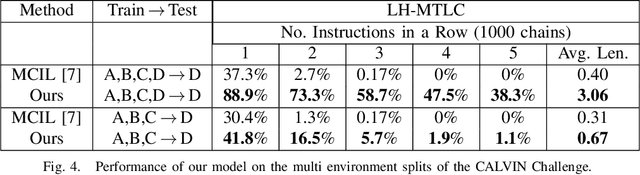
A long-standing goal in robotics is to build robots that can perform a wide range of daily tasks from perceptions obtained with their onboard sensors and specified only via natural language. While recently substantial advances have been achieved in language-driven robotics by leveraging end-to-end learning from pixels, there is no clear and well-understood process for making various design choices due to the underlying variation in setups. In this paper, we conduct an extensive study of the most critical challenges in learning language conditioned policies from offline free-form imitation datasets. We further identify architectural and algorithmic techniques that improve performance, such as a hierarchical decomposition of the robot control learning, a multimodal transformer encoder, discrete latent plans and a self-supervised contrastive loss that aligns video and language representations. By combining the results of our investigation with our improved model components, we are able to present a novel approach that significantly outperforms the state of the art on the challenging language conditioned long-horizon robot manipulation CALVIN benchmark. We have open-sourced our implementation to facilitate future research in learning to perform many complex manipulation skills in a row specified with natural language. Codebase and trained models available at http://hulc.cs.uni-freiburg.de
Affordance Learning from Play for Sample-Efficient Policy Learning
Mar 01, 2022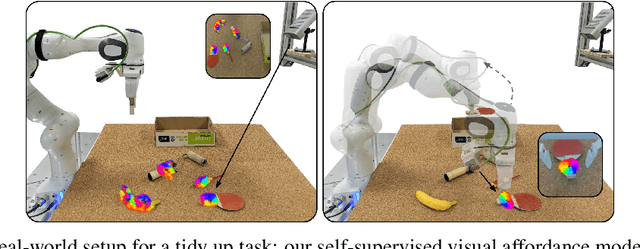
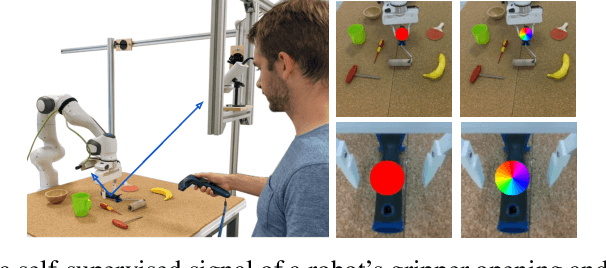
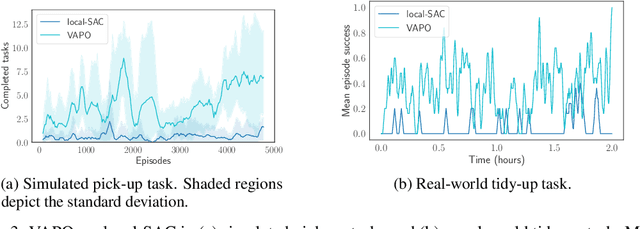
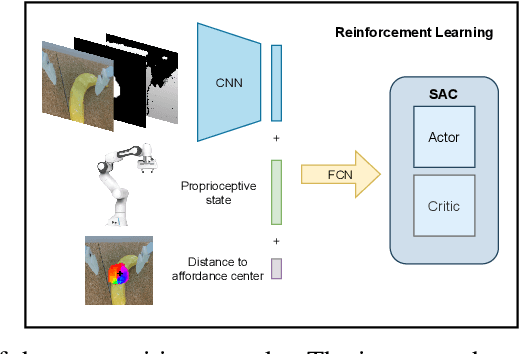
Robots operating in human-centered environments should have the ability to understand how objects function: what can be done with each object, where this interaction may occur, and how the object is used to achieve a goal. To this end, we propose a novel approach that extracts a self-supervised visual affordance model from human teleoperated play data and leverages it to enable efficient policy learning and motion planning. We combine model-based planning with model-free deep reinforcement learning (RL) to learn policies that favor the same object regions favored by people, while requiring minimal robot interactions with the environment. We evaluate our algorithm, Visual Affordance-guided Policy Optimization (VAPO), with both diverse simulation manipulation tasks and real world robot tidy-up experiments to demonstrate the effectiveness of our affordance-guided policies. We find that our policies train 4x faster than the baselines and generalize better to novel objects because our visual affordance model can anticipate their affordance regions.
CALVIN: A Benchmark for Language-conditioned Policy Learning for Long-horizon Robot Manipulation Tasks
Dec 08, 2021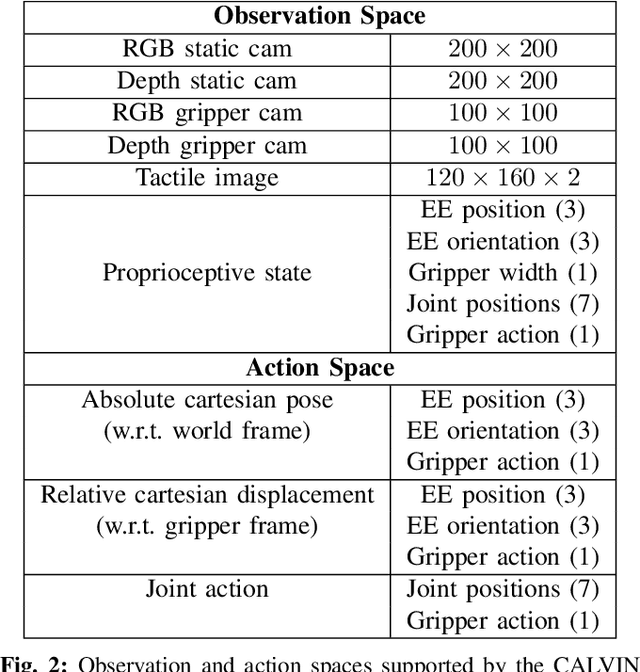
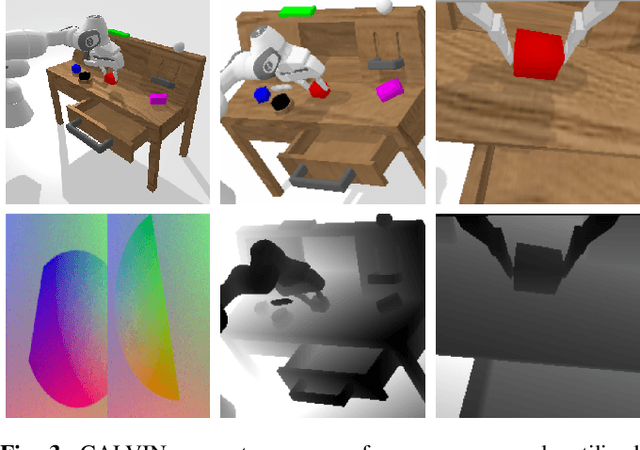

General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions. In this paper, we present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites. We evaluate the agents in zero-shot to novel language instructions and to novel environments and objects. We show that a baseline model based on multi-context imitation learning performs poorly on CALVIN, suggesting that there is significant room for developing innovative agents that learn to relate human language to their world models with this benchmark.
Pre-training of Deep RL Agents for Improved Learning under Domain Randomization
Apr 29, 2021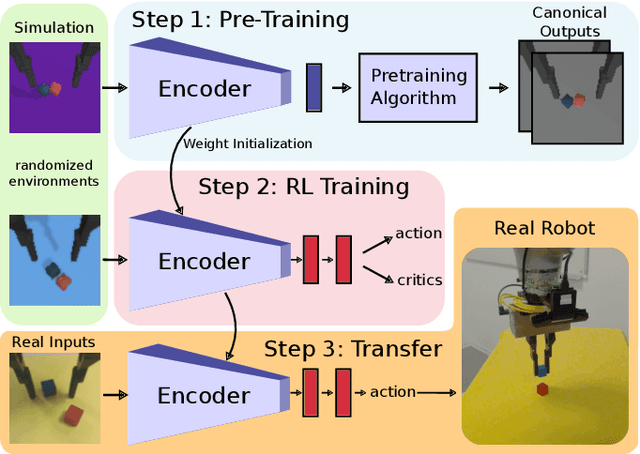

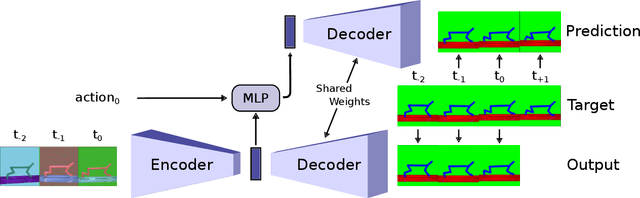
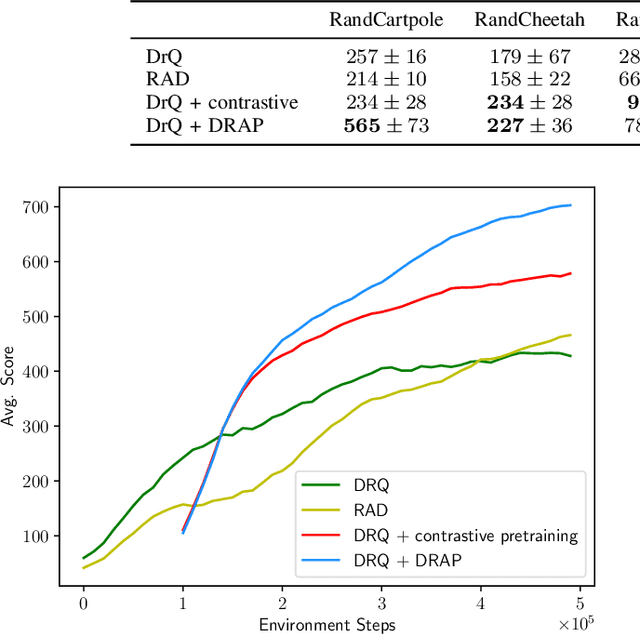
Visual domain randomization in simulated environments is a widely used method to transfer policies trained in simulation to real robots. However, domain randomization and augmentation hamper the training of a policy. As reinforcement learning struggles with a noisy training signal, this additional nuisance can drastically impede training. For difficult tasks it can even result in complete failure to learn. To overcome this problem we propose to pre-train a perception encoder that already provides an embedding invariant to the randomization. We demonstrate that this yields consistently improved results on a randomized version of DeepMind control suite tasks and a stacking environment on arbitrary backgrounds with zero-shot transfer to a physical robot.
Hindsight for Foresight: Unsupervised Structured Dynamics Models from Physical Interaction
Aug 02, 2020
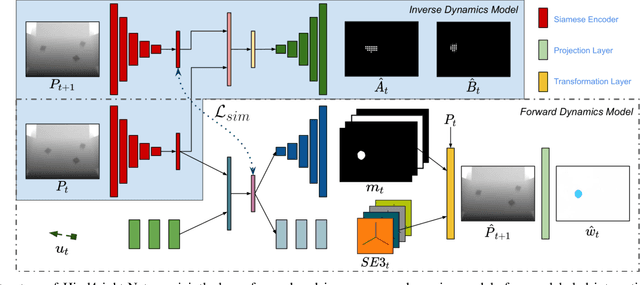
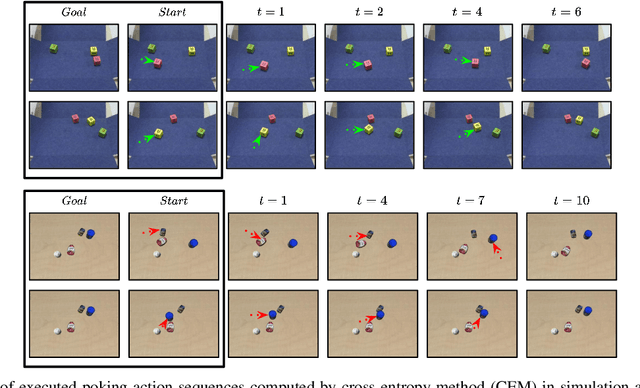
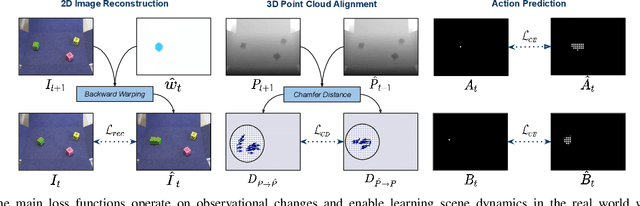
A key challenge for an agent learning to interact with the world is to reason about physical properties of objects and to foresee their dynamics under the effect of applied forces. In order to scale learning through interaction to many objects and scenes, robots should be able to improve their own performance from real-world experience without requiring human supervision. To this end, we propose a novel approach for modeling the dynamics of a robot's interactions directly from unlabeled 3D point clouds and images. Unlike previous approaches, our method does not require ground-truth data associations provided by a tracker or any pre-trained perception network. To learn from unlabeled real-world interaction data, we enforce consistency of estimated 3D clouds, actions and 2D images with observed ones. Our joint forward and inverse network learns to segment a scene into salient object parts and predicts their 3D motion under the effect of applied actions. Moreover, our object-centric model outputs action-conditioned 3D scene flow, object masks and 2D optical flow as emergent properties. Our extensive evaluation both in simulation and with real-world data demonstrates that our formulation leads to effective, interpretable models that can be used for visuomotor control and planning. Videos, code and dataset are available at http://hind4sight.cs.uni-freiburg.de
FlowControl: Optical Flow Based Visual Servoing
Jul 01, 2020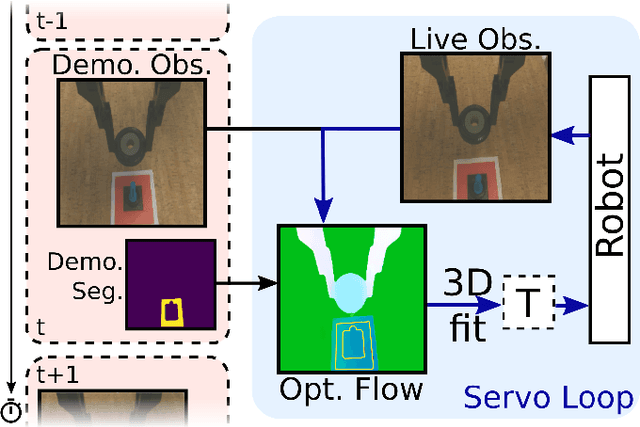
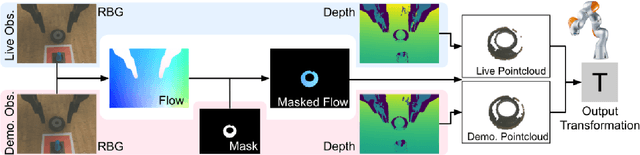


One-shot imitation is the vision of robot programming from a single demonstration, rather than by tedious construction of computer code. We present a practical method for realizing one-shot imitation for manipulation tasks, exploiting modern learning-based optical flow to perform real-time visual servoing. Our approach, which we call FlowControl, continuously tracks a demonstration video, using a specified foreground mask to attend to an object of interest. Using RGB-D observations, FlowControl requires no 3D object models, and is easy to set up. FlowControl inherits great robustness to visual appearance from decades of work in optical flow. We exhibit FlowControl on a range of problems, including ones requiring very precise motions, and ones requiring the ability to generalize.
Adaptive Curriculum Generation from Demonstrations for Sim-to-Real Visuomotor Control
Oct 31, 2019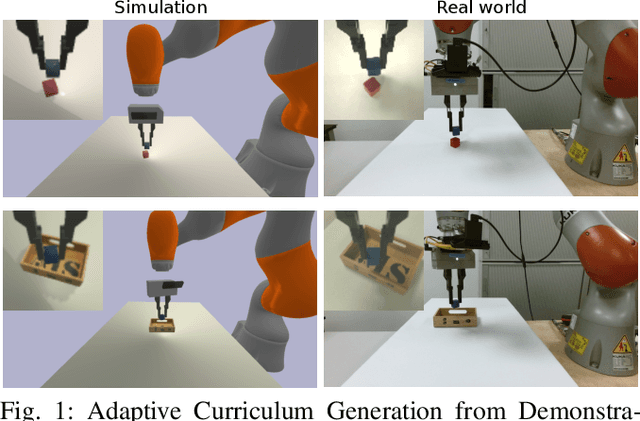
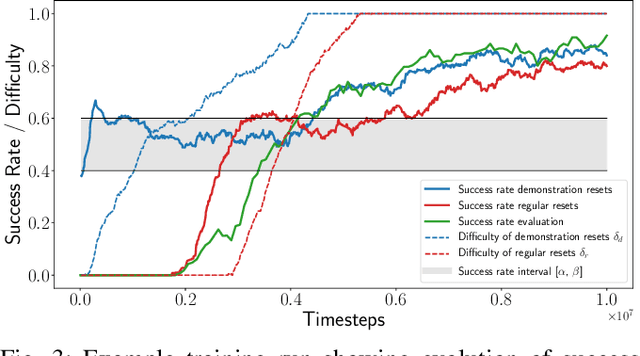
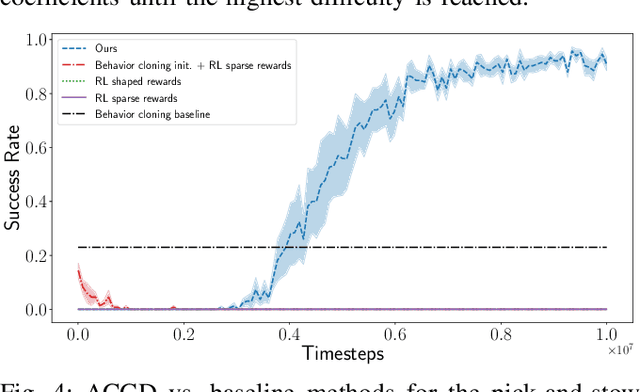
We propose Adaptive Curriculum Generation from Demonstrations (ACGD) for reinforcement learning in the presence of sparse rewards. Rather than designing shaped reward functions, ACGD adaptively sets the appropriate task difficulty for the learner by controlling where to sample from the demonstration trajectories and which set of simulation parameters to use. We show that training vision-based control policies in simulation while gradually increasing the difficulty of the task via ACGD improves the policy transfer to the real world. The degree of domain randomization is also gradually increased through the task difficulty. We demonstrate zero-shot transfer for two real-world manipulation tasks: pick-and-stow and block stacking. A video showing the results can be found at https://lmb.informatik.uni-freiburg.de/projects/curriculum/