 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Recurrent Intention Switching Model
May 26, 2026Inverse reinforcement learning (IRL) recovers reward functions from observed behavior, yet traditional methods assume a single stationary reward that cannot capture goal switching within an episode. Recent multi-intention IRL methods address this by segmenting trajectories, but model intention transitions as either a memoryless Markov chain or via manual state augmentation with a fixed history window. We propose the Probabilistic Recurrent Intention Switching Model (PRISM), which replaces both mechanisms with a lightweight recurrent network that maps observation history to a per-step intention distribution. We prove that the resulting EM objective decomposes exactly into independent per-intention reward subproblems, each solvable in closed form, yielding an $\mathcal{O}(nK)$ E-step with no variational approximation. We evaluate PRISM on a non-Markovian gridworld, a mouse labyrinth, and BridgeData~V2 robotic manipulation, the first large-scale robotic application of multi-intention IRL. Across all settings PRISM achieves the highest held-out log-likelihood while recovering nameable, temporally coherent intentions from unlabeled demonstrations, suggesting that discrete goal switching is present in both biological and artificial agents.
Beyond Self-Play and Scale: A Behavior Benchmark for Generalization in Autonomous Driving
May 11, 2026Recent Autonomous Driving (AD) works such as GigaFlow and PufferDrive have unlocked Reinforcement Learning (RL) at scale as a training strategy for driving policies. Yet such policies remain disconnected from established benchmarks, leaving the performance of large-scale RL for driving on standardized evaluations unknown. We present BehaviorBench -- a comprehensive test suite that closes this gap along three axes: Evaluation, Complexity, and Behavior Diversity. In terms of Evaluation, we provide an interface connecting PufferDrive to nuPlan, which, for the first time, enables policies trained via RL at scale to be evaluated on an established planning benchmark for autonomous driving. Complementarily, we offer an evaluation framework that allows planners to be benchmarked directly inside the PufferDrive simulation, at a fraction of the time. Regarding Complexity, we observe that today's standardized benchmarks are so simple that near-perfect scores are achievable by straight lane following with collision checking. We extract a meaningful, interaction-rich split from the Waymo Open Motion Dataset (WOMD) on which strong performance is impossible without multi-agent reasoning. Lastly, we address Behavior Diversity. Existing benchmarks commonly evaluate planners against a single rule-based traffic model, the Intelligent Driver Model (IDM). We provide a diverse suite of interactive traffic agents to stress-test policies under heterogeneous behaviors, beyond just using IDM. Overall, our benchmarking analysis uncovers the following insight: despite learning interactive behaviors in an emergent manner, policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors. Building on this observation, we propose a hybrid planner that combines a PPO policy with a rule-based planner.
Spectral Alignment in Forward-Backward Representations via Temporal Abstraction
Mar 23, 2026Forward-backward (FB) representations provide a powerful framework for learning the successor representation (SR) in continuous spaces by enforcing a low-rank factorization. However, a fundamental spectral mismatch often exists between the high-rank transition dynamics of continuous environments and the low-rank bottleneck of the FB architecture, making accurate low-rank representation learning difficult. In this work, we analyze temporal abstraction as a mechanism to mitigate this mismatch. By characterizing the spectral properties of the transition operator, we show that temporal abstraction acts as a low-pass filter that suppresses high-frequency spectral components. This suppression reduces the effective rank of the induced SR while preserving a formal bound on the resulting value function error. Empirically, we show that this alignment is a key factor for stable FB learning, particularly at high discount factors where bootstrapping becomes error-prone. Our results identify temporal abstraction as a principled mechanism for shaping the spectral structure of the underlying MDP and enabling effective long-horizon representations in continuous control.
Does TabPFN Understand Causal Structures?
Nov 10, 2025Causal discovery is fundamental for multiple scientific domains, yet extracting causal information from real world data remains a significant challenge. Given the recent success on real data, we investigate whether TabPFN, a transformer-based tabular foundation model pre-trained on synthetic datasets generated from structural causal models, encodes causal information in its internal representations. We develop an adapter framework using a learnable decoder and causal tokens that extract causal signals from TabPFN's frozen embeddings and decode them into adjacency matrices for causal discovery. Our evaluations demonstrate that TabPFN's embeddings contain causal information, outperforming several traditional causal discovery algorithms, with such causal information being concentrated in mid-range layers. These findings establish a new direction for interpretable and adaptable foundation models and demonstrate the potential for leveraging pre-trained tabular models for causal discovery.
Fitting Reinforcement Learning Model to Behavioral Data under Bandits
Nov 06, 2025
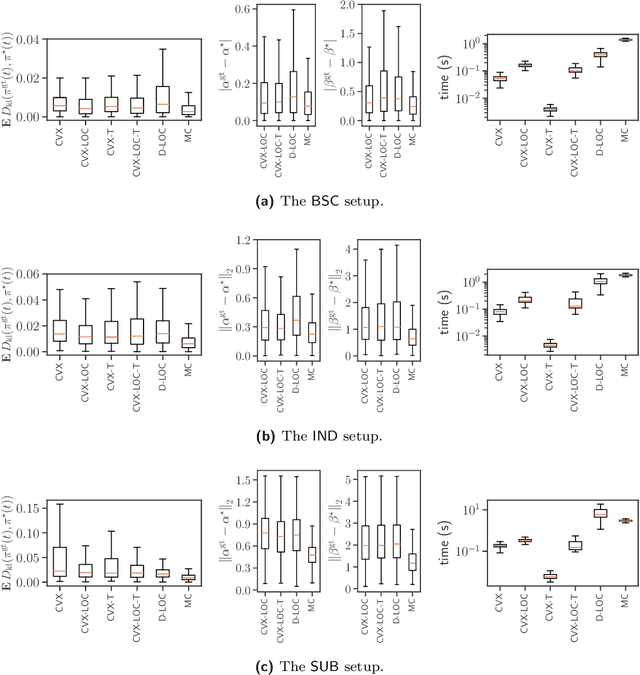

We consider the problem of fitting a reinforcement learning (RL) model to some given behavioral data under a multi-armed bandit environment. These models have received much attention in recent years for characterizing human and animal decision making behavior. We provide a generic mathematical optimization problem formulation for the fitting problem of a wide range of RL models that appear frequently in scientific research applications, followed by a detailed theoretical analysis of its convexity properties. Based on the theoretical results, we introduce a novel solution method for the fitting problem of RL models based on convex relaxation and optimization. Our method is then evaluated in several simulated bandit environments to compare with some benchmark methods that appear in the literature. Numerical results indicate that our method achieves comparable performance to the state-of-the-art, while significantly reducing computation time. We also provide an open-source Python package for our proposed method to empower researchers to apply it in the analysis of their datasets directly, without prior knowledge of convex optimization.
Fast ECoT: Efficient Embodied Chain-of-Thought via Thoughts Reuse
Jun 09, 2025Embodied Chain-of-Thought (ECoT) reasoning enhances vision-language-action (VLA) models by improving performance and interpretability through intermediate reasoning steps. However, its sequential autoregressive token generation introduces significant inference latency, limiting real-time deployment. We propose Fast ECoT, an inference-time acceleration method that exploits the structured and repetitive nature of ECoT to (1) cache and reuse high-level reasoning across timesteps and (2) parallelise the generation of modular reasoning steps. Additionally, we introduce an asynchronous scheduler that decouples reasoning from action decoding, further boosting responsiveness. Fast ECoT requires no model changes or additional training and integrates easily into existing VLA pipelines. Experiments in both simulation (LIBERO) and real-world robot tasks show up to a 7.5% reduction in latency with comparable or improved task success rate and reasoning faithfulness, bringing ECoT policies closer to practical real-time deployment.
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
May 06, 2025



We present Mixture of Discrete-time Gaussian Processes (MiDiGap), a novel approach for flexible policy representation and imitation learning in robot manipulation. MiDiGap enables learning from as few as five demonstrations using only camera observations and generalizes across a wide range of challenging tasks. It excels at long-horizon behaviors such as making coffee, highly constrained motions such as opening doors, dynamic actions such as scooping with a spatula, and multimodal tasks such as hanging a mug. MiDiGap learns these tasks on a CPU in less than a minute and scales linearly to large datasets. We also develop a rich suite of tools for inference-time steering using evidence such as collision signals and robot kinematic constraints. This steering enables novel generalization capabilities, including obstacle avoidance and cross-embodiment policy transfer. MiDiGap achieves state-of-the-art performance on diverse few-shot manipulation benchmarks. On constrained RLBench tasks, it improves policy success by 76 percentage points and reduces trajectory cost by 67%. On multimodal tasks, it improves policy success by 48 percentage points and increases sample efficiency by a factor of 20. In cross-embodiment transfer, it more than doubles policy success. We make the code publicly available at https://midigap.cs.uni-freiburg.de.
Multi-convex Programming for Discrete Latent Factor Models Prototyping
Apr 02, 2025Discrete latent factor models (DLFMs) are widely used in various domains such as machine learning, economics, neuroscience, psychology, etc. Currently, fitting a DLFM to some dataset relies on a customized solver for individual models, which requires lots of effort to implement and is limited to the targeted specific instance of DLFMs. In this paper, we propose a generic framework based on CVXPY, which allows users to specify and solve the fitting problem of a wide range of DLFMs, including both regression and classification models, within a very short script. Our framework is flexible and inherently supports the integration of regularization terms and constraints on the DLFM parameters and latent factors, such that the users can easily prototype the DLFM structure according to their dataset and application scenario. We introduce our open-source Python implementation and illustrate the framework in several examples.
Synthesis of Model Predictive Control and Reinforcement Learning: Survey and Classification
Feb 04, 2025



The fields of MPC and RL consider two successful control techniques for Markov decision processes. Both approaches are derived from similar fundamental principles, and both are widely used in practical applications, including robotics, process control, energy systems, and autonomous driving. Despite their similarities, MPC and RL follow distinct paradigms that emerged from diverse communities and different requirements. Various technical discrepancies, particularly the role of an environment model as part of the algorithm, lead to methodologies with nearly complementary advantages. Due to their orthogonal benefits, research interest in combination methods has recently increased significantly, leading to a large and growing set of complex ideas leveraging MPC and RL. This work illuminates the differences, similarities, and fundamentals that allow for different combination algorithms and categorizes existing work accordingly. Particularly, we focus on the versatile actor-critic RL approach as a basis for our categorization and examine how the online optimization approach of MPC can be used to improve the overall closed-loop performance of a policy.
Solving Inverse Problem for Multi-armed Bandits via Convex Optimization
Jan 31, 2025We consider the inverse problem of multi-armed bandits (IMAB) that are widely used in neuroscience and psychology research for behavior modelling. We first show that the IMAB problem is not convex in general, but can be relaxed to a convex problem via variable transformation. Based on this result, we propose a two-step sequential heuristic for (approximately) solving the IMAB problem. We discuss a condition where our method provides global solution to the IMAB problem with certificate, as well as approximations to further save computing time. Numerical experiments indicate that our heuristic method is more robust than directly solving the IMAB problem via repeated local optimization, and can achieve the performance of Monte Carlo methods within a significantly decreased running time. We provide the implementation of our method based on CVXPY, which allows straightforward application by users not well versed in convex optimization.