 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
May 06, 2025We present Mixture of Discrete-time Gaussian Processes (MiDiGap), a novel approach for flexible policy representation and imitation learning in robot manipulation. MiDiGap enables learning from as few as five demonstrations using only camera observations and generalizes across a wide range of challenging tasks. It excels at long-horizon behaviors such as making coffee, highly constrained motions such as opening doors, dynamic actions such as scooping with a spatula, and multimodal tasks such as hanging a mug. MiDiGap learns these tasks on a CPU in less than a minute and scales linearly to large datasets. We also develop a rich suite of tools for inference-time steering using evidence such as collision signals and robot kinematic constraints. This steering enables novel generalization capabilities, including obstacle avoidance and cross-embodiment policy transfer. MiDiGap achieves state-of-the-art performance on diverse few-shot manipulation benchmarks. On constrained RLBench tasks, it improves policy success by 76 percentage points and reduces trajectory cost by 67%. On multimodal tasks, it improves policy success by 48 percentage points and increases sample efficiency by a factor of 20. In cross-embodiment transfer, it more than doubles policy success. We make the code publicly available at https://midigap.cs.uni-freiburg.de.
Robotic Task Ambiguity Resolution via Natural Language Interaction
Apr 24, 2025



Language-conditioned policies have recently gained substantial adoption in robotics as they allow users to specify tasks using natural language, making them highly versatile. While much research has focused on improving the action prediction of language-conditioned policies, reasoning about task descriptions has been largely overlooked. Ambiguous task descriptions often lead to downstream policy failures due to misinterpretation by the robotic agent. To address this challenge, we introduce AmbResVLM, a novel method that grounds language goals in the observed scene and explicitly reasons about task ambiguity. We extensively evaluate its effectiveness in both simulated and real-world domains, demonstrating superior task ambiguity detection and resolution compared to recent state-of-the-art baselines. Finally, real robot experiments show that our model improves the performance of downstream robot policies, increasing the average success rate from 69.6% to 97.1%. We make the data, code, and trained models publicly available at https://ambres.cs.uni-freiburg.de.
The Art of Imitation: Learning Long-Horizon Manipulation Tasks from Few Demonstrations
Jul 18, 2024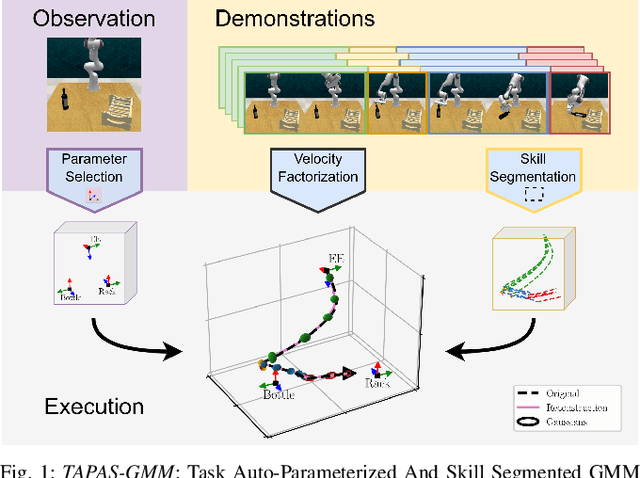
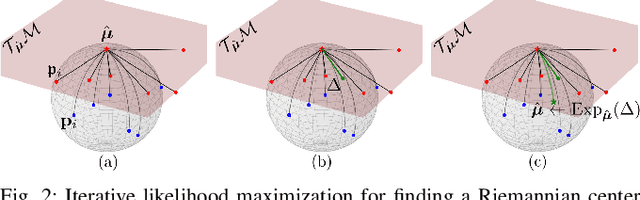
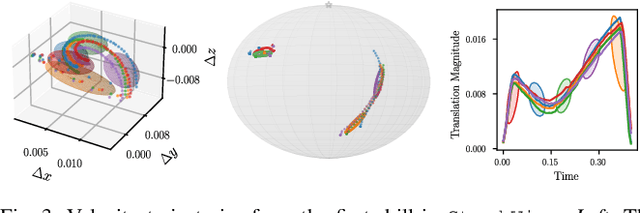
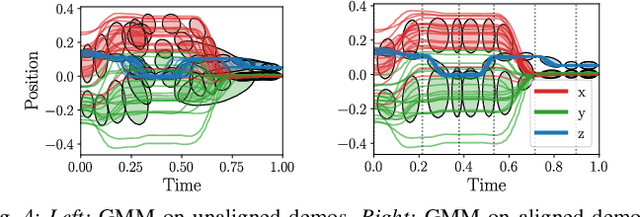
Task Parametrized Gaussian Mixture Models (TP-GMM) are a sample-efficient method for learning object-centric robot manipulation tasks. However, there are several open challenges to applying TP-GMMs in the wild. In this work, we tackle three crucial challenges synergistically. First, end-effector velocities are non-Euclidean and thus hard to model using standard GMMs. We thus propose to factorize the robot's end-effector velocity into its direction and magnitude, and model them using Riemannian GMMs. Second, we leverage the factorized velocities to segment and sequence skills from complex demonstration trajectories. Through the segmentation, we further align skill trajectories and hence leverage time as a powerful inductive bias. Third, we present a method to automatically detect relevant task parameters per skill from visual observations. Our approach enables learning complex manipulation tasks from just five demonstrations while using only RGB-D observations. Extensive experimental evaluations on RLBench demonstrate that our approach achieves state-of-the-art performance with 20-fold improved sample efficiency. Our policies generalize across different environments, object instances, and object positions, while the learned skills are reusable.
The Treachery of Images: Bayesian Scene Keypoints for Deep Policy Learning in Robotic Manipulation
May 08, 2023In policy learning for robotic manipulation, sample efficiency is of paramount importance. Thus, learning and extracting more compact representations from camera observations is a promising avenue. However, current methods often assume full observability of the scene and struggle with scale invariance. In many tasks and settings, this assumption does not hold as objects in the scene are often occluded or lie outside the field of view of the camera, rendering the camera observation ambiguous with regard to their location. To tackle this problem, we present BASK, a Bayesian approach to tracking scale-invariant keypoints over time. Our approach successfully resolves inherent ambiguities in images, enabling keypoint tracking on symmetrical objects and occluded and out-of-view objects. We employ our method to learn challenging multi-object robot manipulation tasks from wrist camera observations and demonstrate superior utility for policy learning compared to other representation learning techniques. Furthermore, we show outstanding robustness towards disturbances such as clutter, occlusions, and noisy depth measurements, as well as generalization to unseen objects both in simulation and real-world robotic experiments.
Self-Supervised Learning of Multi-Object Keypoints for Robotic Manipulation
May 17, 2022
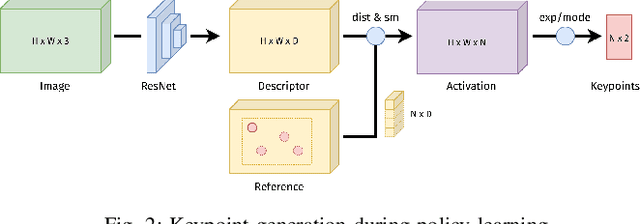

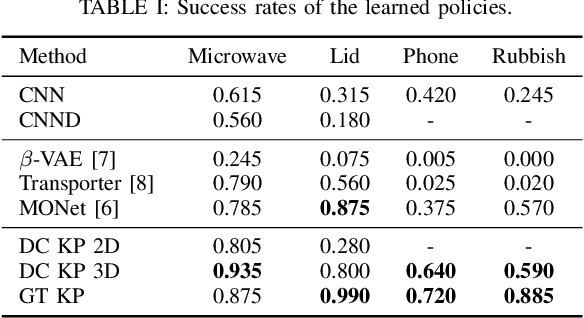
In recent years, policy learning methods using either reinforcement or imitation have made significant progress. However, both techniques still suffer from being computationally expensive and requiring large amounts of training data. This problem is especially prevalent in real-world robotic manipulation tasks, where access to ground truth scene features is not available and policies are instead learned from raw camera observations. In this paper, we demonstrate the efficacy of learning image keypoints via the Dense Correspondence pretext task for downstream policy learning. Extending prior work to challenging multi-object scenes, we show that our model can be trained to deal with important problems in representation learning, primarily scale-invariance and occlusion. We evaluate our approach on diverse robot manipulation tasks, compare it to other visual representation learning approaches, and demonstrate its flexibility and effectiveness for sample-efficient policy learning.