 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Task Ambiguity Resolution via Natural Language Interaction
Apr 24, 2025



Language-conditioned policies have recently gained substantial adoption in robotics as they allow users to specify tasks using natural language, making them highly versatile. While much research has focused on improving the action prediction of language-conditioned policies, reasoning about task descriptions has been largely overlooked. Ambiguous task descriptions often lead to downstream policy failures due to misinterpretation by the robotic agent. To address this challenge, we introduce AmbResVLM, a novel method that grounds language goals in the observed scene and explicitly reasons about task ambiguity. We extensively evaluate its effectiveness in both simulated and real-world domains, demonstrating superior task ambiguity detection and resolution compared to recent state-of-the-art baselines. Finally, real robot experiments show that our model improves the performance of downstream robot policies, increasing the average success rate from 69.6% to 97.1%. We make the data, code, and trained models publicly available at https://ambres.cs.uni-freiburg.de.
Learning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
Sep 11, 2024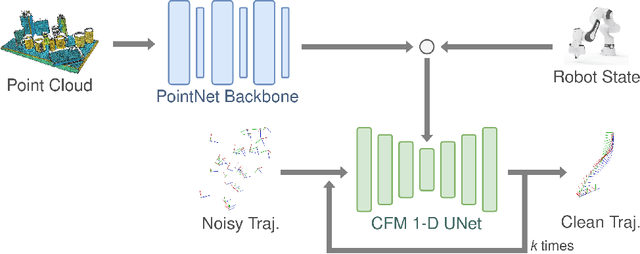



Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.
CenterArt: Joint Shape Reconstruction and 6-DoF Grasp Estimation of Articulated Objects
Apr 23, 2024


Precisely grasping and reconstructing articulated objects is key to enabling general robotic manipulation. In this paper, we propose CenterArt, a novel approach for simultaneous 3D shape reconstruction and 6-DoF grasp estimation of articulated objects. CenterArt takes RGB-D images of the scene as input and first predicts the shape and joint codes through an encoder. The decoder then leverages these codes to reconstruct 3D shapes and estimate 6-DoF grasp poses of the objects. We further develop a mechanism for generating a dataset of 6-DoF grasp ground truth poses for articulated objects. CenterArt is trained on realistic scenes containing multiple articulated objects with randomized designs, textures, lighting conditions, and realistic depths. We perform extensive experiments demonstrating that CenterArt outperforms existing methods in accuracy and robustness.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024



Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.
CenterGrasp: Object-Aware Implicit Representation Learning for Simultaneous Shape Reconstruction and 6-DoF Grasp Estimation
Dec 13, 2023Reliable object grasping is a crucial capability for autonomous robots. However, many existing grasping approaches focus on general clutter removal without explicitly modeling objects and thus only relying on the visible local geometry. We introduce CenterGrasp, a novel framework that combines object awareness and holistic grasping. CenterGrasp learns a general object prior by encoding shapes and valid grasps in a continuous latent space. It consists of an RGB-D image encoder that leverages recent advances to detect objects and infer their pose and latent code, and a decoder to predict shape and grasps for each object in the scene. We perform extensive experiments on simulated as well as real-world cluttered scenes and demonstrate strong scene reconstruction and 6-DoF grasp-pose estimation performance. Compared to the state of the art, CenterGrasp achieves an improvement of 38.5 mm in shape reconstruction and 33 percentage points on average in grasp success. We make the code and trained models publicly available at http://centergrasp.cs.uni-freiburg.de.
The Treachery of Images: Bayesian Scene Keypoints for Deep Policy Learning in Robotic Manipulation
May 08, 2023In policy learning for robotic manipulation, sample efficiency is of paramount importance. Thus, learning and extracting more compact representations from camera observations is a promising avenue. However, current methods often assume full observability of the scene and struggle with scale invariance. In many tasks and settings, this assumption does not hold as objects in the scene are often occluded or lie outside the field of view of the camera, rendering the camera observation ambiguous with regard to their location. To tackle this problem, we present BASK, a Bayesian approach to tracking scale-invariant keypoints over time. Our approach successfully resolves inherent ambiguities in images, enabling keypoint tracking on symmetrical objects and occluded and out-of-view objects. We employ our method to learn challenging multi-object robot manipulation tasks from wrist camera observations and demonstrate superior utility for policy learning compared to other representation learning techniques. Furthermore, we show outstanding robustness towards disturbances such as clutter, occlusions, and noisy depth measurements, as well as generalization to unseen objects both in simulation and real-world robotic experiments.
Interactive Imitation Learning in Robotics: A Survey
Oct 31, 2022



Interactive Imitation Learning (IIL) is a branch of Imitation Learning (IL) where human feedback is provided intermittently during robot execution allowing an online improvement of the robot's behavior. In recent years, IIL has increasingly started to carve out its own space as a promising data-driven alternative for solving complex robotic tasks. The advantages of IIL are its data-efficient, as the human feedback guides the robot directly towards an improved behavior, and its robustness, as the distribution mismatch between the teacher and learner trajectories is minimized by providing feedback directly over the learner's trajectories. Nevertheless, despite the opportunities that IIL presents, its terminology, structure, and applicability are not clear nor unified in the literature, slowing down its development and, therefore, the research of innovative formulations and discoveries. In this article, we attempt to facilitate research in IIL and lower entry barriers for new practitioners by providing a survey of the field that unifies and structures it. In addition, we aim to raise awareness of its potential, what has been accomplished and what are still open research questions. We organize the most relevant works in IIL in terms of human-robot interaction (i.e., types of feedback), interfaces (i.e., means of providing feedback), learning (i.e., models learned from feedback and function approximators), user experience (i.e., human perception about the learning process), applications, and benchmarks. Furthermore, we analyze similarities and differences between IIL and RL, providing a discussion on how the concepts offline, online, off-policy and on-policy learning should be transferred to IIL from the RL literature. We particularly focus on robotic applications in the real world and discuss their implications, limitations, and promising future areas of research.
Self-Supervised Learning of Multi-Object Keypoints for Robotic Manipulation
May 17, 2022
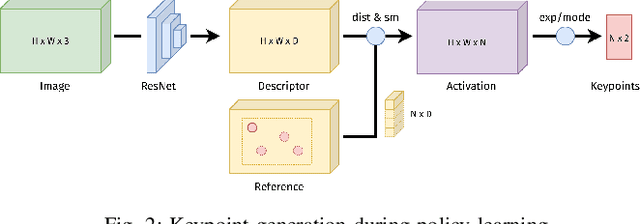

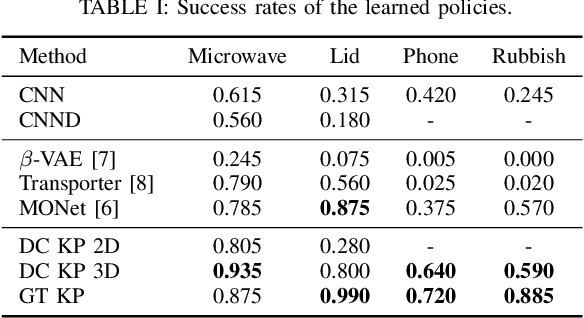
In recent years, policy learning methods using either reinforcement or imitation have made significant progress. However, both techniques still suffer from being computationally expensive and requiring large amounts of training data. This problem is especially prevalent in real-world robotic manipulation tasks, where access to ground truth scene features is not available and policies are instead learned from raw camera observations. In this paper, we demonstrate the efficacy of learning image keypoints via the Dense Correspondence pretext task for downstream policy learning. Extending prior work to challenging multi-object scenes, we show that our model can be trained to deal with important problems in representation learning, primarily scale-invariance and occlusion. We evaluate our approach on diverse robot manipulation tasks, compare it to other visual representation learning approaches, and demonstrate its flexibility and effectiveness for sample-efficient policy learning.
Correct Me if I am Wrong: Interactive Learning for Robotic Manipulation
Oct 07, 2021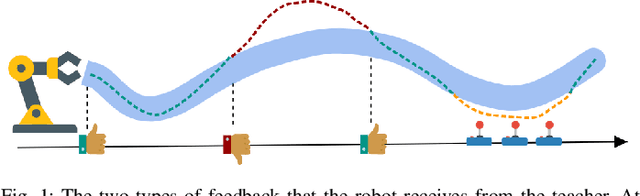
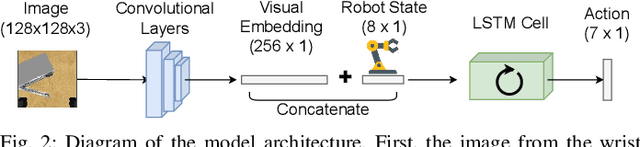

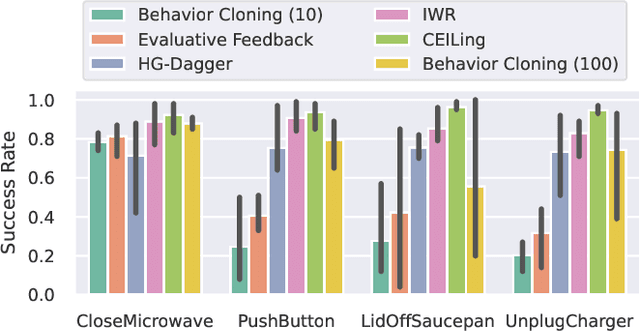
Learning to solve complex manipulation tasks from visual observations is a dominant challenge for real-world robot learning. Deep reinforcement learning algorithms have recently demonstrated impressive results, although they still require an impractical amount of time-consuming trial-and-error iterations. In this work, we consider the promising alternative paradigm of interactive learning where a human teacher provides feedback to the policy during execution, as opposed to imitation learning where a pre-collected dataset of perfect demonstrations is used. Our proposed CEILing (Corrective and Evaluative Interactive Learning) framework combines both corrective and evaluative feedback from the teacher to train a stochastic policy in an asynchronous manner, and employs a dedicated mechanism to trade off human corrections with the robot's own experience. We present results obtained with our framework in extensive simulation and real-world experiments that demonstrate that CEILing can effectively solve complex robot manipulation tasks directly from raw images in less than one hour of real-world training.
Learning from Simulation, Racing in Reality
Nov 26, 2020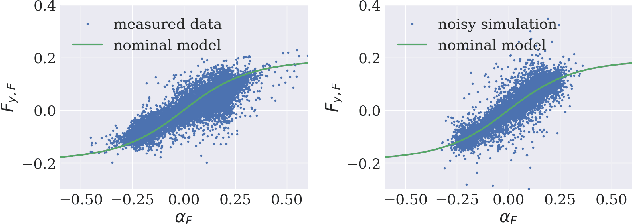
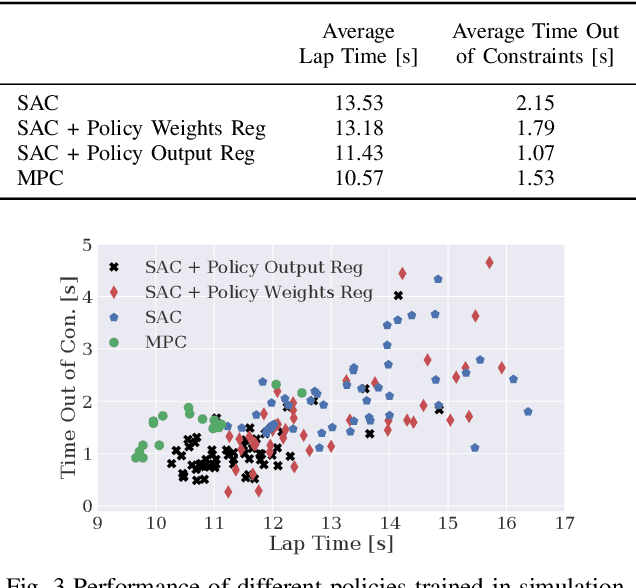

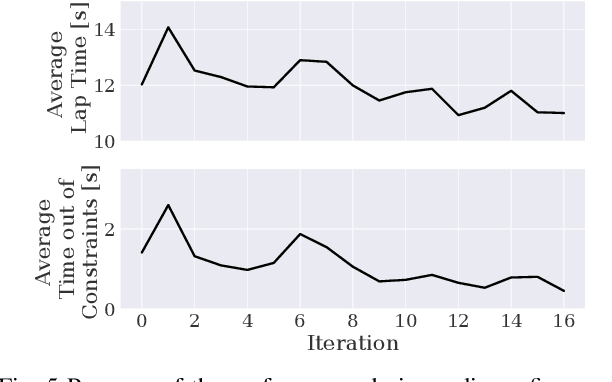
We present a reinforcement learning-based solution to autonomously race on a miniature race car platform. We show that a policy that is trained purely in simulation using a relatively simple vehicle model, including model randomization, can be successfully transferred to the real robotic setup. We achieve this by using novel policy output regularization approach and a lifted action space which enables smooth actions but still aggressive race car driving. We show that this regularized policy does outperform the Soft Actor Critic (SAC) baseline method, both in simulation and on the real car, but it is still outperformed by a Model Predictive Controller (MPC) state of the art method. The refinement of the policy with three hours of real-world interaction data allows the reinforcement learning policy to achieve lap times similar to the MPC controller while reducing track constraint violations by 50%.