 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Imitation Learning in Robotics: A Survey
Oct 31, 2022



Interactive Imitation Learning (IIL) is a branch of Imitation Learning (IL) where human feedback is provided intermittently during robot execution allowing an online improvement of the robot's behavior. In recent years, IIL has increasingly started to carve out its own space as a promising data-driven alternative for solving complex robotic tasks. The advantages of IIL are its data-efficient, as the human feedback guides the robot directly towards an improved behavior, and its robustness, as the distribution mismatch between the teacher and learner trajectories is minimized by providing feedback directly over the learner's trajectories. Nevertheless, despite the opportunities that IIL presents, its terminology, structure, and applicability are not clear nor unified in the literature, slowing down its development and, therefore, the research of innovative formulations and discoveries. In this article, we attempt to facilitate research in IIL and lower entry barriers for new practitioners by providing a survey of the field that unifies and structures it. In addition, we aim to raise awareness of its potential, what has been accomplished and what are still open research questions. We organize the most relevant works in IIL in terms of human-robot interaction (i.e., types of feedback), interfaces (i.e., means of providing feedback), learning (i.e., models learned from feedback and function approximators), user experience (i.e., human perception about the learning process), applications, and benchmarks. Furthermore, we analyze similarities and differences between IIL and RL, providing a discussion on how the concepts offline, online, off-policy and on-policy learning should be transferred to IIL from the RL literature. We particularly focus on robotic applications in the real world and discuss their implications, limitations, and promising future areas of research.
Interactive Imitation Learning in State-Space
Aug 02, 2020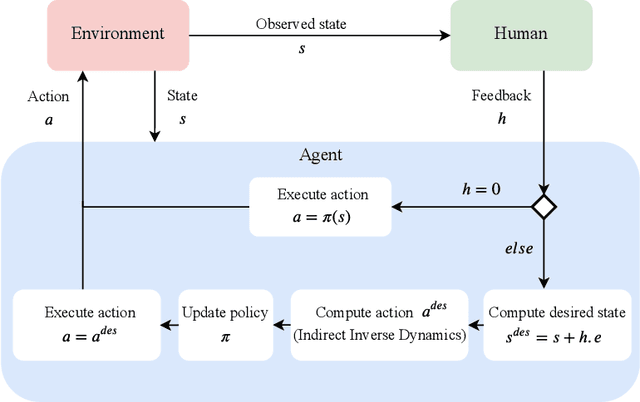
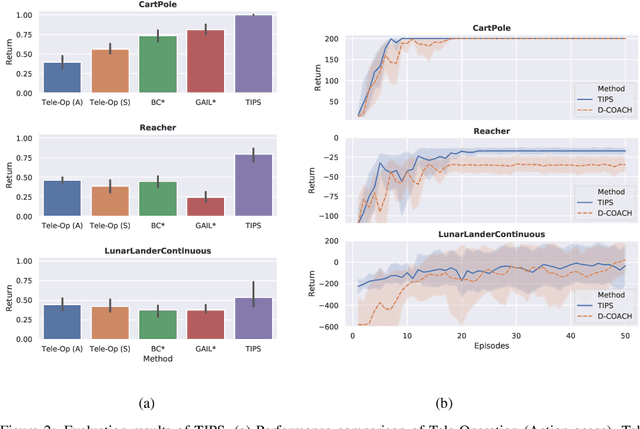
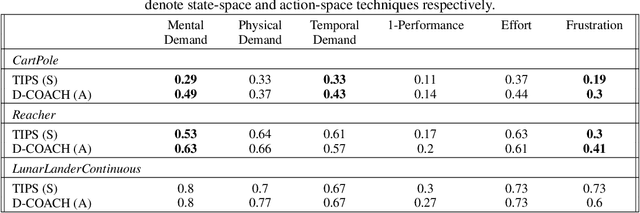
Imitation Learning techniques enable programming the behavior of agents through demonstrations rather than manual engineering. However, they are limited by the quality of available demonstration data. Interactive Imitation Learning techniques can improve the efficacy of learning since they involve teachers providing feedback while the agent executes its task. In this work, we propose a novel Interactive Learning technique that uses human feedback in state-space to train and improve agent behavior (as opposed to alternative methods that use feedback in action-space). Our method titled Teaching Imitative Policies in State-space~(TIPS) enables providing guidance to the agent in terms of `changing its state' which is often more intuitive for a human demonstrator. Through continuous improvement via corrective feedback, agents trained by non-expert demonstrators using TIPS outperformed the demonstrator and conventional Imitation Learning agents.
Continuous Control for High-Dimensional State Spaces: An Interactive Learning Approach
Aug 14, 2019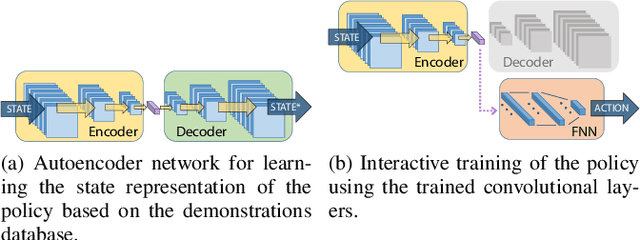
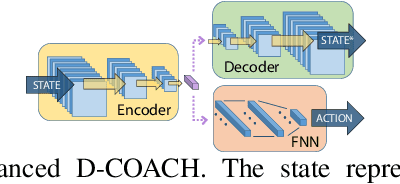

Deep Reinforcement Learning (DRL) has become a powerful methodology to solve complex decision-making problems. However, DRL has several limitations when used in real-world problems (e.g., robotics applications). For instance, long training times are required and cannot be accelerated in contrast to simulated environments, and reward functions may be hard to specify/model and/or to compute. Moreover, the transfer of policies learned in a simulator to the real-world has limitations (reality gap). On the other hand, machine learning methods that rely on the transfer of human knowledge to an agent have shown to be time efficient for obtaining well performing policies and do not require a reward function. In this context, we analyze the use of human corrective feedback during task execution to learn policies with high-dimensional state spaces, by using the D-COACH framework, and we propose new variants of this framework. D-COACH is a Deep Learning based extension of COACH (COrrective Advice Communicated by Humans), where humans are able to shape policies through corrective advice. The enhanced version of D-COACH, which is proposed in this paper, largely reduces the time and effort of a human for training a policy. Experimental results validate the efficiency of the D-COACH framework in three different problems (simulated and with real robots), and show that its enhanced version reduces the human training effort considerably, and makes it feasible to learn policies within periods of time in which a DRL agent do not reach any improvement.
Deep Reinforcement Learning with Feedback-based Exploration
Mar 14, 2019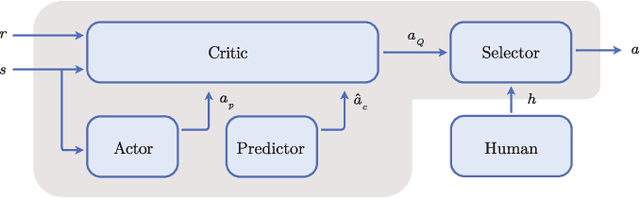
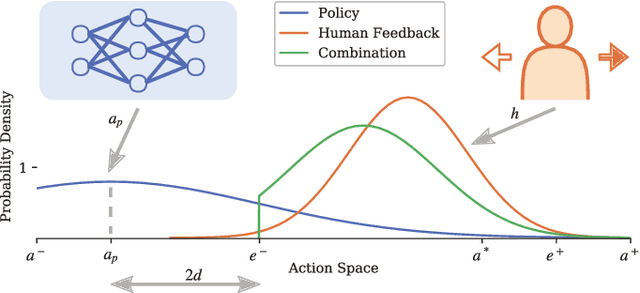

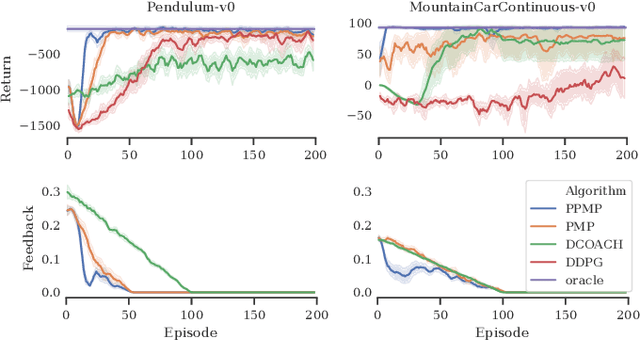
Deep Reinforcement Learning has enabled the control of increasingly complex and high-dimensional problems. However, the need of vast amounts of data before reasonable performance is attained prevents its widespread application. We employ binary corrective feedback as a general and intuitive manner to incorporate human intuition and domain knowledge in model-free machine learning. The uncertainty in the policy and the corrective feedback is combined directly in the action space as probabilistic conditional exploration. As a result, the greatest part of the otherwise ignorant learning process can be avoided. We demonstrate the proposed method, Predictive Probabilistic Merging of Policies (PPMP), in combination with DDPG. In experiments on continuous control problems of the OpenAI Gym, we achieve drastic improvements in sample efficiency, final performance, and robustness to erroneous feedback, both for human and synthetic feedback. Additionally, we show solutions beyond the demonstrated knowledge.
Learning Gaussian Policies from Corrective Human Feedback
Mar 12, 2019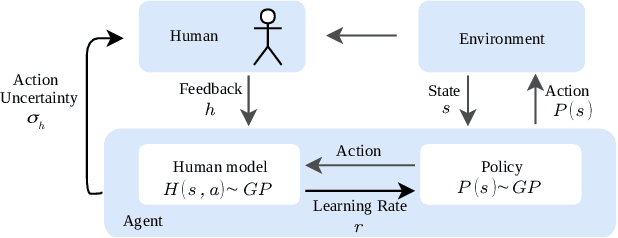

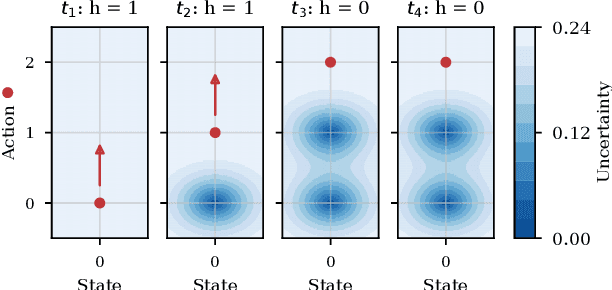
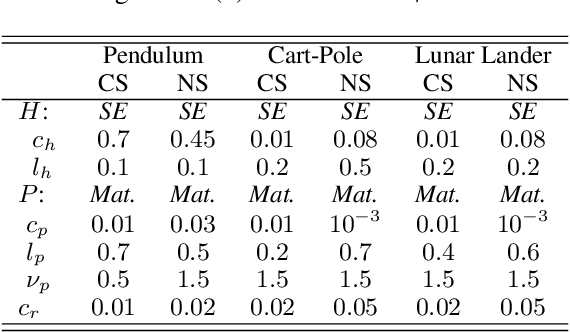
Learning from human feedback is a viable alternative to control design that does not require modelling or control expertise. Particularly, learning from corrective advice garners advantages over evaluative feedback as it is a more intuitive and scalable format. The current state-of-the-art in this field, COACH, has proven to be a effective approach for confined problems. However, it parameterizes the policy with Radial Basis Function networks, which require meticulous feature space engineering for higher order systems. We introduce Gaussian Process Coach (GPC), where feature space engineering is avoided by employing Gaussian Processes. In addition, we use the available policy uncertainty to 1) inquire feedback samples of maximal utility and 2) to adapt the learning rate to the teacher's learning phase. We demonstrate that the novel algorithm outperforms the current state-of-the-art in final performance, convergence rate and robustness to erroneous feedback in OpenAI Gym continuous control benchmarks, both for simulated and real human teachers.
Interactive Learning with Corrective Feedback for Policies based on Deep Neural Networks
Sep 30, 2018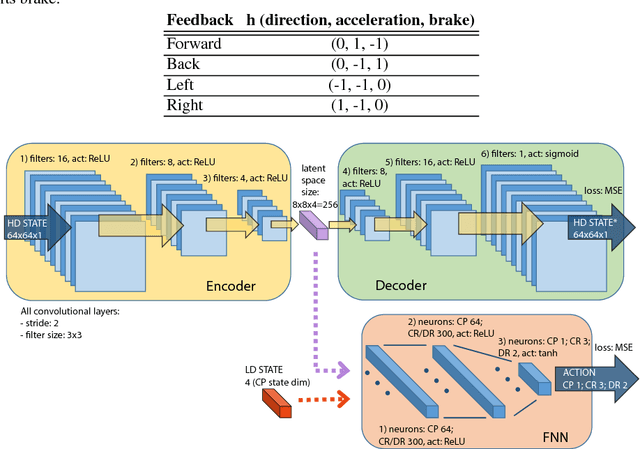
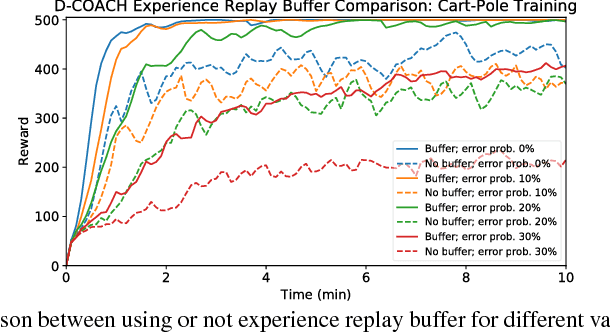
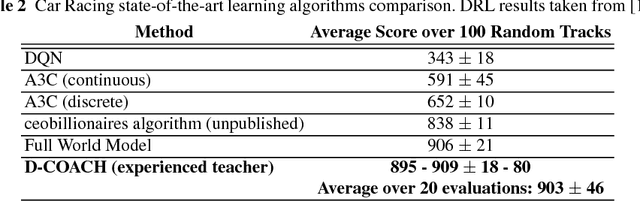
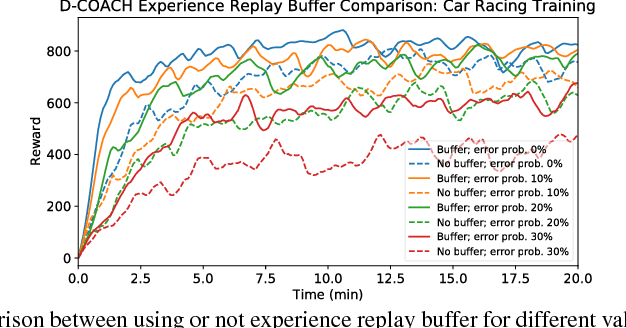
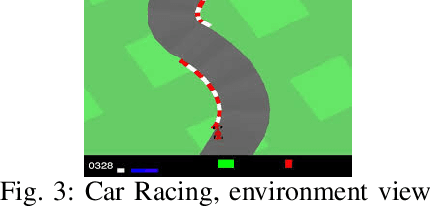
Deep Reinforcement Learning (DRL) has become a powerful strategy to solve complex decision making problems based on Deep Neural Networks (DNNs). However, it is highly data demanding, so unfeasible in physical systems for most applications. In this work, we approach an alternative Interactive Machine Learning (IML) strategy for training DNN policies based on human corrective feedback, with a method called Deep COACH (D-COACH). This approach not only takes advantage of the knowledge and insights of human teachers as well as the power of DNNs, but also has no need of a reward function (which sometimes implies the need of external perception for computing rewards). We combine Deep Learning with the COrrective Advice Communicated by Humans (COACH) framework, in which non-expert humans shape policies by correcting the agent's actions during execution. The D-COACH framework has the potential to solve complex problems without much data or time required. Experimental results validated the efficiency of the framework in three different problems (two simulated, one with a real robot), with state spaces of low and high dimensions, showing the capacity to successfully learn policies for continuous action spaces like in the Car Racing and Cart-Pole problems faster than with DRL.