 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Feedback-based Exploration
Mar 14, 2019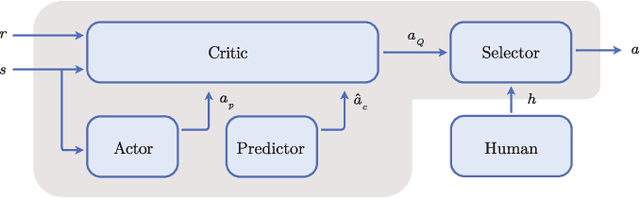
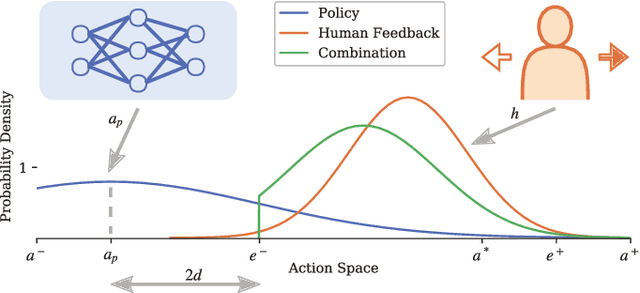

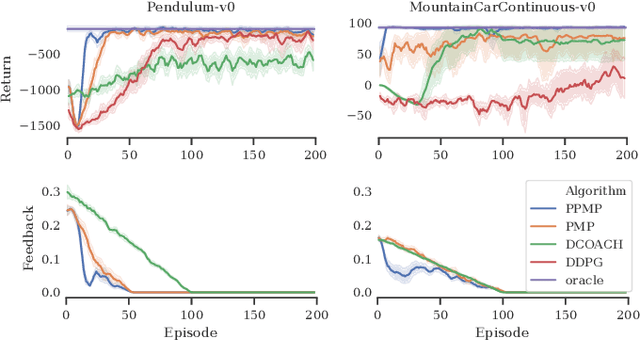
Deep Reinforcement Learning has enabled the control of increasingly complex and high-dimensional problems. However, the need of vast amounts of data before reasonable performance is attained prevents its widespread application. We employ binary corrective feedback as a general and intuitive manner to incorporate human intuition and domain knowledge in model-free machine learning. The uncertainty in the policy and the corrective feedback is combined directly in the action space as probabilistic conditional exploration. As a result, the greatest part of the otherwise ignorant learning process can be avoided. We demonstrate the proposed method, Predictive Probabilistic Merging of Policies (PPMP), in combination with DDPG. In experiments on continuous control problems of the OpenAI Gym, we achieve drastic improvements in sample efficiency, final performance, and robustness to erroneous feedback, both for human and synthetic feedback. Additionally, we show solutions beyond the demonstrated knowledge.
Learning Gaussian Policies from Corrective Human Feedback
Mar 12, 2019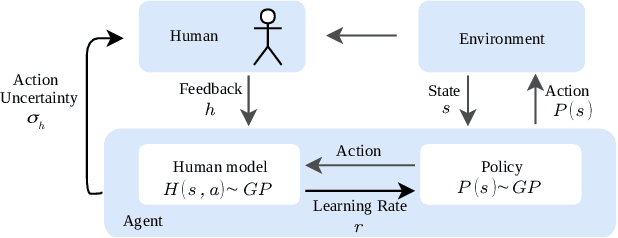

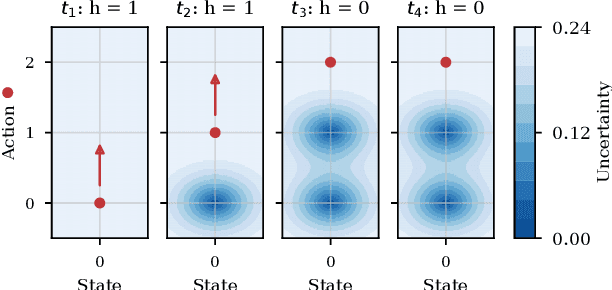
Learning from human feedback is a viable alternative to control design that does not require modelling or control expertise. Particularly, learning from corrective advice garners advantages over evaluative feedback as it is a more intuitive and scalable format. The current state-of-the-art in this field, COACH, has proven to be a effective approach for confined problems. However, it parameterizes the policy with Radial Basis Function networks, which require meticulous feature space engineering for higher order systems. We introduce Gaussian Process Coach (GPC), where feature space engineering is avoided by employing Gaussian Processes. In addition, we use the available policy uncertainty to 1) inquire feedback samples of maximal utility and 2) to adapt the learning rate to the teacher's learning phase. We demonstrate that the novel algorithm outperforms the current state-of-the-art in final performance, convergence rate and robustness to erroneous feedback in OpenAI Gym continuous control benchmarks, both for simulated and real human teachers.