 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Behavior Cloning: Robustness through Interactive Imitation and Contrastive Learning
Feb 11, 2025Behavior cloning (BC) traditionally relies on demonstration data, assuming the demonstrated actions are optimal. This can lead to overfitting under noisy data, particularly when expressive models are used (e.g., the energy-based model in Implicit BC). To address this, we extend behavior cloning into an iterative process of optimal action estimation within the Interactive Imitation Learning framework. Specifically, we introduce Contrastive policy Learning from Interactive Corrections (CLIC). CLIC leverages human corrections to estimate a set of desired actions and optimizes the policy to select actions from this set. We provide theoretical guarantees for the convergence of the desired action set to optimal actions in both single and multiple optimal action cases. Extensive simulation and real-robot experiments validate CLIC's advantages over existing state-of-the-art methods, including stable training of energy-based models, robustness to feedback noise, and adaptability to diverse feedback types beyond demonstrations. Our code will be publicly available soon.
Leveraging LLMs, Graphs and Object Hierarchies for Task Planning in Large-Scale Environments
Sep 10, 2024



Planning methods struggle with computational intractability in solving task-level problems in large-scale environments. This work explores leveraging the commonsense knowledge encoded in LLMs to empower planning techniques to deal with these complex scenarios. We achieve this by efficiently using LLMs to prune irrelevant components from the planning problem's state space, substantially simplifying its complexity. We demonstrate the efficacy of this system through extensive experiments within a household simulation environment, alongside real-world validation using a 7-DoF manipulator (video https://youtu.be/6ro2UOtOQS4).
Deep Metric Imitation Learning for Stable Motion Primitives
Oct 19, 2023Imitation Learning (IL) is a powerful technique for intuitive robotic programming. However, ensuring the reliability of learned behaviors remains a challenge. In the context of reaching motions, a robot should consistently reach its goal, regardless of its initial conditions. To meet this requirement, IL methods often employ specialized function approximators that guarantee this property by construction. Although effective, these approaches come with a set of limitations: 1) they are unable to fully exploit the capabilities of modern Deep Neural Network (DNN) architectures, 2) some are restricted in the family of motions they can model, resulting in suboptimal IL capabilities, and 3) they require explicit extensions to account for the geometry of motions that consider orientations. To address these challenges, we introduce a novel stability loss function, drawing inspiration from the triplet loss used in the deep metric learning literature. This loss does not constrain the DNN's architecture and enables learning policies that yield accurate results. Furthermore, it is easily adaptable to the geometry of the robot's state space. We provide a proof of the stability properties induced by this loss and empirically validate our method in various settings. These settings include Euclidean and non-Euclidean state spaces, as well as first-order and second-order motions, both in simulation and with real robots. More details about the experimental results can be found at: https://youtu.be/ZWKLGntCI6w.
Robotic Packaging Optimization with Reinforcement Learning
Mar 26, 2023



Intelligent manufacturing is becoming increasingly important due to the growing demand for maximizing productivity and flexibility while minimizing waste and lead times. This work investigates automated secondary robotic food packaging solutions that transfer food products from the conveyor belt into containers. A major problem in these solutions is varying product supply which can cause drastic productivity drops. Conventional rule-based approaches, used to address this issue, are often inadequate, leading to violation of the industry's requirements. Reinforcement learning, on the other hand, has the potential of solving this problem by learning responsive and predictive policy, based on experience. However, it is challenging to utilize it in highly complex control schemes. In this paper, we propose a reinforcement learning framework, designed to optimize the conveyor belt speed while minimizing interference with the rest of the control system. When tested on real-world data, the framework exceeds the performance requirements (99.8% packed products) and maintains quality (100% filled boxes). Compared to the existing solution, our proposed framework improves productivity, has smoother control, and reduces computation time.
Stable Motion Primitives via Imitation and Contrastive Learning
Feb 20, 2023Learning from humans allows non-experts to program robots with ease, lowering the resources required to build complex robotic solutions. Nevertheless, such data-driven approaches often lack the ability of providing guarantees regarding their learned behaviors, which is critical for avoiding failures and/or accidents. In this work, we focus on reaching/point-to-point motions, where robots must always reach their goal, independently of their initial state. This can be achieved by modeling motions as dynamical systems and ensuring that they are globally asymptotically stable. Hence, we introduce a novel Contrastive Learning loss for training Deep Neural Networks (DNN) that, when used together with an Imitation Learning loss, enforces the aforementioned stability in the learned motions. Differently from previous work, our method does not restrict the structure of its function approximator, enabling its use with arbitrary DNNs and allowing it to learn complex motions with high accuracy. We validate it using datasets and a real robot. In the former case, motions are 2 and 4 dimensional, modeled as first and second order dynamical systems. In the latter, motions are 3, 4, and 6 dimensional, of first and second order, and are used to control a 7DoF robot manipulator in its end effector space and joint space. More details regarding the real-world experiments are presented in: https://youtu.be/OM-2edHBRfc.
Interactive Imitation Learning in Robotics: A Survey
Oct 31, 2022



Interactive Imitation Learning (IIL) is a branch of Imitation Learning (IL) where human feedback is provided intermittently during robot execution allowing an online improvement of the robot's behavior. In recent years, IIL has increasingly started to carve out its own space as a promising data-driven alternative for solving complex robotic tasks. The advantages of IIL are its data-efficient, as the human feedback guides the robot directly towards an improved behavior, and its robustness, as the distribution mismatch between the teacher and learner trajectories is minimized by providing feedback directly over the learner's trajectories. Nevertheless, despite the opportunities that IIL presents, its terminology, structure, and applicability are not clear nor unified in the literature, slowing down its development and, therefore, the research of innovative formulations and discoveries. In this article, we attempt to facilitate research in IIL and lower entry barriers for new practitioners by providing a survey of the field that unifies and structures it. In addition, we aim to raise awareness of its potential, what has been accomplished and what are still open research questions. We organize the most relevant works in IIL in terms of human-robot interaction (i.e., types of feedback), interfaces (i.e., means of providing feedback), learning (i.e., models learned from feedback and function approximators), user experience (i.e., human perception about the learning process), applications, and benchmarks. Furthermore, we analyze similarities and differences between IIL and RL, providing a discussion on how the concepts offline, online, off-policy and on-policy learning should be transferred to IIL from the RL literature. We particularly focus on robotic applications in the real world and discuss their implications, limitations, and promising future areas of research.
Continuous Control for High-Dimensional State Spaces: An Interactive Learning Approach
Aug 14, 2019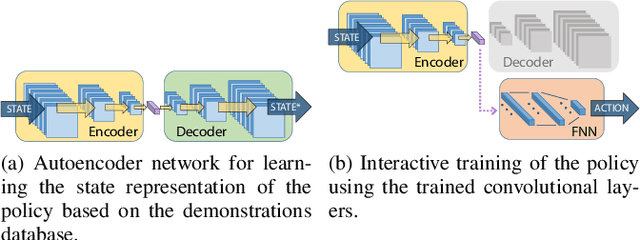
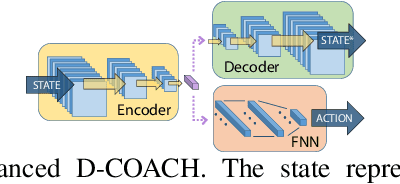

Deep Reinforcement Learning (DRL) has become a powerful methodology to solve complex decision-making problems. However, DRL has several limitations when used in real-world problems (e.g., robotics applications). For instance, long training times are required and cannot be accelerated in contrast to simulated environments, and reward functions may be hard to specify/model and/or to compute. Moreover, the transfer of policies learned in a simulator to the real-world has limitations (reality gap). On the other hand, machine learning methods that rely on the transfer of human knowledge to an agent have shown to be time efficient for obtaining well performing policies and do not require a reward function. In this context, we analyze the use of human corrective feedback during task execution to learn policies with high-dimensional state spaces, by using the D-COACH framework, and we propose new variants of this framework. D-COACH is a Deep Learning based extension of COACH (COrrective Advice Communicated by Humans), where humans are able to shape policies through corrective advice. The enhanced version of D-COACH, which is proposed in this paper, largely reduces the time and effort of a human for training a policy. Experimental results validate the efficiency of the D-COACH framework in three different problems (simulated and with real robots), and show that its enhanced version reduces the human training effort considerably, and makes it feasible to learn policies within periods of time in which a DRL agent do not reach any improvement.
Interactive Learning with Corrective Feedback for Policies based on Deep Neural Networks
Sep 30, 2018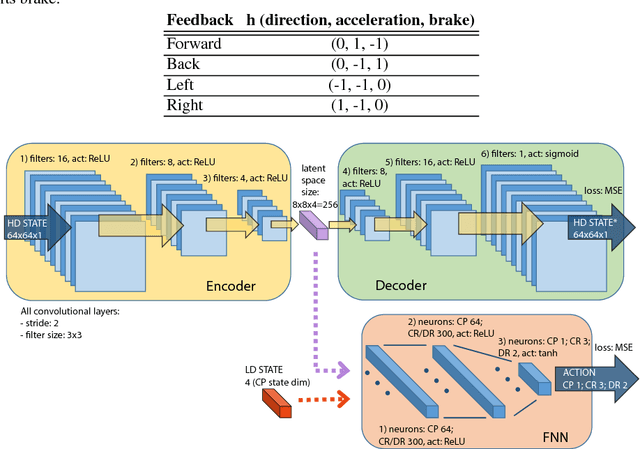
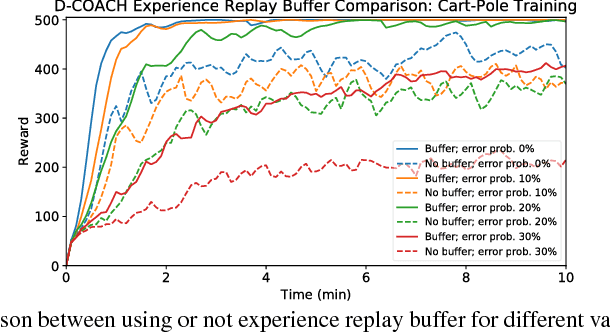
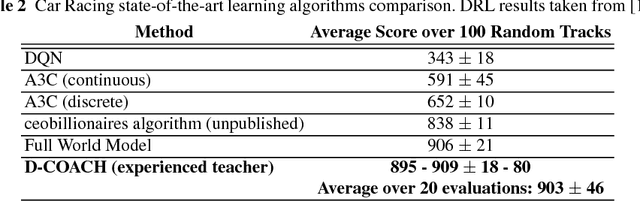
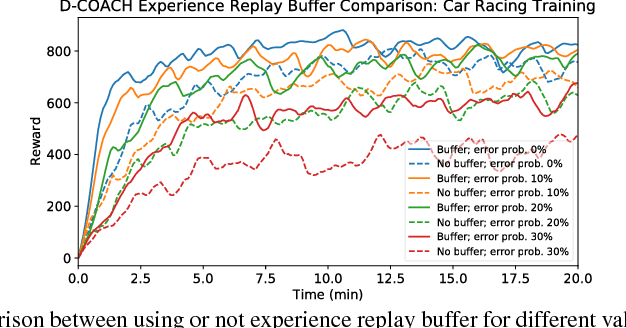
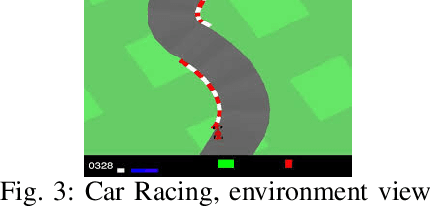
Deep Reinforcement Learning (DRL) has become a powerful strategy to solve complex decision making problems based on Deep Neural Networks (DNNs). However, it is highly data demanding, so unfeasible in physical systems for most applications. In this work, we approach an alternative Interactive Machine Learning (IML) strategy for training DNN policies based on human corrective feedback, with a method called Deep COACH (D-COACH). This approach not only takes advantage of the knowledge and insights of human teachers as well as the power of DNNs, but also has no need of a reward function (which sometimes implies the need of external perception for computing rewards). We combine Deep Learning with the COrrective Advice Communicated by Humans (COACH) framework, in which non-expert humans shape policies by correcting the agent's actions during execution. The D-COACH framework has the potential to solve complex problems without much data or time required. Experimental results validated the efficiency of the framework in three different problems (two simulated, one with a real robot), with state spaces of low and high dimensions, showing the capacity to successfully learn policies for continuous action spaces like in the Car Racing and Cart-Pole problems faster than with DRL.