 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data to Safe Mobile Robot Navigation: An Efficient and Modular Robust MPC Design Pipeline
Aug 09, 2025Model predictive control (MPC) is a powerful strategy for planning and control in autonomous mobile robot navigation. However, ensuring safety in real-world deployments remains challenging due to the presence of disturbances and measurement noise. Existing approaches often rely on idealized assumptions, neglect the impact of noisy measurements, and simply heuristically guess unrealistic bounds. In this work, we present an efficient and modular robust MPC design pipeline that systematically addresses these limitations. The pipeline consists of an iterative procedure that leverages closed-loop experimental data to estimate disturbance bounds and synthesize a robust output-feedback MPC scheme. We provide the pipeline in the form of deterministic and reproducible code to synthesize the robust output-feedback MPC from data. We empirically demonstrate robust constraint satisfaction and recursive feasibility in quadrotor simulations using Gazebo.
Neuro-Evolutionary Approach to Physics-Aware Symbolic Regression
Apr 23, 2025



Symbolic regression is a technique that can automatically derive analytic models from data. Traditionally, symbolic regression has been implemented primarily through genetic programming that evolves populations of candidate solutions sampled by genetic operators, crossover and mutation. More recently, neural networks have been employed to learn the entire analytical model, i.e., its structure and coefficients, using regularized gradient-based optimization. Although this approach tunes the model's coefficients better, it is prone to premature convergence to suboptimal model structures. Here, we propose a neuro-evolutionary symbolic regression method that combines the strengths of evolutionary-based search for optimal neural network (NN) topologies with gradient-based tuning of the network's parameters. Due to the inherent high computational demand of evolutionary algorithms, it is not feasible to learn the parameters of every candidate NN topology to full convergence. Thus, our method employs a memory-based strategy and population perturbations to enhance exploitation and reduce the risk of being trapped in suboptimal NNs. In this way, each NN topology can be trained using only a short sequence of backpropagation iterations. The proposed method was experimentally evaluated on three real-world test problems and has been shown to outperform other NN-based approaches regarding the quality of the models obtained.
Leveraging LLMs, Graphs and Object Hierarchies for Task Planning in Large-Scale Environments
Sep 10, 2024



Planning methods struggle with computational intractability in solving task-level problems in large-scale environments. This work explores leveraging the commonsense knowledge encoded in LLMs to empower planning techniques to deal with these complex scenarios. We achieve this by efficiently using LLMs to prune irrelevant components from the planning problem's state space, substantially simplifying its complexity. We demonstrate the efficacy of this system through extensive experiments within a household simulation environment, alongside real-world validation using a 7-DoF manipulator (video https://youtu.be/6ro2UOtOQS4).
Embedded Hierarchical MPC for Autonomous Navigation
Jun 17, 2024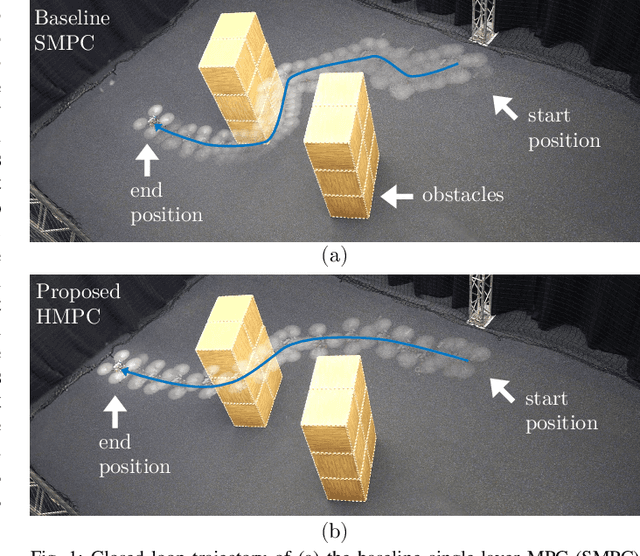
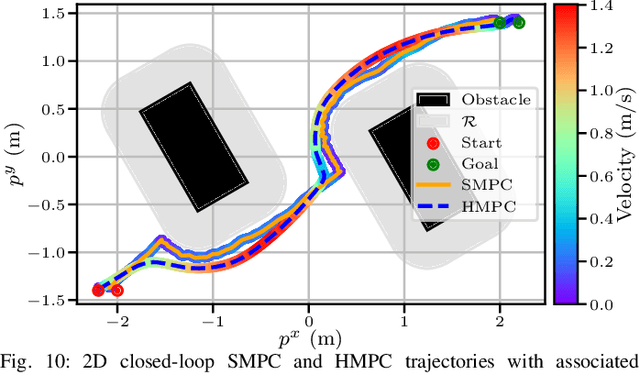
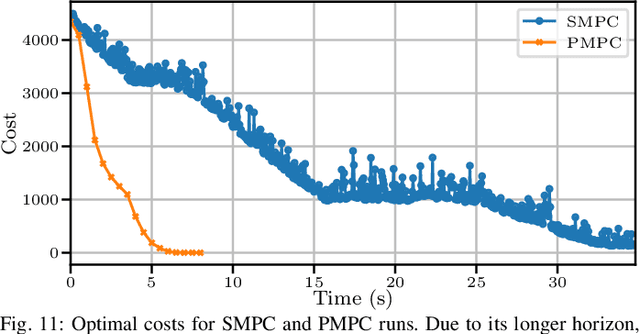
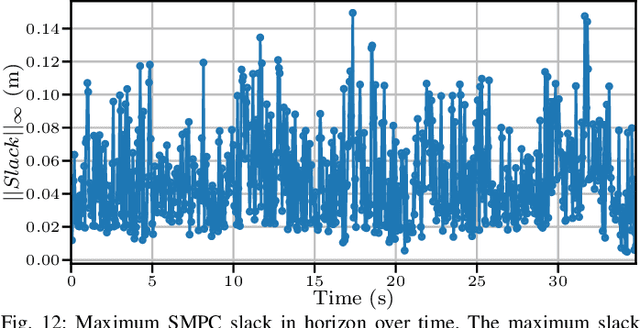
To efficiently deploy robotic systems in society, mobile robots need to autonomously and safely move through complex environments. Nonlinear model predictive control (MPC) methods provide a natural way to find a dynamically feasible trajectory through the environment without colliding with nearby obstacles. However, the limited computation power available on typical embedded robotic systems, such as quadrotors, poses a challenge to running MPC in real-time, including its most expensive tasks: constraints generation and optimization. To address this problem, we propose a novel hierarchical MPC scheme that interconnects a planning and a tracking layer. The planner constructs a trajectory with a long prediction horizon at a slow rate, while the tracker ensures trajectory tracking at a relatively fast rate. We prove that the proposed framework avoids collisions and is recursively feasible. Furthermore, we demonstrate its effectiveness in simulations and lab experiments with a quadrotor that needs to reach a goal position in a complex static environment. The code is efficiently implemented on the quadrotor's embedded computer to ensure real-time feasibility. Compared to a state-of-the-art single-layer MPC formulation, this allows us to increase the planning horizon by a factor of 5, which results in significantly better performance.
A Security Risk Taxonomy for Large Language Models
Nov 19, 2023



As large language models (LLMs) permeate more and more applications, an assessment of their associated security risks becomes increasingly necessary. The potential for exploitation by malicious actors, ranging from disinformation to data breaches and reputation damage, is substantial. This paper addresses a gap in current research by focusing on the security risks posed by LLMs, which extends beyond the widely covered ethical and societal implications. Our work proposes a taxonomy of security risks along the user-model communication pipeline, explicitly focusing on prompt-based attacks on LLMs. We categorize the attacks by target and attack type within a prompt-based interaction scheme. The taxonomy is reinforced with specific attack examples to showcase the real-world impact of these risks. Through this taxonomy, we aim to inform the development of robust and secure LLM applications, enhancing their safety and trustworthiness.
Neural Networks for Symbolic Regression
Feb 03, 2023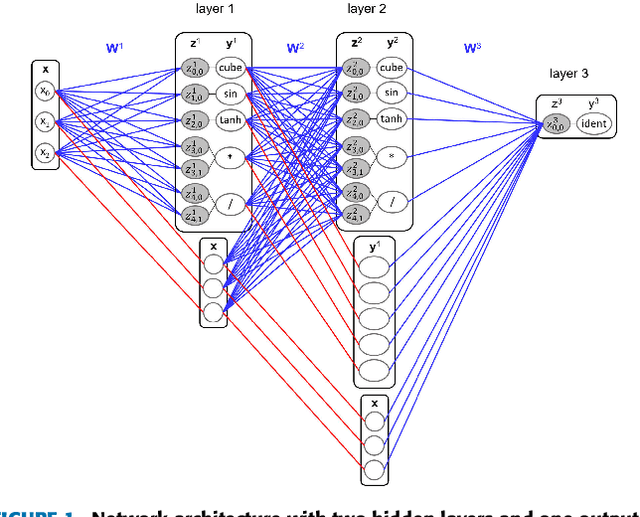
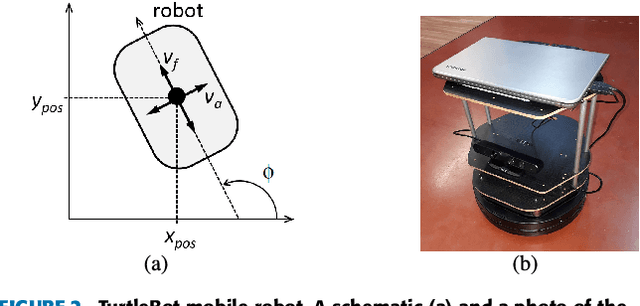
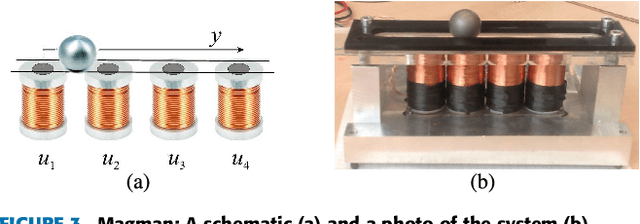
Many real-world systems can be described by mathematical formulas that are human-comprehensible, easy to analyze and can be helpful in explaining the system's behaviour. Symbolic regression is a method that generates nonlinear models from data in the form of analytic expressions. Historically, symbolic regression has been predominantly realized using genetic programming, a method that iteratively evolves a population of candidate solutions that are sampled by genetic operators crossover and mutation. This gradient-free evolutionary approach suffers from several deficiencies: it does not scale well with the number of variables and samples in the training data, models tend to grow in size and complexity without an adequate accuracy gain, and it is hard to fine-tune the inner model coefficients using just genetic operators. Recently, neural networks have been applied to learn the whole analytic formula, i.e., its structure as well as the coefficients, by means of gradient-based optimization algorithms. We propose a novel neural network-based symbolic regression method that constructs physically plausible models based on limited training data and prior knowledge about the system. The method employs an adaptive weighting scheme to effectively deal with multiple loss function terms and an epoch-wise learning process to reduce the chance of getting stuck in poor local optima. Furthermore, we propose a parameter-free method for choosing the model with the best interpolation and extrapolation performance out of all models generated through the whole learning process. We experimentally evaluate the approach on the TurtleBot 2 mobile robot, the magnetic manipulation system, the equivalent resistance of two resistors in parallel, and the anti-lock braking system. The results clearly show the potential of the method to find sparse and accurate models that comply with the prior knowledge provided.
SymFormer: End-to-end symbolic regression using transformer-based architecture
Jun 01, 2022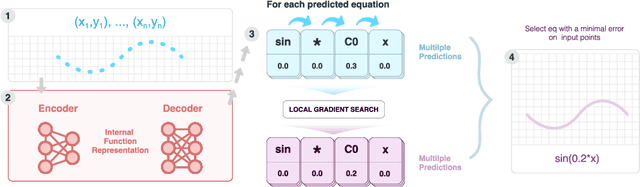
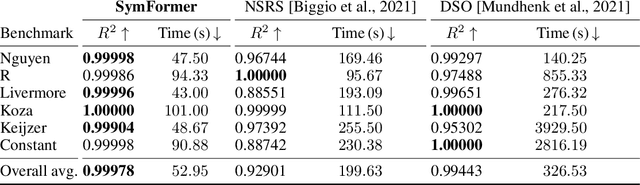
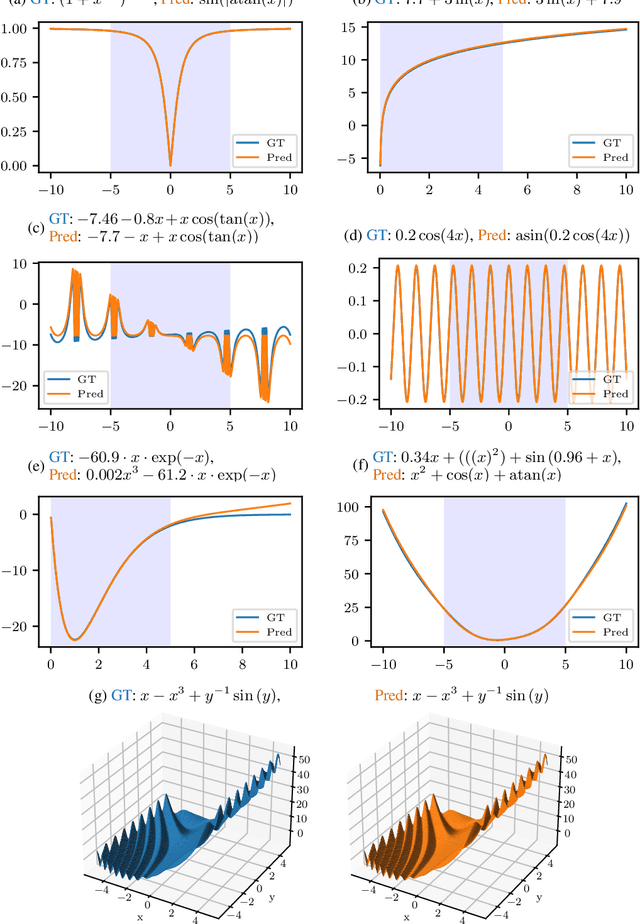
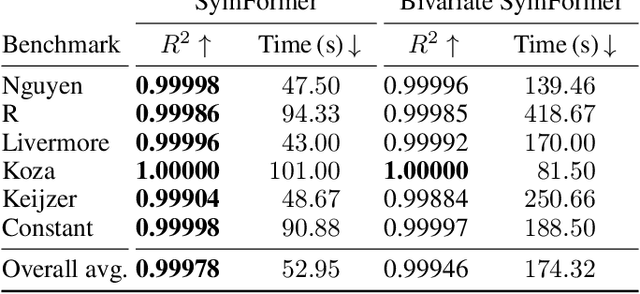
Many real-world problems can be naturally described by mathematical formulas. The task of finding formulas from a set of observed inputs and outputs is called symbolic regression. Recently, neural networks have been applied to symbolic regression, among which the transformer-based ones seem to be the most promising. After training the transformer on a large number of formulas (in the order of days), the actual inference, i.e., finding a formula for new, unseen data, is very fast (in the order of seconds). This is considerably faster than state-of-the-art evolutionary methods. The main drawback of transformers is that they generate formulas without numerical constants, which have to be optimized separately, so yielding suboptimal results. We propose a transformer-based approach called SymFormer, which predicts the formula by outputting the individual symbols and the corresponding constants simultaneously. This leads to better performance in terms of fitting the available data. In addition, the constants provided by SymFormer serve as a good starting point for subsequent tuning via gradient descent to further improve the performance. We show on a set of benchmarks that SymFormer outperforms two state-of-the-art methods while having faster inference.
ViewFormer: NeRF-free Neural Rendering from Few Images Using Transformers
Mar 18, 2022
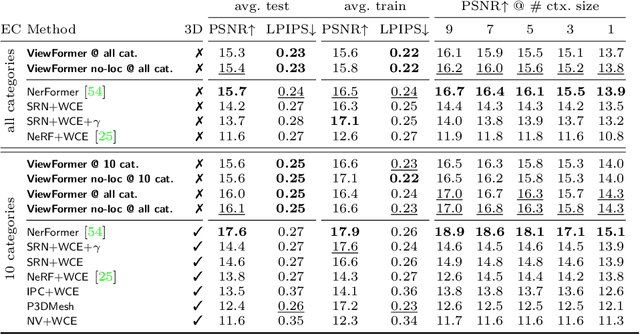
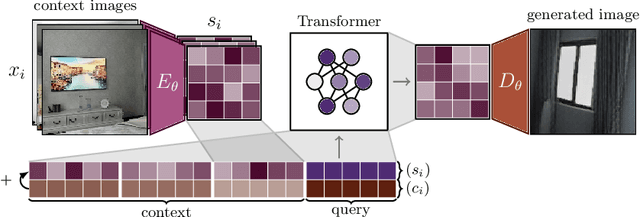
Novel view synthesis is a long-standing problem. In this work, we consider a variant of the problem where we are given only a few context views sparsely covering a scene or an object. The goal is to predict novel viewpoints in the scene, which requires learning priors. The current state of the art is based on Neural Radiance Fields (NeRFs), and while achieving impressive results, the methods suffer from long training times as they require evaluating thousands of 3D point samples via a deep neural network for each image. We propose a 2D-only method that maps multiple context views and a query pose to a new image in a single pass of a neural network. Our model uses a two-stage architecture consisting of a codebook and a transformer model. The codebook is used to embed individual images into a smaller latent space, and the transformer solves the view synthesis task in this more compact space. To train our model efficiently, we introduce a novel branching attention mechanism that allows us to use the same model not only for neural rendering but also for camera pose estimation. Experimental results on real-world scenes show that our approach is competitive compared to NeRF-based methods while not reasoning in 3D, and it is faster to train.
Where to Look Next: Learning Viewpoint Recommendations for Informative Trajectory Planning
Mar 04, 2022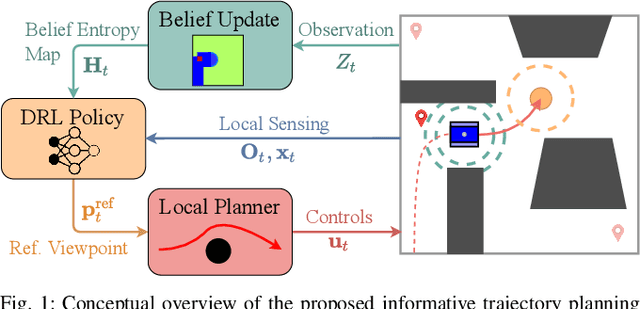



Search missions require motion planning and navigation methods for information gathering that continuously replan based on new observations of the robot's surroundings. Current methods for information gathering, such as Monte Carlo Tree Search, are capable of reasoning over long horizons, but they are computationally expensive. An alternative for fast online execution is to train, offline, an information gathering policy, which indirectly reasons about the information value of new observations. However, these policies lack safety guarantees and do not account for the robot dynamics. To overcome these limitations we train an information-aware policy via deep reinforcement learning, that guides a receding-horizon trajectory optimization planner. In particular, the policy continuously recommends a reference viewpoint to the local planner, such that the resulting dynamically feasible and collision-free trajectories lead to observations that maximize the information gain and reduce the uncertainty about the environment. In simulation tests in previously unseen environments, our method consistently outperforms greedy next-best-view policies and achieves competitive performance compared to Monte Carlo Tree Search, in terms of information gains and coverage time, with a reduction in execution time by three orders of magnitude.
Inclined Quadrotor Landing using Deep Reinforcement Learning
Mar 16, 2021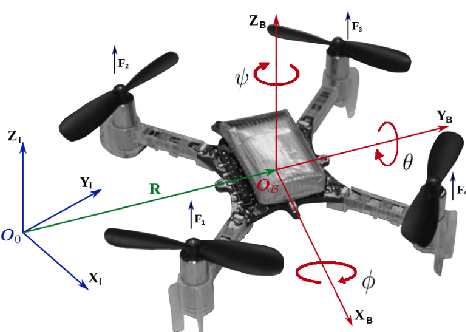
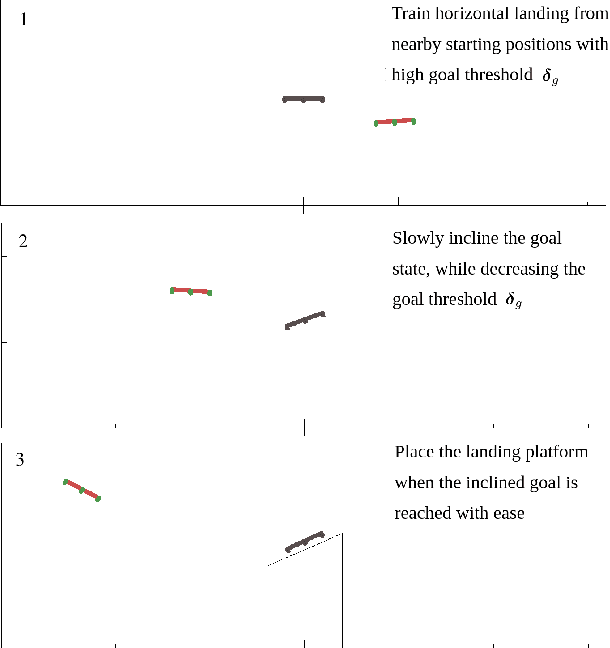
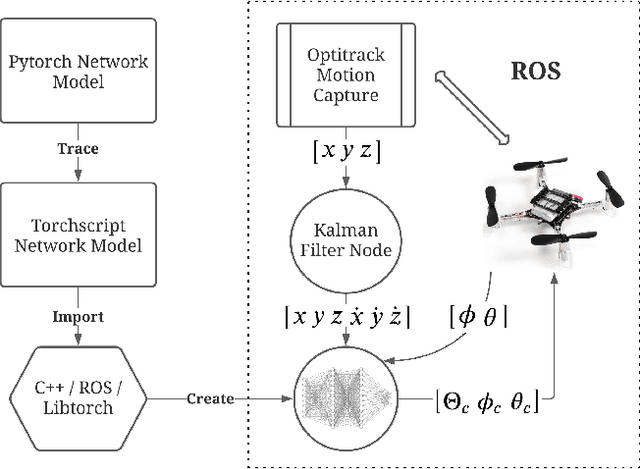

Landing a quadrotor on an inclined surface is a challenging manoeuvre. The final state of any inclined landing trajectory is not an equilibrium, which precludes the use of most conventional control methods. We propose a deep reinforcement learning approach to design an autonomous landing controller for inclined surfaces. Using the proximal policy optimization (PPO) algorithm with sparse rewards and a tailored curriculum learning approach, a robust policy can be trained in simulation in less than 90 minutes on a standard laptop. The policy then directly runs on a real Crazyflie 2.1 quadrotor and successfully performs real inclined landings in a flying arena. A single policy evaluation takes approximately 2.5 ms, which makes it suitable for a future embedded implementation on the quadrotor.