 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymFormer: End-to-end symbolic regression using transformer-based architecture
Jun 01, 2022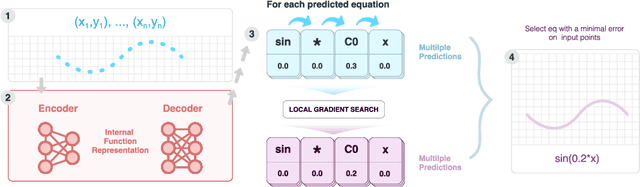
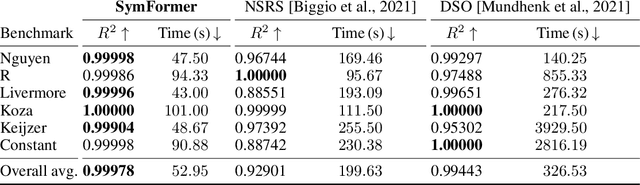
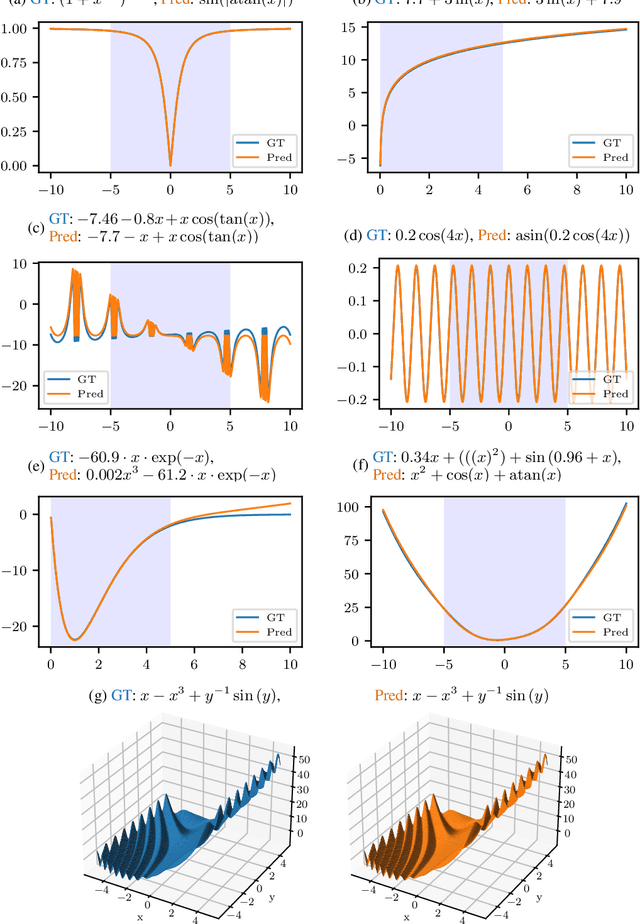
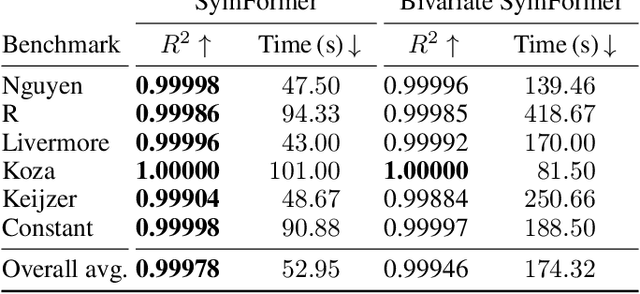
Many real-world problems can be naturally described by mathematical formulas. The task of finding formulas from a set of observed inputs and outputs is called symbolic regression. Recently, neural networks have been applied to symbolic regression, among which the transformer-based ones seem to be the most promising. After training the transformer on a large number of formulas (in the order of days), the actual inference, i.e., finding a formula for new, unseen data, is very fast (in the order of seconds). This is considerably faster than state-of-the-art evolutionary methods. The main drawback of transformers is that they generate formulas without numerical constants, which have to be optimized separately, so yielding suboptimal results. We propose a transformer-based approach called SymFormer, which predicts the formula by outputting the individual symbols and the corresponding constants simultaneously. This leads to better performance in terms of fitting the available data. In addition, the constants provided by SymFormer serve as a good starting point for subsequent tuning via gradient descent to further improve the performance. We show on a set of benchmarks that SymFormer outperforms two state-of-the-art methods while having faster inference.
ViewFormer: NeRF-free Neural Rendering from Few Images Using Transformers
Mar 18, 2022
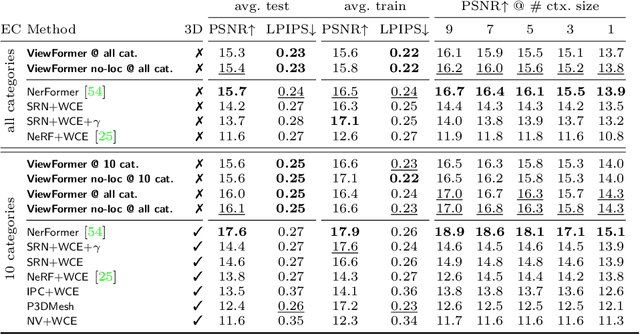
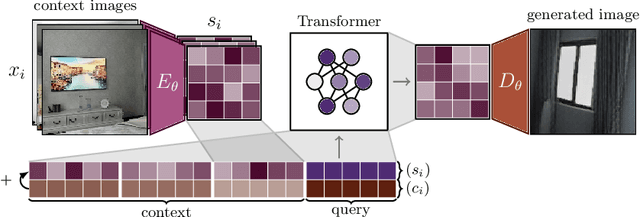
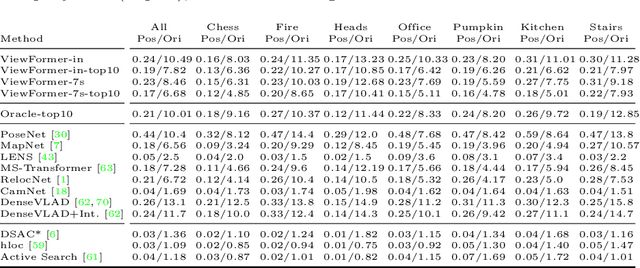
Novel view synthesis is a long-standing problem. In this work, we consider a variant of the problem where we are given only a few context views sparsely covering a scene or an object. The goal is to predict novel viewpoints in the scene, which requires learning priors. The current state of the art is based on Neural Radiance Fields (NeRFs), and while achieving impressive results, the methods suffer from long training times as they require evaluating thousands of 3D point samples via a deep neural network for each image. We propose a 2D-only method that maps multiple context views and a query pose to a new image in a single pass of a neural network. Our model uses a two-stage architecture consisting of a codebook and a transformer model. The codebook is used to embed individual images into a smaller latent space, and the transformer solves the view synthesis task in this more compact space. To train our model efficiently, we introduce a novel branching attention mechanism that allows us to use the same model not only for neural rendering but also for camera pose estimation. Experimental results on real-world scenes show that our approach is competitive compared to NeRF-based methods while not reasoning in 3D, and it is faster to train.
AuGPT: Dialogue with Pre-trained Language Models and Data Augmentation
Feb 09, 2021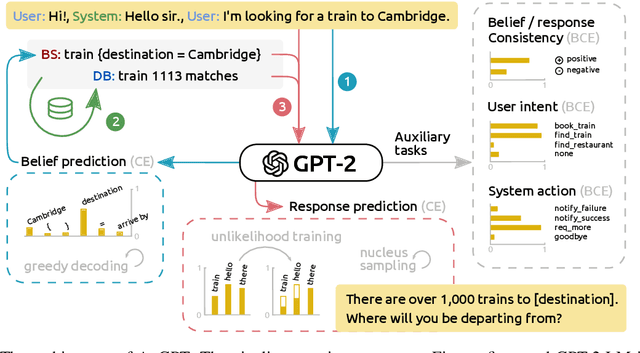
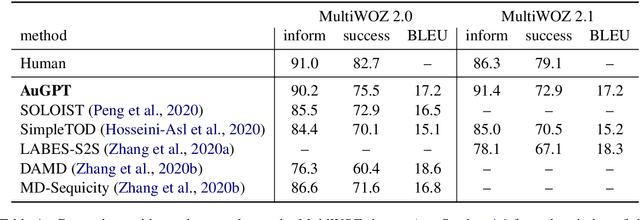
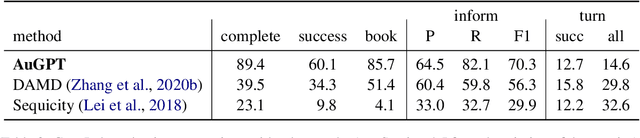
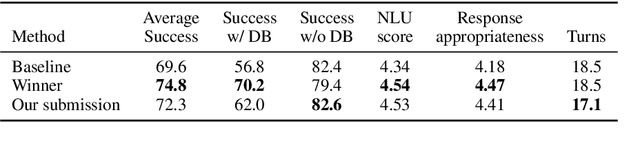
Attention-based pre-trained language models such as GPT-2 brought considerable progress to end-to-end dialogue modelling. However, they also present considerable risks for task-oriented dialogue, such as lack of knowledge grounding or diversity. To address these issues, we introduce modified training objectives for language model finetuning, and we employ massive data augmentation via back-translation to increase the diversity of the training data. We further examine the possibilities of combining data from multiples sources to improve performance on the target dataset. We carefully evaluate our contributions with both human and automatic methods. Our model achieves state-of-the-art performance on the MultiWOZ data and shows competitive performance in human evaluation.
Visual Navigation in Real-World Indoor Environments Using End-to-End Deep Reinforcement Learning
Oct 21, 2020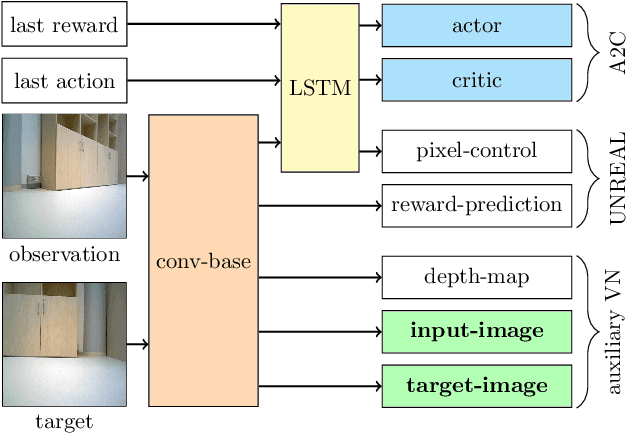


Visual navigation is essential for many applications in robotics, from manipulation, through mobile robotics to automated driving. Deep reinforcement learning (DRL) provides an elegant map-free approach integrating image processing, localization, and planning in one module, which can be trained and therefore optimized for a given environment. However, to date, DRL-based visual navigation was validated exclusively in simulation, where the simulator provides information that is not available in the real world, e.g., the robot's position or image segmentation masks. This precludes the use of the learned policy on a real robot. Therefore, we propose a novel approach that enables a direct deployment of the trained policy on real robots. We have designed visual auxiliary tasks, a tailored reward scheme, and a new powerful simulator to facilitate domain randomization. The policy is fine-tuned on images collected from real-world environments. We have evaluated the method on a mobile robot in a real office environment. The training took ~30 hours on a single GPU. In 30 navigation experiments, the robot reached a 0.3-meter neighborhood of the goal in more than 86.7% of cases. This result makes the proposed method directly applicable to tasks like mobile manipulation.
Vision-based Navigation Using Deep Reinforcement Learning
Aug 08, 2019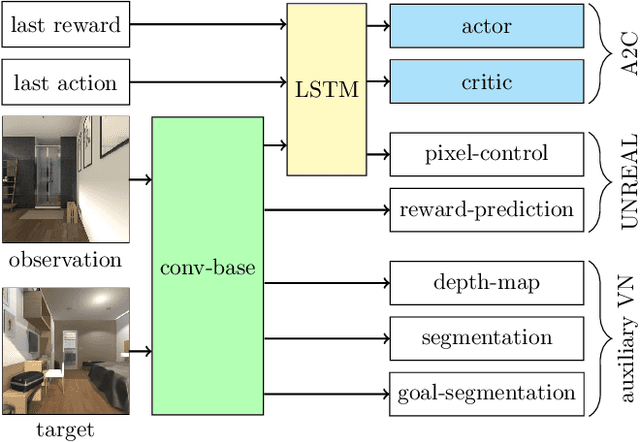
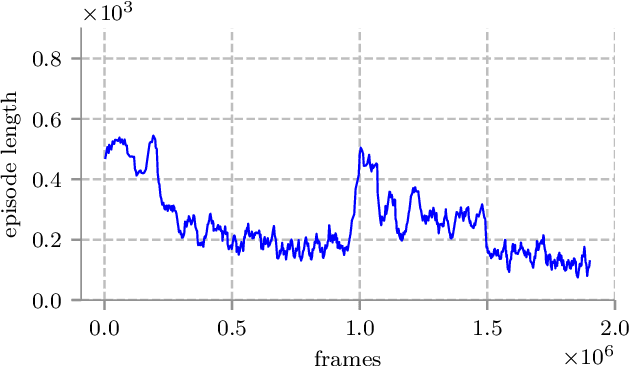
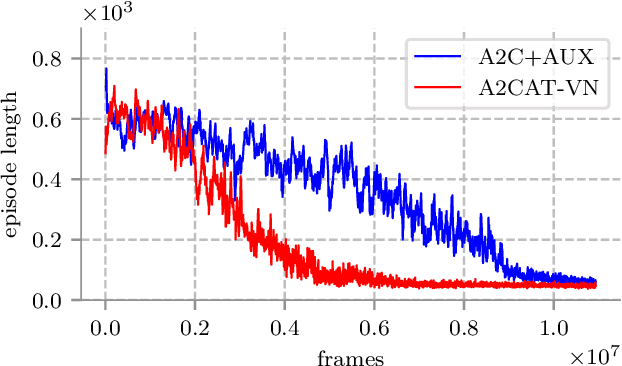
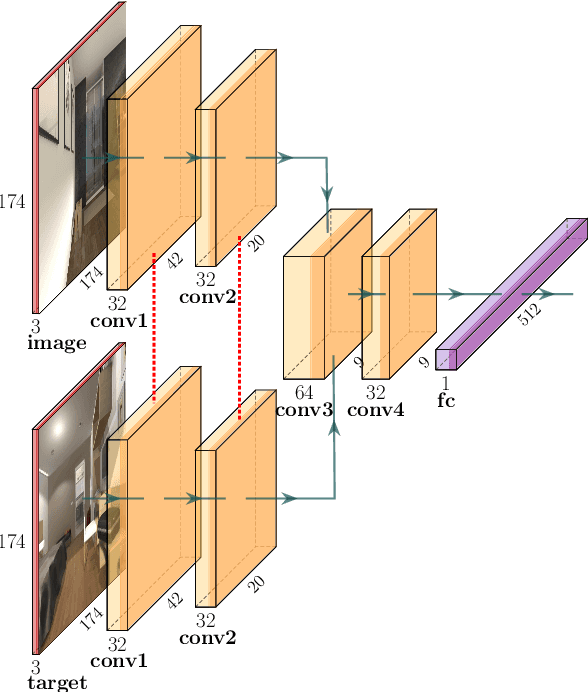
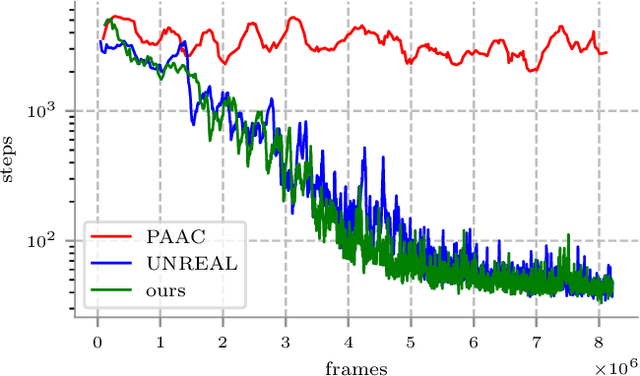
Deep reinforcement learning (RL) has been successfully applied to a variety of game-like environments. However, the application of deep RL to visual navigation with realistic environments is a challenging task. We propose a novel learning architecture capable of navigating an agent, e.g. a mobile robot, to a target given by an image. To achieve this, we have extended the batched A2C algorithm with auxiliary tasks designed to improve visual navigation performance. We propose three additional auxiliary tasks: predicting the segmentation of the observation image and of the target image and predicting the depth-map. These tasks enable the use of supervised learning to pre-train a large part of the network and to reduce the number of training steps substantially. The training performance has been further improved by increasing the environment complexity gradually over time. An efficient neural network structure is proposed, which is capable of learning for multiple targets in multiple environments. Our method navigates in continuous state spaces and on the AI2-THOR environment simulator outperforms state-of-the-art goal-oriented visual navigation methods from the literature.