 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAARGH! End-to-end Retrieval-Generation for Task-Oriented Dialog
Sep 08, 2022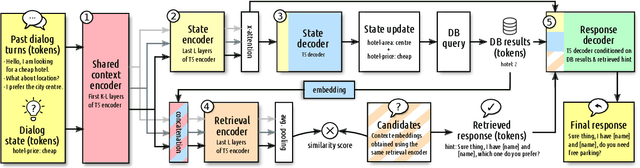
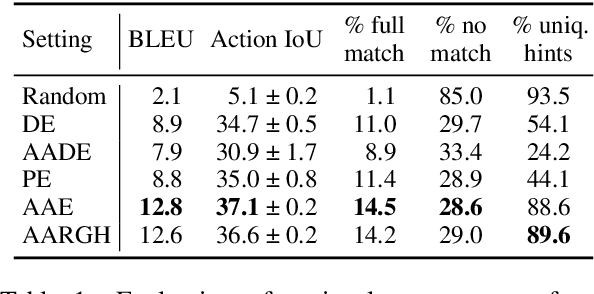

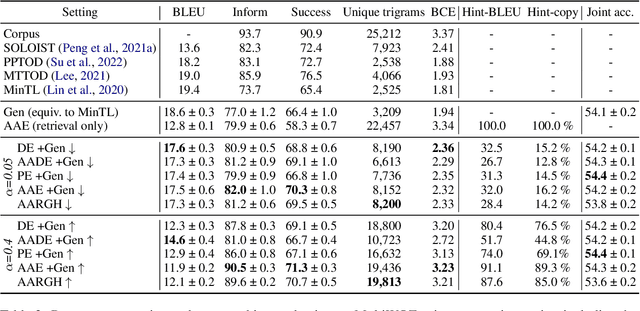
We introduce AARGH, an end-to-end task-oriented dialog system combining retrieval and generative approaches in a single model, aiming at improving dialog management and lexical diversity of outputs. The model features a new response selection method based on an action-aware training objective and a simplified single-encoder retrieval architecture which allow us to build an end-to-end retrieval-enhanced generation model where retrieval and generation share most of the parameters. On the MultiWOZ dataset, we show that our approach produces more diverse outputs while maintaining or improving state tracking and context-to-response generation performance, compared to state-of-the-art baselines.
Shades of BLEU, Flavours of Success: The Case of MultiWOZ
Jun 10, 2021

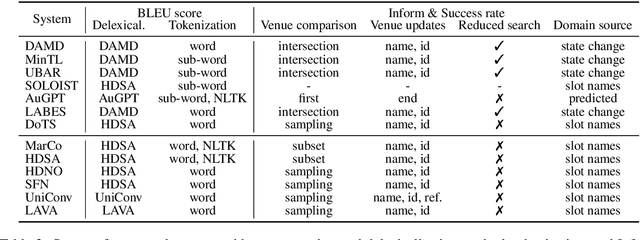
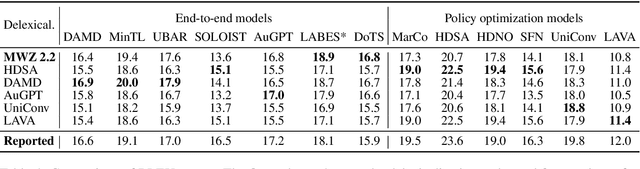
The MultiWOZ dataset (Budzianowski et al.,2018) is frequently used for benchmarking context-to-response abilities of task-oriented dialogue systems. In this work, we identify inconsistencies in data preprocessing and reporting of three corpus-based metrics used on this dataset, i.e., BLEU score and Inform & Success rates. We point out a few problems of the MultiWOZ benchmark such as unsatisfactory preprocessing, insufficient or under-specified evaluation metrics, or rigid database. We re-evaluate 7 end-to-end and 6 policy optimization models in as-fair-as-possible setups, and we show that their reported scores cannot be directly compared. To facilitate comparison of future systems, we release our stand-alone standardized evaluation scripts. We also give basic recommendations for corpus-based benchmarking in future works.
AuGPT: Dialogue with Pre-trained Language Models and Data Augmentation
Feb 09, 2021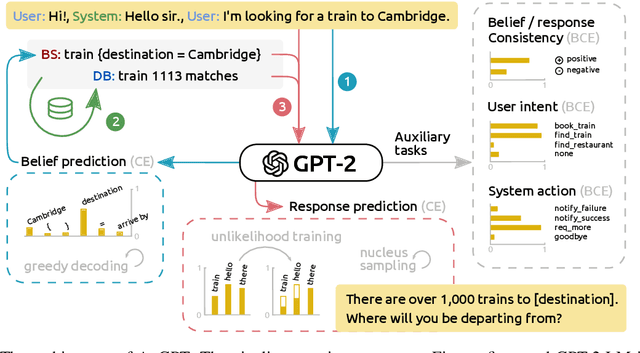
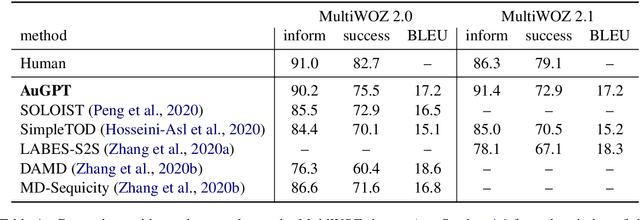
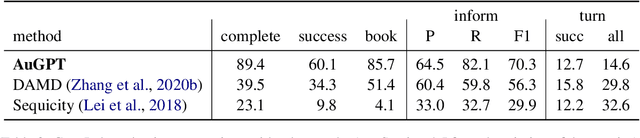
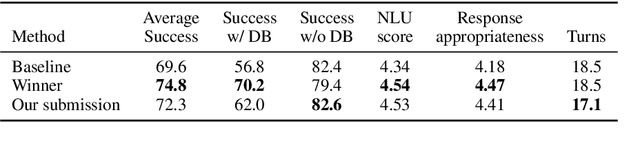
Attention-based pre-trained language models such as GPT-2 brought considerable progress to end-to-end dialogue modelling. However, they also present considerable risks for task-oriented dialogue, such as lack of knowledge grounding or diversity. To address these issues, we introduce modified training objectives for language model finetuning, and we employ massive data augmentation via back-translation to increase the diversity of the training data. We further examine the possibilities of combining data from multiples sources to improve performance on the target dataset. We carefully evaluate our contributions with both human and automatic methods. Our model achieves state-of-the-art performance on the MultiWOZ data and shows competitive performance in human evaluation.
One Model, Many Languages: Meta-learning for Multilingual Text-to-Speech
Aug 03, 2020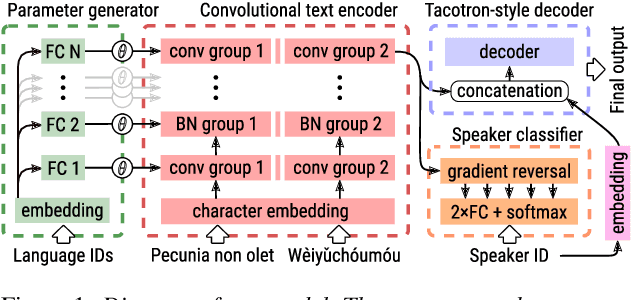

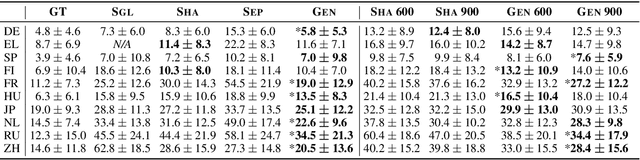
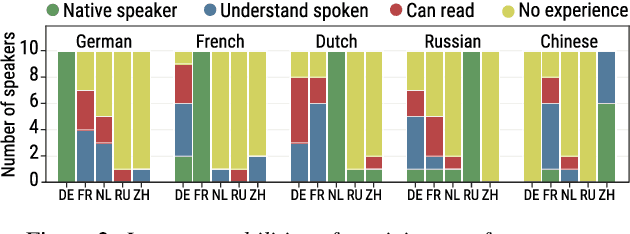
We introduce an approach to multilingual speech synthesis which uses the meta-learning concept of contextual parameter generation and produces natural-sounding multilingual speech using more languages and less training data than previous approaches. Our model is based on Tacotron 2 with a fully convolutional input text encoder whose weights are predicted by a separate parameter generator network. To boost voice cloning, the model uses an adversarial speaker classifier with a gradient reversal layer that removes speaker-specific information from the encoder. We arranged two experiments to compare our model with baselines using various levels of cross-lingual parameter sharing, in order to evaluate: (1) stability and performance when training on low amounts of data, (2) pronunciation accuracy and voice quality of code-switching synthesis. For training, we used the CSS10 dataset and our new small dataset based on Common Voice recordings in five languages. Our model is shown to effectively share information across languages and according to a subjective evaluation test, it produces more natural and accurate code-switching speech than the baselines.