 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for Span Labeling with Large Language Models
Jan 23, 2026Large language models (LLMs) are increasingly used for text analysis tasks, such as named entity recognition or error detection. Unlike encoder-based models, however, generative architectures lack an explicit mechanism to refer to specific parts of their input. This leads to a variety of ad-hoc prompting strategies for span labeling, often with inconsistent results. In this paper, we categorize these strategies into three families: tagging the input text, indexing numerical positions of spans, and matching span content. To address the limitations of content matching, we introduce LogitMatch, a new constrained decoding method that forces the model's output to align with valid input spans. We evaluate all methods across four diverse tasks. We find that while tagging remains a robust baseline, LogitMatch improves upon competitive matching-based methods by eliminating span matching issues and outperforms other strategies in some setups.
LLM Agents Implement an NLG System from Scratch: Building Interpretable Rule-Based RDF-to-Text Generators
Dec 20, 2025We present a novel neurosymbolic framework for RDF-to-text generation, in which the model is "trained" through collaborative interactions among multiple LLM agents rather than traditional backpropagation. The LLM agents produce rule-based Python code for a generator for the given domain, based on RDF triples only, with no in-domain human reference texts. The resulting system is fully interpretable, requires no supervised training data, and generates text nearly instantaneously using only a single CPU. Our experiments on the WebNLG and OpenDialKG data show that outputs produced by our approach reduce hallucination, with only slight fluency penalties compared to finetuned or prompted language models
Real-World Summarization: When Evaluation Reaches Its Limits
Jul 15, 2025We examine evaluation of faithfulness to input data in the context of hotel highlights: brief LLM-generated summaries that capture unique features of accommodations. Through human evaluation campaigns involving categorical error assessment and span-level annotation, we compare traditional metrics, trainable methods, and LLM-as-a-judge approaches. Our findings reveal that simpler metrics like word overlap correlate surprisingly well with human judgments (Spearman correlation rank of 0.63), often outperforming more complex methods when applied to out-of-domain data. We further demonstrate that while LLMs can generate high-quality highlights, they prove unreliable for evaluation as they tend to severely under- or over-annotate. Our analysis of real-world business impacts shows incorrect and non-checkable information pose the greatest risks. We also highlight challenges in crowdsourced evaluations.
Large Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
OpeNLGauge: An Explainable Metric for NLG Evaluation with Open-Weights LLMs
Mar 14, 2025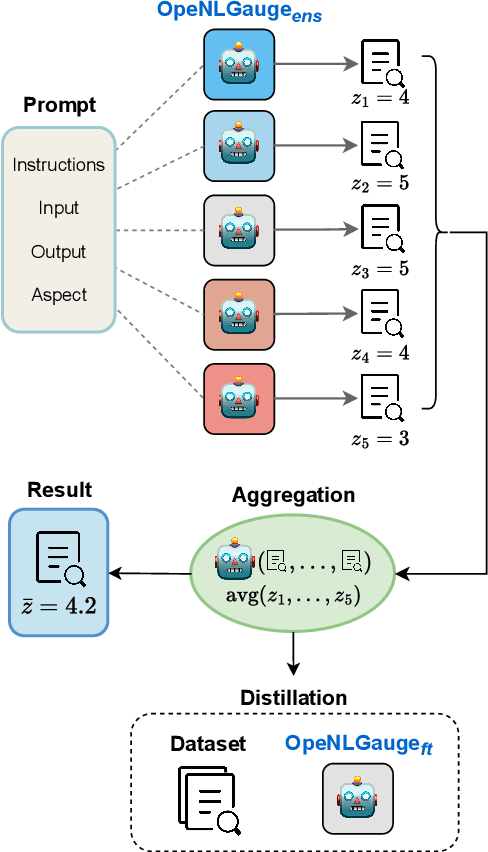


Large Language Models (LLMs) have demonstrated great potential as evaluators of NLG systems, allowing for high-quality, reference-free, and multi-aspect assessments. However, existing LLM-based metrics suffer from two major drawbacks: reliance on proprietary models to generate training data or perform evaluations, and a lack of fine-grained, explanatory feedback. In this paper, we introduce OpeNLGauge, a fully open-source, reference-free NLG evaluation metric that provides accurate explanations based on error spans. OpeNLGauge is available as a two-stage ensemble of larger open-weight LLMs, or as a small fine-tuned evaluation model, with confirmed generalizability to unseen tasks, domains and aspects. Our extensive meta-evaluation shows that OpeNLGauge achieves competitive correlation with human judgments, outperforming state-of-the-art models on certain tasks while maintaining full reproducibility and providing explanations more than twice as accurate.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
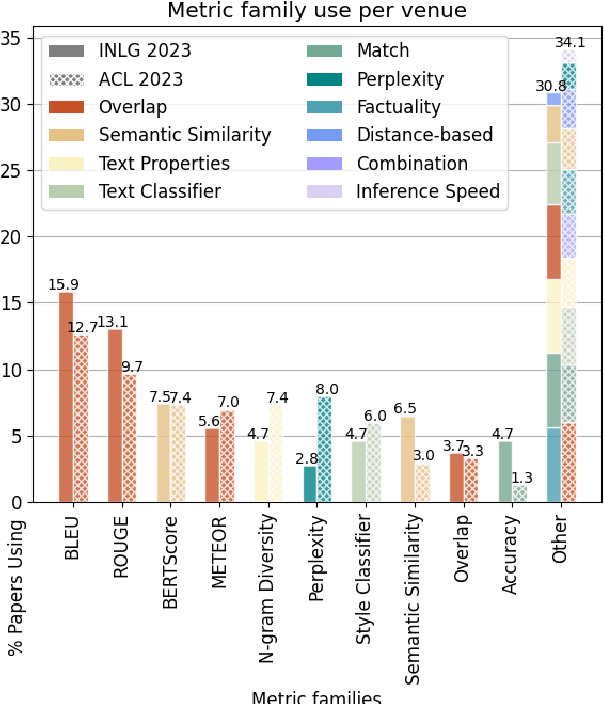
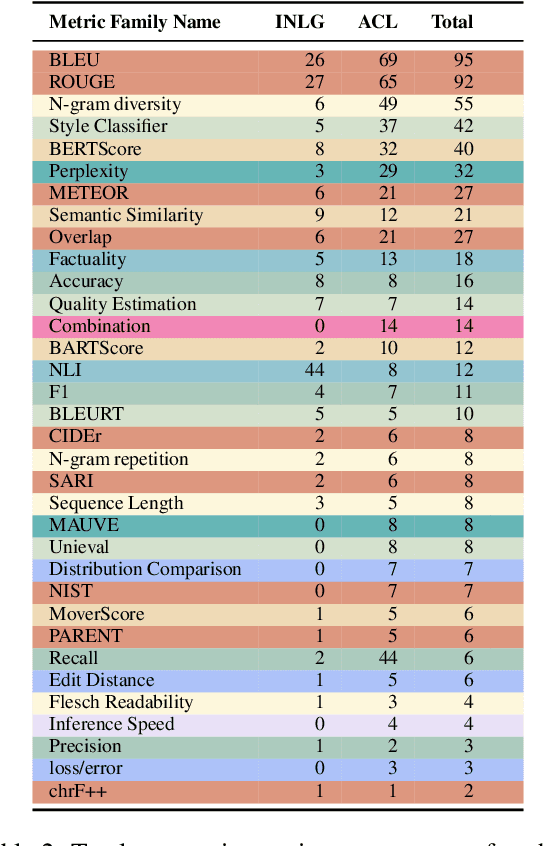
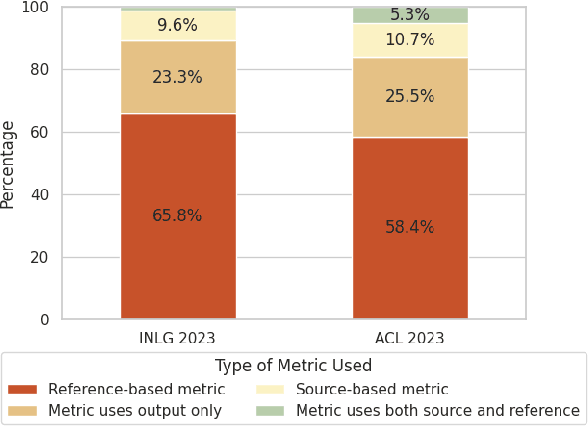
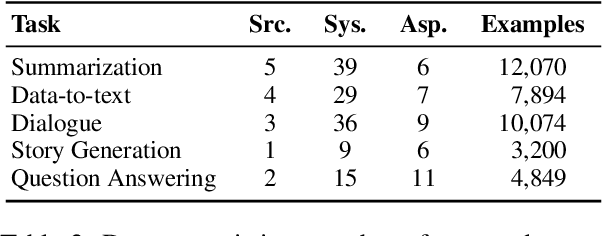
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
Teaching LLMs at Charles University: Assignments and Activities
Jul 29, 2024This paper presents teaching materials, particularly assignments and ideas for classroom activities, from a new course on large language models (LLMs) taught at Charles University. The assignments include experiments with LLM inference for weather report generation and machine translation. The classroom activities include class quizzes, focused research on downstream tasks and datasets, and an interactive "best paper" session aimed at reading and comprehension of research papers.
factgenie: A Framework for Span-based Evaluation of Generated Texts
Jul 25, 2024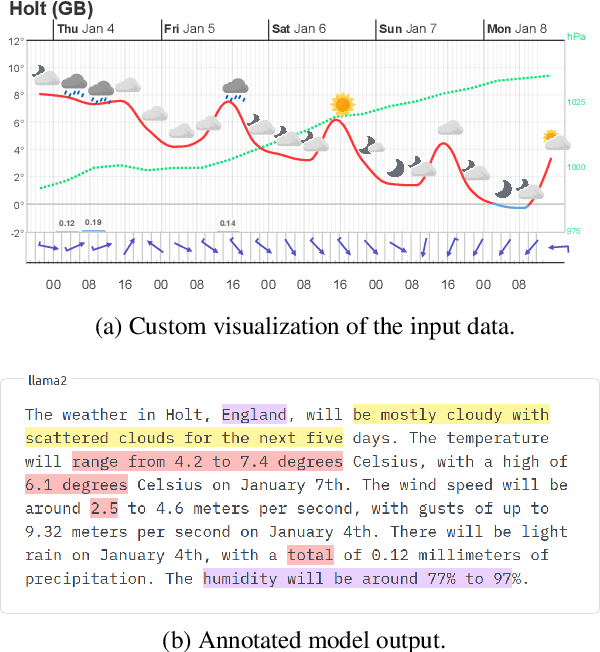
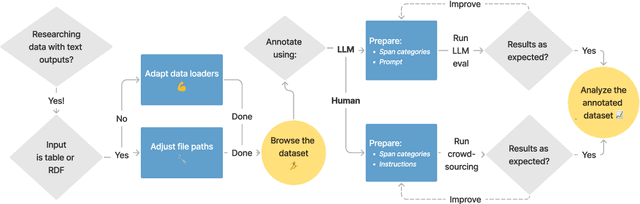
We present factgenie: a framework for annotating and visualizing word spans in textual model outputs. Annotations can capture various span-based phenomena such as semantic inaccuracies or irrelevant text. With factgenie, the annotations can be collected both from human crowdworkers and large language models. Our framework consists of a web interface for data visualization and gathering text annotations, powered by an easily extensible codebase.
Are Large Language Models Actually Good at Text Style Transfer?
Jun 09, 2024We analyze the performance of large language models (LLMs) on Text Style Transfer (TST), specifically focusing on sentiment transfer and text detoxification across three languages: English, Hindi, and Bengali. Text Style Transfer involves modifying the linguistic style of a text while preserving its core content. We evaluate the capabilities of pre-trained LLMs using zero-shot and few-shot prompting as well as parameter-efficient finetuning on publicly available datasets. Our evaluation using automatic metrics, GPT-4 and human evaluations reveals that while some prompted LLMs perform well in English, their performance in on other languages (Hindi, Bengali) remains average. However, finetuning significantly improves results compared to zero-shot and few-shot prompting, making them comparable to previous state-of-the-art. This underscores the necessity of dedicated datasets and specialized models for effective TST.
Multilingual Text Style Transfer: Datasets & Models for Indian Languages
May 31, 2024



Text style transfer (TST) involves altering the linguistic style of a text while preserving its core content. This paper focuses on sentiment transfer, a vital TST subtask (Mukherjee et al., 2022a), across a spectrum of Indian languages: Hindi, Magahi, Malayalam, Marathi, Punjabi, Odia, Telugu, and Urdu, expanding upon previous work on English-Bangla sentiment transfer (Mukherjee et al., 2023). We introduce dedicated datasets of 1,000 positive and 1,000 negative style-parallel sentences for each of these eight languages. We then evaluate the performance of various benchmark models categorized into parallel, non-parallel, cross-lingual, and shared learning approaches, including the Llama2 and GPT-3.5 large language models (LLMs). Our experiments highlight the significance of parallel data in TST and demonstrate the effectiveness of the Masked Style Filling (MSF) approach (Mukherjee et al., 2023) in non-parallel techniques. Moreover, cross-lingual and joint multilingual learning methods show promise, offering insights into selecting optimal models tailored to the specific language and task requirements. To the best of our knowledge, this work represents the first comprehensive exploration of the TST task as sentiment transfer across a diverse set of languages.