 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of LLM-as-Judge: Why Inter-LLM Consensus Is Not Human Alignment
Jun 02, 2026LMs-as-judges are now standard, yet judges agree strongly with one another while agreeing only weakly with humans. We test whether this reflects shared signal or shared bias by measuring four geometric quantities on the standard LLM-as-judge stack across four community-built Indic datasets, eight Indic languages, and 41 LLM judges: score spread, effective rank, principal angle to the human subspace, and stacked correlations among judges and humans, all with bootstrap confidence intervals. On subjective rubrics, judges use less than half the human score range ($σ_J / σ_H \approx 0.3$--$0.5$). Their evaluation axis is nearly orthogonal to the human one and noticeably further from humans than humans are from each other ($87^\circ$--$89^\circ$ versus $78^\circ$--$81^\circ$). Inter-LLM agreement exceeds LLM--human agreement ($r_{LL} \approx 0.35$ versus $r_{LH} \approx 0.27$--$0.32$). On a rubric with a verifiable factual answer, the same diagnostics fall back into the human range (axis $58.5^\circ$; $r_{LH} = 0.519$). Fine-tuning and preference optimization recover spread ($0.32 \rightarrow 1.08$) but barely move the axis (still $87^\circ$--$88^\circ$). Only post-hoc calibration on a small human-anchored set improves all four community-health rubrics together, placing a calibrated 24B Indic judge ($r = 0.184$) ahead of GPT-5.5 ($r = 0.123$), yet still short of human reliability (human-human $r = 0.474$ on the verifiable rubric). We argue that inter-LLM agreement should be considered evidence of human alignment only when a direct geometric check on the judge's score subspace passes; otherwise, the consensus reflects agreement within a collapsed subspace.
Evaluating Text Style Transfer Evaluation: Are There Any Reliable Metrics?
Feb 07, 2025Text Style Transfer (TST) is the task of transforming a text to reflect a particular style while preserving its original content. Evaluating TST outputs is a multidimensional challenge, requiring the assessment of style transfer accuracy, content preservation, and naturalness. Using human evaluation is ideal but costly, same as in other natural language processing (NLP) tasks, however, automatic metrics for TST have not received as much attention as metrics for, e.g., machine translation or summarization. In this paper, we examine both set of existing and novel metrics from broader NLP tasks for TST evaluation, focusing on two popular subtasks-sentiment transfer and detoxification-in a multilingual context comprising English, Hindi, and Bengali. By conducting meta-evaluation through correlation with human judgments, we demonstrate the effectiveness of these metrics when used individually and in ensembles. Additionally, we investigate the potential of Large Language Models (LLMs) as tools for TST evaluation. Our findings highlight that certain advanced NLP metrics and experimental-hybrid-techniques, provide better insights than existing TST metrics for delivering more accurate, consistent, and reproducible TST evaluations.
Women, Infamous, and Exotic Beings: What Honorific Usages in Wikipedia Reveal about the Socio-Cultural Norms
Jan 07, 2025Honorifics serve as powerful linguistic markers that reflect social hierarchies and cultural values. This paper presents a large-scale, cross-linguistic exploration of usage of honorific pronouns in Bengali and Hindi Wikipedia articles, shedding light on how socio-cultural factors shape language. Using LLM (GPT-4o), we annotated 10, 000 articles of real and fictional beings in each language for several sociodemographic features such as gender, age, fame, and exoticness, and the use of honorifics. We find that across all feature combinations, use of honorifics is consistently more common in Bengali than Hindi. For both languages, the use non-honorific pronouns is more commonly observed for infamous, juvenile, and exotic beings. Notably, we observe a gender bias in use of honorifics in Hindi, with men being more commonly referred to with honorifics than women.
A Survey of Text Style Transfer: Applications and Ethical Implications
Jul 23, 2024Text style transfer (TST) is an important task in controllable text generation, which aims to control selected attributes of language use, such as politeness, formality, or sentiment, without altering the style-independent content of the text. The field has received considerable research attention in recent years and has already been covered in several reviews, but the focus has mostly been on the development of new algorithms and learning from different types of data (supervised, unsupervised, out-of-domain, etc.) and not so much on the application side. However, TST-related technologies are gradually reaching a production- and deployment-ready level, and therefore, the inclusion of the application perspective in TST research becomes crucial. Similarly, the often overlooked ethical considerations of TST technology have become a pressing issue. This paper presents a comprehensive review of TST applications that have been researched over the years, using both traditional linguistic approaches and more recent deep learning methods. We discuss current challenges, future research directions, and ethical implications of TST applications in text generation. By providing a holistic overview of the landscape of TST applications, we hope to stimulate further research and contribute to a better understanding of the potential as well as ethical considerations associated with TST.
Text Style Transfer: An Introductory Overview
Jul 20, 2024Text Style Transfer (TST) is a pivotal task in natural language generation to manipulate text style attributes while preserving style-independent content. The attributes targeted in TST can vary widely, including politeness, authorship, mitigation of offensive language, modification of feelings, and adjustment of text formality. TST has become a widely researched topic with substantial advancements in recent years. This paper provides an introductory overview of TST, addressing its challenges, existing approaches, datasets, evaluation measures, subtasks, and applications. This fundamental overview improves understanding of the background and fundamentals of text style transfer.
Are Large Language Models Actually Good at Text Style Transfer?
Jun 09, 2024We analyze the performance of large language models (LLMs) on Text Style Transfer (TST), specifically focusing on sentiment transfer and text detoxification across three languages: English, Hindi, and Bengali. Text Style Transfer involves modifying the linguistic style of a text while preserving its core content. We evaluate the capabilities of pre-trained LLMs using zero-shot and few-shot prompting as well as parameter-efficient finetuning on publicly available datasets. Our evaluation using automatic metrics, GPT-4 and human evaluations reveals that while some prompted LLMs perform well in English, their performance in on other languages (Hindi, Bengali) remains average. However, finetuning significantly improves results compared to zero-shot and few-shot prompting, making them comparable to previous state-of-the-art. This underscores the necessity of dedicated datasets and specialized models for effective TST.
Multilingual Text Style Transfer: Datasets & Models for Indian Languages
May 31, 2024



Text style transfer (TST) involves altering the linguistic style of a text while preserving its core content. This paper focuses on sentiment transfer, a vital TST subtask (Mukherjee et al., 2022a), across a spectrum of Indian languages: Hindi, Magahi, Malayalam, Marathi, Punjabi, Odia, Telugu, and Urdu, expanding upon previous work on English-Bangla sentiment transfer (Mukherjee et al., 2023). We introduce dedicated datasets of 1,000 positive and 1,000 negative style-parallel sentences for each of these eight languages. We then evaluate the performance of various benchmark models categorized into parallel, non-parallel, cross-lingual, and shared learning approaches, including the Llama2 and GPT-3.5 large language models (LLMs). Our experiments highlight the significance of parallel data in TST and demonstrate the effectiveness of the Masked Style Filling (MSF) approach (Mukherjee et al., 2023) in non-parallel techniques. Moreover, cross-lingual and joint multilingual learning methods show promise, offering insights into selecting optimal models tailored to the specific language and task requirements. To the best of our knowledge, this work represents the first comprehensive exploration of the TST task as sentiment transfer across a diverse set of languages.
Text Detoxification as Style Transfer in English and Hindi
Feb 12, 2024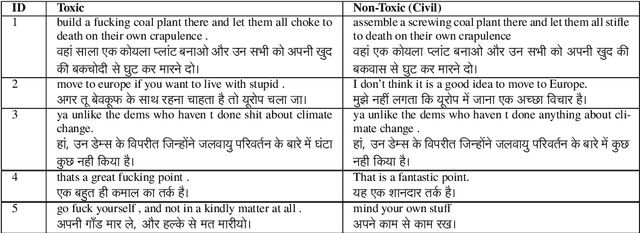
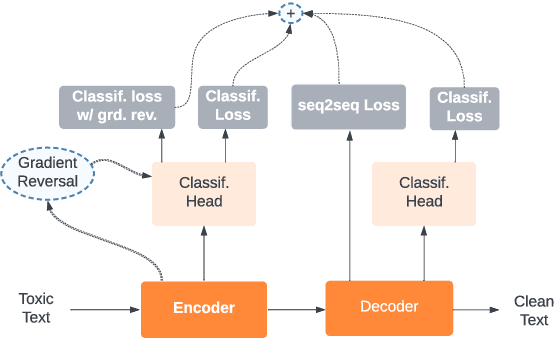

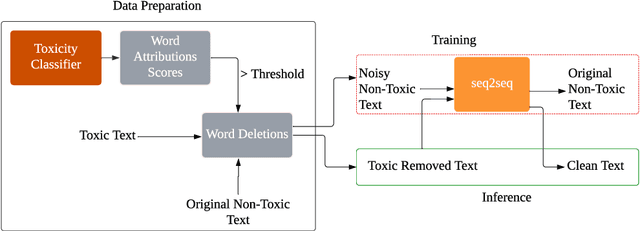
This paper focuses on text detoxification, i.e., automatically converting toxic text into non-toxic text. This task contributes to safer and more respectful online communication and can be considered a Text Style Transfer (TST) task, where the text style changes while its content is preserved. We present three approaches: knowledge transfer from a similar task, multi-task learning approach, combining sequence-to-sequence modeling with various toxicity classification tasks, and, delete and reconstruct approach. To support our research, we utilize a dataset provided by Dementieva et al.(2021), which contains multiple versions of detoxified texts corresponding to toxic texts. In our experiments, we selected the best variants through expert human annotators, creating a dataset where each toxic sentence is paired with a single, appropriate detoxified version. Additionally, we introduced a small Hindi parallel dataset, aligning with a part of the English dataset, suitable for evaluation purposes. Our results demonstrate that our approach effectively balances text detoxication while preserving the actual content and maintaining fluency.
Balancing the Style-Content Trade-Off in Sentiment Transfer Using Polarity-Aware Denoising
Dec 22, 2023Text sentiment transfer aims to flip the sentiment polarity of a sentence (positive to negative or vice versa) while preserving its sentiment-independent content. Although current models show good results at changing the sentiment, content preservation in transferred sentences is insufficient. In this paper, we present a sentiment transfer model based on polarity-aware denoising, which accurately controls the sentiment attributes in generated text, preserving the content to a great extent and helping to balance the style-content trade-off. Our proposed model is structured around two key stages in the sentiment transfer process: better representation learning using a shared encoder and sentiment-controlled generation using separate sentiment-specific decoders. Empirical results show that our methods outperforms state-of-the-art baselines in terms of content preservation while staying competitive in terms of style transfer accuracy and fluency.