 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies for Span Labeling with Large Language Models
Jan 23, 2026Large language models (LLMs) are increasingly used for text analysis tasks, such as named entity recognition or error detection. Unlike encoder-based models, however, generative architectures lack an explicit mechanism to refer to specific parts of their input. This leads to a variety of ad-hoc prompting strategies for span labeling, often with inconsistent results. In this paper, we categorize these strategies into three families: tagging the input text, indexing numerical positions of spans, and matching span content. To address the limitations of content matching, we introduce LogitMatch, a new constrained decoding method that forces the model's output to align with valid input spans. We evaluate all methods across four diverse tasks. We find that while tagging remains a robust baseline, LogitMatch improves upon competitive matching-based methods by eliminating span matching issues and outperforms other strategies in some setups.
Large Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
Teaching LLMs at Charles University: Assignments and Activities
Jul 29, 2024This paper presents teaching materials, particularly assignments and ideas for classroom activities, from a new course on large language models (LLMs) taught at Charles University. The assignments include experiments with LLM inference for weather report generation and machine translation. The classroom activities include class quizzes, focused research on downstream tasks and datasets, and an interactive "best paper" session aimed at reading and comprehension of research papers.
factgenie: A Framework for Span-based Evaluation of Generated Texts
Jul 25, 2024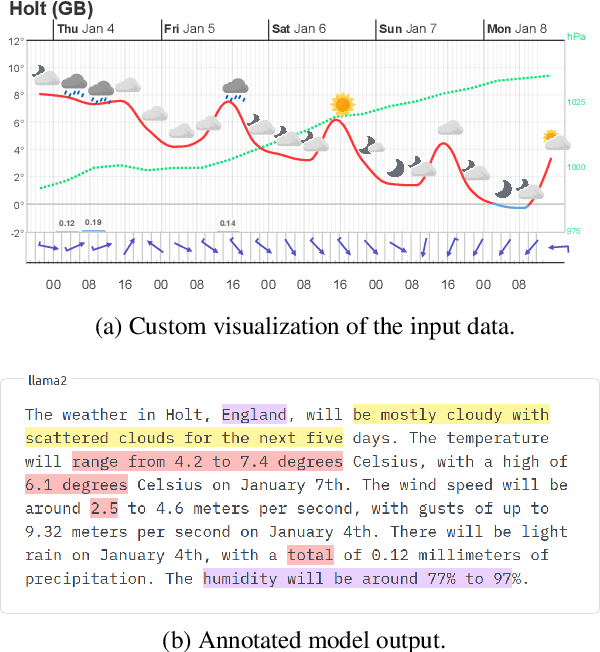
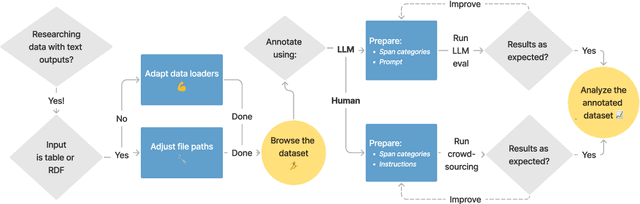
We present factgenie: a framework for annotating and visualizing word spans in textual model outputs. Annotations can capture various span-based phenomena such as semantic inaccuracies or irrelevant text. With factgenie, the annotations can be collected both from human crowdworkers and large language models. Our framework consists of a web interface for data visualization and gathering text annotations, powered by an easily extensible codebase.
WebLINX: Real-World Website Navigation with Multi-Turn Dialogue
Feb 08, 2024We propose the problem of conversational web navigation, where a digital agent controls a web browser and follows user instructions to solve real-world tasks in a multi-turn dialogue fashion. To support this problem, we introduce WEBLINX - a large-scale benchmark of 100K interactions across 2300 expert demonstrations of conversational web navigation. Our benchmark covers a broad range of patterns on over 150 real-world websites and can be used to train and evaluate agents in diverse scenarios. Due to the magnitude of information present, Large Language Models (LLMs) cannot process entire web pages in real-time. To solve this bottleneck, we design a retrieval-inspired model that efficiently prunes HTML pages by ranking relevant elements. We use the selected elements, along with screenshots and action history, to assess a variety of models for their ability to replicate human behavior when navigating the web. Our experiments span from small text-only to proprietary multimodal LLMs. We find that smaller finetuned decoders surpass the best zero-shot LLMs (including GPT-4V), but also larger finetuned multimodal models which were explicitly pretrained on screenshots. However, all finetuned models struggle to generalize to unseen websites. Our findings highlight the need for large multimodal models that can generalize to novel settings. Our code, data and models are available for research: https://mcgill-nlp.github.io/weblinx
Beyond Reference-Based Metrics: Analyzing Behaviors of Open LLMs on Data-to-Text Generation
Jan 18, 2024We investigate to which extent open large language models (LLMs) can generate coherent and relevant text from structured data. To prevent bias from benchmarks leaked into LLM training data, we collect Quintd-1: an ad-hoc benchmark for five data-to-text (D2T) generation tasks, consisting of structured data records in standard formats gathered from public APIs. We leverage reference-free evaluation metrics and LLMs' in-context learning capabilities, allowing us to test the models with no human-written references. Our evaluation focuses on annotating semantic accuracy errors on token-level, combining human annotators and a metric based on GPT-4. Our systematic examination of the models' behavior across domains and tasks suggests that state-of-the-art open LLMs with 7B parameters can generate fluent and coherent text from various standard data formats in zero-shot settings. However, we also show that semantic accuracy of the outputs remains a major issue: on our benchmark, 80% of outputs of open LLMs contain a semantic error according to human annotators (91% according to GPT-4). Our code, data, and model outputs are available at https://d2t-llm.github.io.
Balancing the Style-Content Trade-Off in Sentiment Transfer Using Polarity-Aware Denoising
Dec 22, 2023Text sentiment transfer aims to flip the sentiment polarity of a sentence (positive to negative or vice versa) while preserving its sentiment-independent content. Although current models show good results at changing the sentiment, content preservation in transferred sentences is insufficient. In this paper, we present a sentiment transfer model based on polarity-aware denoising, which accurately controls the sentiment attributes in generated text, preserving the content to a great extent and helping to balance the style-content trade-off. Our proposed model is structured around two key stages in the sentiment transfer process: better representation learning using a shared encoder and sentiment-controlled generation using separate sentiment-specific decoders. Empirical results show that our methods outperforms state-of-the-art baselines in terms of content preservation while staying competitive in terms of style transfer accuracy and fluency.
TabGenie: A Toolkit for Table-to-Text Generation
Feb 27, 2023Heterogenity of data-to-text generation datasets limits the research on data-to-text generation systems. We present TabGenie - a toolkit which enables researchers to explore, preprocess, and analyze a variety of data-to-text generation datasets through the unified framework of table-to-text generation. In TabGenie, all the inputs are represented as tables with associated metadata. The tables can be explored through the web interface, which also provides an interactive mode for debugging table-to-text generation, facilitates side-by-side comparison of generated system outputs, and allows easy exports for manual analysis. Furthermore, TabGenie is equipped with command line processing tools and Python bindings for unified dataset loading and processing. We release TabGenie as a PyPI package and provide its open-source code and a live demo at https://github.com/kasnerz/tabgenie.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Mind the Labels: Describing Relations in Knowledge Graphs With Pretrained Models
Oct 13, 2022



Pretrained language models (PLMs) for data-to-text (D2T) generation can use human-readable data labels such as column headings, keys, or relation names to generalize to out-of-domain examples. However, the models are well-known in producing semantically inaccurate outputs if these labels are ambiguous or incomplete, which is often the case in D2T datasets. In this paper, we expose this issue on the task of descibing a relation between two entities. For our experiments, we collect a novel dataset for verbalizing a diverse set of 1,522 unique relations from three large-scale knowledge graphs (Wikidata, DBPedia, YAGO). We find that although PLMs for D2T generation expectedly fail on unclear cases, models trained with a large variety of relation labels are surprisingly robust in verbalizing novel, unseen relations. We argue that using data with a diverse set of clear and meaningful labels is key to training D2T generation systems capable of generalizing to novel domains.