 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Labelling of Speech Translation Errors
Jun 04, 2026Errors in speech translations reduce trustworthiness of Speech Translation (ST) systems and can have serious consequences. Yet currently there is no established methodology for evaluating confidence and quality estimation of speech translations. To initiate progress in this direction, we propose Speech Translation Error Labelling (STEL). We create an annotation protocol, a small authentic end-to-end evaluation dataset, and we analyse how existing text-only and speech-processing systems perform the STEL task. Our results show that text-only XCOMET and multimodal LLM Qwen2.5-Omni are able to perform the STEL task in roughly half the precision of humans. We also find that direct speech processing is necessary for the STEL task, and that the current text-only and speech-processing systems are complementary in labelling translation-only vs. speech-processing errors in ST.
AlignAtt4LLM: Fast AlignAtt for Decoder-Only LLMs at IWSLT 2026 Simultaneous Speech Translation Task
Jun 02, 2026We describe AlignAtt4LLM, an IWSLT 2026 simultaneous speech translation system for English to German, Italian, and Chinese. The system is a synchronous cascade: Qwen3-ASR with forced alignment produces an incrementally updated source transcript, and Gemma-4 E4B-it translates that prefix under an MT-side AlignAtt policy. To our knowledge, this is the first application of AlignAtt to a decoder-only LLM, where the encoder-decoder cross-attention used by earlier AlignAtt systems is absent. We recover a usable policy by proposing (1) an explicit source span in the prompt, (2) offline selection of translation-specific alignment heads, (3) selective qk-fast replay of the draft-to-source attention block, and (4) runtime query/key capture that preserves model outputs bit-identically. On the IWSLT 2026 development set, AlignAtt4LLM outperforms the supplied baselines for the European target languages, English to German and English to Italian, in both the low-latency regime around 2 seconds and the high-latency regime below 4 seconds CU-LongYAAL. Results for English to Chinese are more mixed, but the method is not tied to Gemma-4: because AlignAtt4LLM only requires a deterministic prompt layout, calibrated attention heads, and query/key capture, the same policy can be reapplied to stronger translation-focused decoder-only MT backbones for non-European target languages.
A Pocket Offline Model for Simultaneous Speech Translation as CUNI Submission to IWSLT 2026
Jun 02, 2026We implement simultaneous translation capability with the offline direct speech-to-text translation model Canary, using the state-of-the-art policy AlignAtt, and submit it to IWSLT 2026 Simultaneous Speech Translation Shared task for Czech to English and English to German and Italian. The strengths of our system are: (1) high translation quality, outperforming similarly sized baselines both in low- and high-latency regimes in computationally unaware simulations; (2) low computational requirements, as the model has only 1B parameters; (3) multilinguality -- support of 25 source and 25 target languages.
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025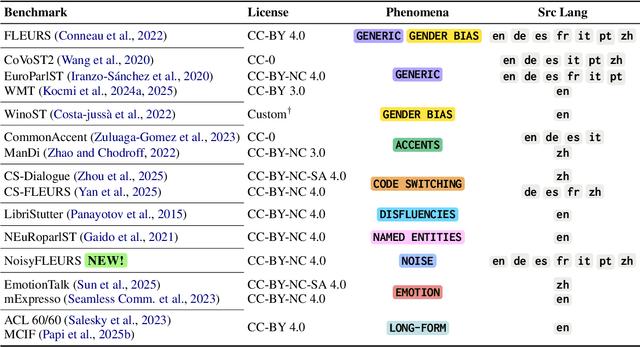
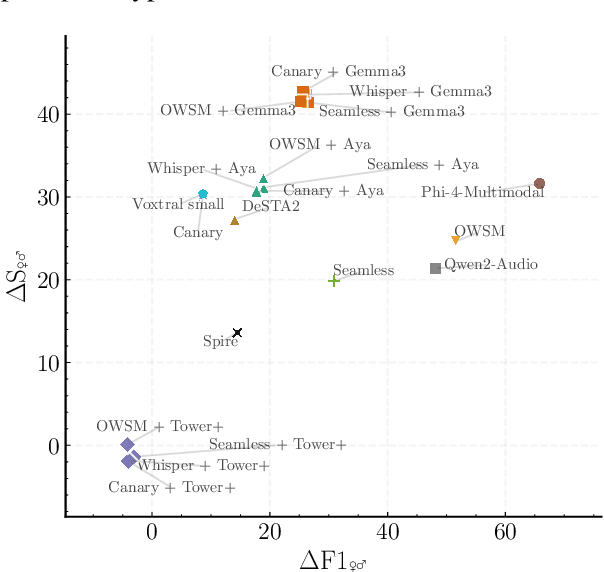
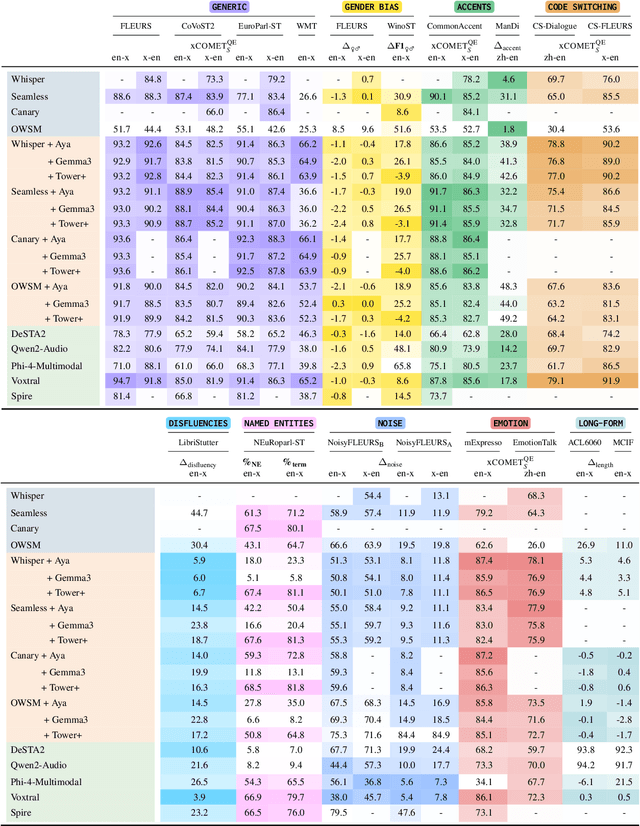
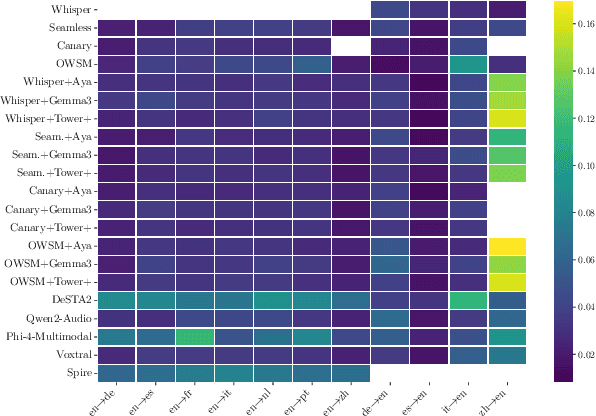
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
Corpus of Cross-lingual Dialogues with Minutes and Detection of Misunderstandings
Dec 23, 2025Speech processing and translation technology have the potential to facilitate meetings of individuals who do not share any common language. To evaluate automatic systems for such a task, a versatile and realistic evaluation corpus is needed. Therefore, we create and present a corpus of cross-lingual dialogues between individuals without a common language who were facilitated by automatic simultaneous speech translation. The corpus consists of 5 hours of speech recordings with ASR and gold transcripts in 12 original languages and automatic and corrected translations into English. For the purposes of research into cross-lingual summarization, our corpus also includes written summaries (minutes) of the meetings. Moreover, we propose automatic detection of misunderstandings. For an overview of this task and its complexity, we attempt to quantify misunderstandings in cross-lingual meetings. We annotate misunderstandings manually and also test the ability of current large language models to detect them automatically. The results show that the Gemini model is able to identify text spans with misunderstandings with recall of 77% and precision of 47%.
* 12 pages, 2 figures, 6 tables, published as a conference paper in Text, Speech, and Dialogue 28th International Conference, TSD 2025, Erlangen, Germany, August 25-28, 2025, Proceedings, Part II. This version published here on arXiv.org is before review comments and seedings of the TSD conference staff
How "Real" is Your Real-Time Simultaneous Speech-to-Text Translation System?
Dec 24, 2024



Simultaneous speech-to-text translation (SimulST) translates source-language speech into target-language text concurrently with the speaker's speech, ensuring low latency for better user comprehension. Despite its intended application to unbounded speech, most research has focused on human pre-segmented speech, simplifying the task and overlooking significant challenges. This narrow focus, coupled with widespread terminological inconsistencies, is limiting the applicability of research outcomes to real-world applications, ultimately hindering progress in the field. Our extensive literature review of 110 papers not only reveals these critical issues in current research but also serves as the foundation for our key contributions. We 1) define the steps and core components of a SimulST system, proposing a standardized terminology and taxonomy; 2) conduct a thorough analysis of community trends, and 3) offer concrete recommendations and future directions to bridge the gaps in existing literature, from evaluation frameworks to system architectures, for advancing the field towards more realistic and effective SimulST solutions.
Teaching LLMs at Charles University: Assignments and Activities
Jul 29, 2024This paper presents teaching materials, particularly assignments and ideas for classroom activities, from a new course on large language models (LLMs) taught at Charles University. The assignments include experiments with LLM inference for weather report generation and machine translation. The classroom activities include class quizzes, focused research on downstream tasks and datasets, and an interactive "best paper" session aimed at reading and comprehension of research papers.
Turning Whisper into Real-Time Transcription System
Jul 27, 2023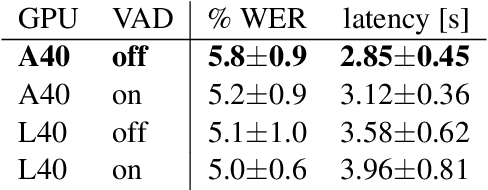



Whisper is one of the recent state-of-the-art multilingual speech recognition and translation models, however, it is not designed for real time transcription. In this paper, we build on top of Whisper and create Whisper-Streaming, an implementation of real-time speech transcription and translation of Whisper-like models. Whisper-Streaming uses local agreement policy with self-adaptive latency to enable streaming transcription. We show that Whisper-Streaming achieves high quality and 3.3 seconds latency on unsegmented long-form speech transcription test set, and we demonstrate its robustness and practical usability as a component in live transcription service at a multilingual conference.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
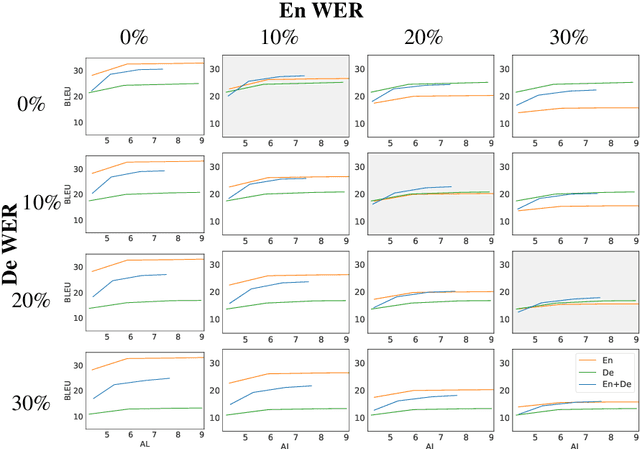


Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
MT Metrics Correlate with Human Ratings of Simultaneous Speech Translation
Nov 16, 2022
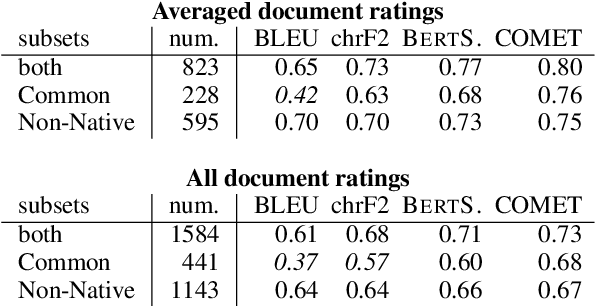


There have been several studies on the correlation between human ratings and metrics such as BLEU, chrF2 and COMET in machine translation. Most, if not all consider full-sentence translation. It is unclear whether human ratings of simultaneous speech translation Continuous Rating (CR) correlate with these metrics or not. Therefore, we conduct an extensive correlation analysis of CR and the aforementioned automatic metrics on evaluations of candidate systems at English-German simultaneous speech translation task at IWSLT 2022. Our studies reveal that the offline MT metrics correlate with CR and can be reliably used for evaluating machine translation in the simultaneous mode, with some limitations on the test set size. This implies that automatic metrics can be used as proxies for CR, thereby alleviating the need for human evaluation.