 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT Metrics Correlate with Human Ratings of Simultaneous Speech Translation
Paper and Code

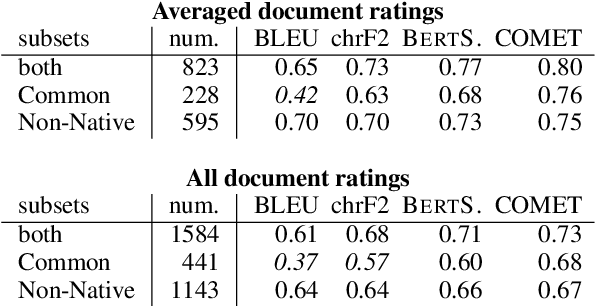


There have been several studies on the correlation between human ratings and metrics such as BLEU, chrF2 and COMET in machine translation. Most, if not all consider full-sentence translation. It is unclear whether human ratings of simultaneous speech translation Continuous Rating (CR) correlate with these metrics or not. Therefore, we conduct an extensive correlation analysis of CR and the aforementioned automatic metrics on evaluations of candidate systems at English-German simultaneous speech translation task at IWSLT 2022. Our studies reveal that the offline MT metrics correlate with CR and can be reliably used for evaluating machine translation in the simultaneous mode, with some limitations on the test set size. This implies that automatic metrics can be used as proxies for CR, thereby alleviating the need for human evaluation.