 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024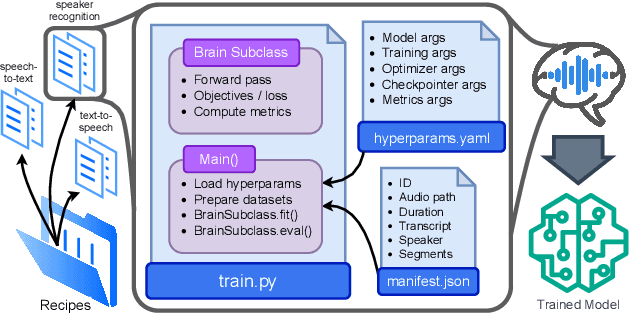

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
RescueSpeech: A German Corpus for Speech Recognition in Search and Rescue Domain
Jun 06, 2023



Despite recent advancements in speech recognition, there are still difficulties in accurately transcribing conversational and emotional speech in noisy and reverberant acoustic environments. This poses a particular challenge in the search and rescue (SAR) domain, where transcribing conversations among rescue team members is crucial to support real-time decision-making. The scarcity of speech data and associated background noise in SAR scenarios make it difficult to deploy robust speech recognition systems. To address this issue, we have created and made publicly available a German speech dataset called RescueSpeech. This dataset includes real speech recordings from simulated rescue exercises. Additionally, we have released competitive training recipes and pre-trained models. Our study indicates that the current level of performance achieved by state-of-the-art methods is still far from being acceptable.
Defending Against Stealthy Backdoor Attacks
May 27, 2022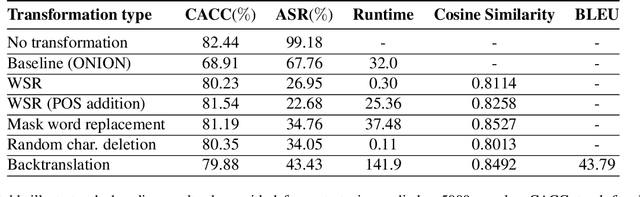
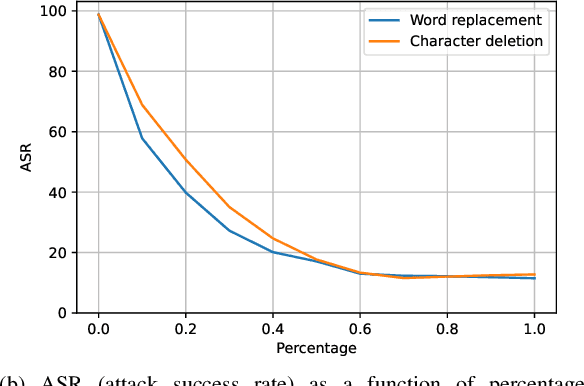

Defenses against security threats have been an interest of recent studies. Recent works have shown that it is not difficult to attack a natural language processing (NLP) model while defending against them is still a cat-mouse game. Backdoor attacks are one such attack where a neural network is made to perform in a certain way on specific samples containing some triggers while achieving normal results on other samples. In this work, we present a few defense strategies that can be useful to counter against such an attack. We show that our defense methodologies significantly decrease the performance on the attacked inputs while maintaining similar performance on benign inputs. We also show that some of our defenses have very less runtime and also maintain similarity with the original inputs.
Bayesian multilingual topic model for zero-shot cross-lingual topic identification
Jul 02, 2020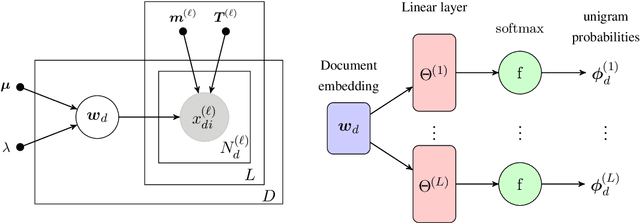


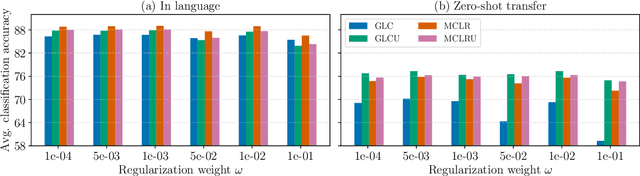
This paper presents a Bayesian multilingual topic model for learning language-independent document embeddings. Our model learns to represent the documents in the form of Gaussian distributions, thereby encoding the uncertainty in its covariance. We propagate the learned uncertainties through linear classifiers for zero-shot cross-lingual topic identification. Our experiments on 5 language Europarl and Reuters (MLDoc) corpora show that the proposed model outperforms multi-lingual word embedding and BiLSTM sentence encoder based systems with significant margins in the majority of the transfer directions. Moreover, our system trained under a single day on a single GPU with much lower amounts of data performs competitively as compared to the state-of-the-art universal BiLSTM sentence encoder trained on 93 languages. Our experimental analysis shows that the amount of parallel data improves the overall performance of embeddings. Nonetheless, exploiting the uncertainties is always beneficial.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020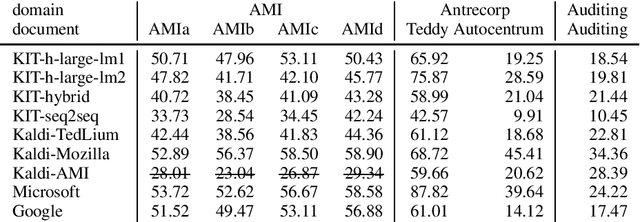
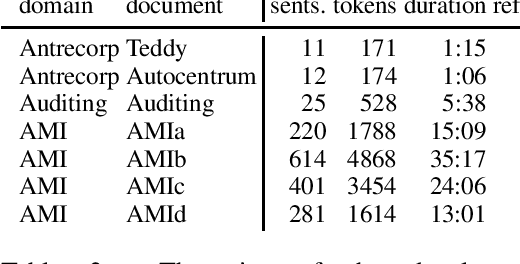
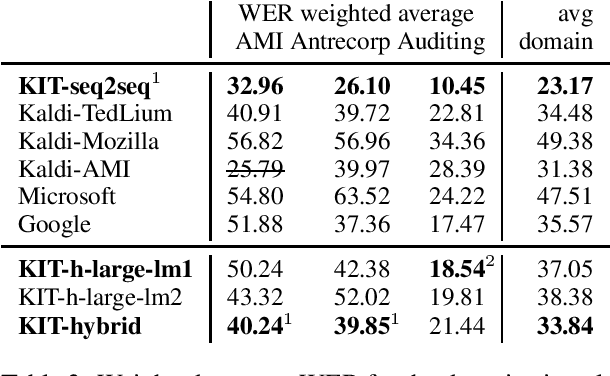

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.