 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stage Large Language Model Correction for Speech Recognition
Oct 17, 2023



In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from traditional language models that focus on one single data domain, the rise of LLMs brings us the opportunity to push the limit of state-of-the-art ASR performance, and at the same time to achieve higher robustness and generalize effectively across multiple domains. Motivated by this, we propose a novel multi-stage approach to combine traditional language model re-scoring and LLM prompting. Specifically, the proposed method has two stages: the first stage uses a language model to re-score an N-best list of ASR hypotheses and run a confidence check; The second stage uses prompts to a LLM to perform ASR error correction on less confident results from the first stage. Our experimental results demonstrate the effectiveness of the proposed method by showing a 10% ~ 20% relative improvement in WER over a competitive ASR system -- across multiple test domains.
Super-Human Performance in Online Low-latency Recognition of Conversational Speech
Oct 22, 2020

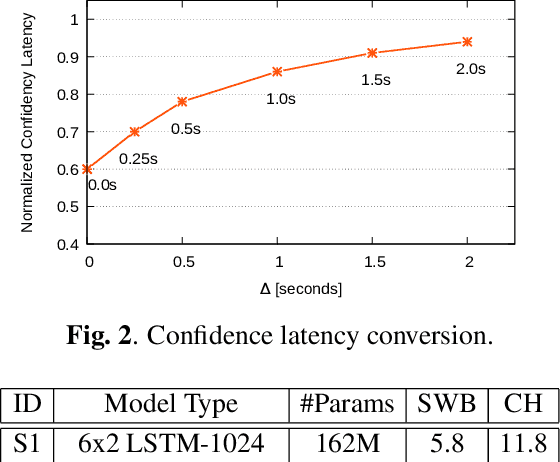
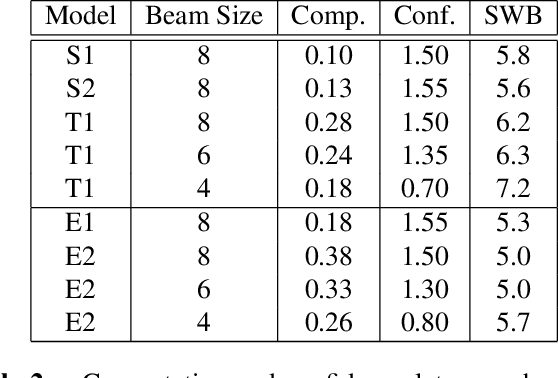
Achieving super-human performance in recognizing human speech has been a goal for several decades, as researchers have worked on increasingly challenging tasks. In the 1990's it was discovered, that conversational speech between two humans turns out to be considerably more difficult than read speech as hesitations, disfluencies, false starts and sloppy articulation complicate acoustic processing and require robust handling of acoustic, lexical and language context, jointly. Early attempts with statistical models could only reach error rates over 50% and far from human performance (WER of around 5.5%). Neural hybrid models and recent attention-based encoder-decoder models have considerably improved performance as such contexts can now be learned in an integral fashion. However, processing such contexts requires an entire utterance presentation and thus introduces unwanted delays before a recognition result can be output. In this paper, we address performance as well as latency. We present results for a system that can achieve super-human performance (at a WER of 5.0%, over the Switchboard conversational benchmark) at a word based latency of only 1 second behind a speaker's speech. The system uses multiple attention-based encoder-decoder networks integrated within a novel low latency incremental inference approach.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020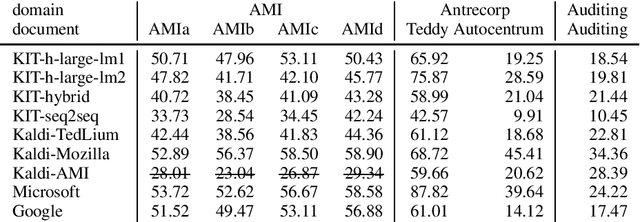
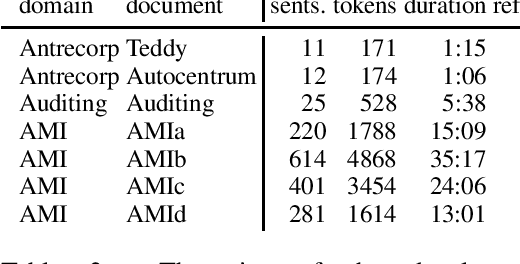
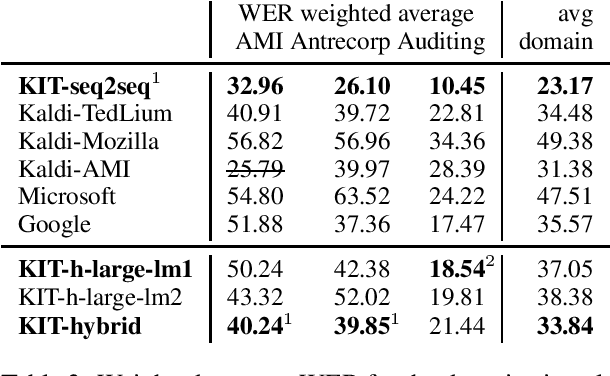

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020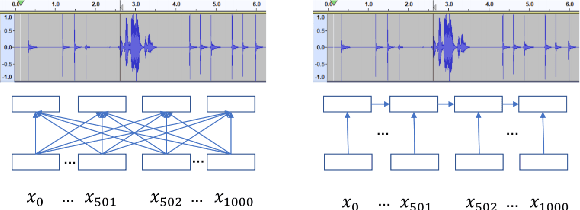
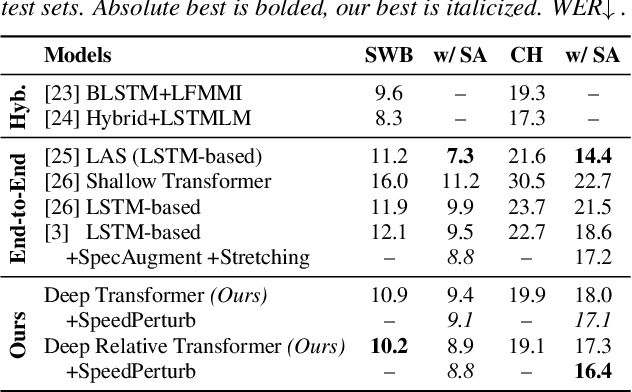


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.
High Performance Sequence-to-Sequence Model for Streaming Speech Recognition
Mar 22, 2020
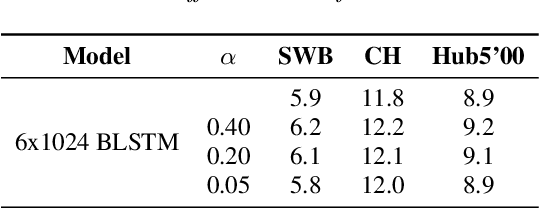


Recently sequence-to-sequence models have started to achieve state-of-the art performance on standard speech recognition tasks when processing audio data in batch mode, i.e., the complete audio data is available when starting processing. However, when it comes to perform run-on recognition on an input stream of audio data while producing recognition results in real-time and with a low word-based latency, these models face several challenges. For many techniques, the whole audio sequence to be decoded needs to be available at the start of the processing, e.g., for the attention mechanism or for the bidirectional LSTM (BLSTM). In this paper we propose several techniques to mitigate these problems. We introduce an additional loss function controlling the uncertainty of the attention mechanism, a modified beam search identifying partial, stable hypotheses, ways of working with BLSTM in the encoder, and the use of chunked BLSTM. Our experiments show that with the right combination of these techniques it is possible to perform run-on speech recognition with a low word-based latency without sacrificing performance in terms of word error rate.
Toward Cross-Domain Speech Recognition with End-to-End Models
Mar 09, 2020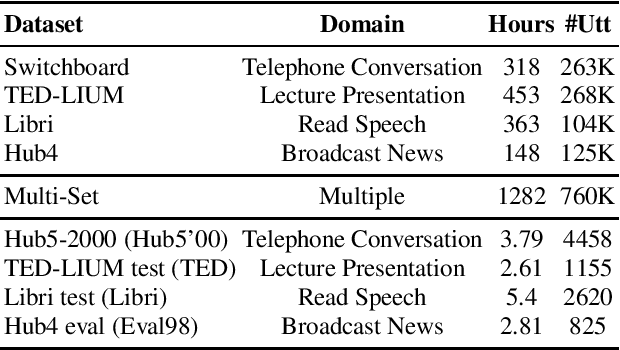
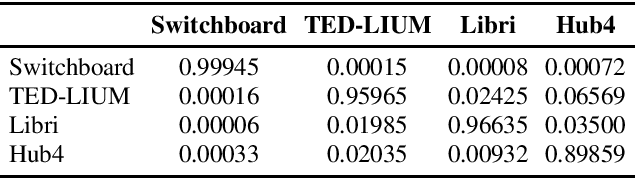
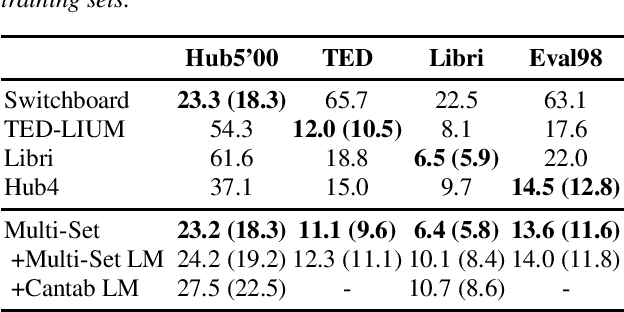
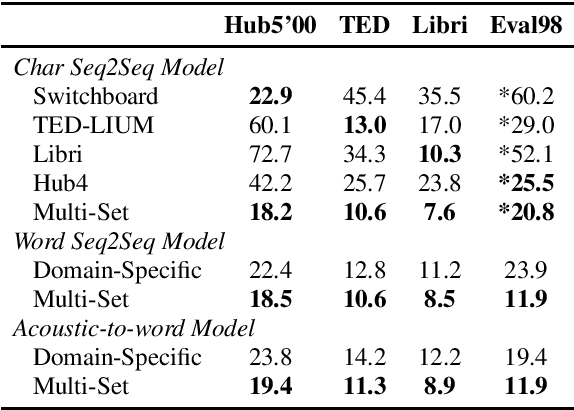
In the area of multi-domain speech recognition, research in the past focused on hybrid acoustic models to build cross-domain and domain-invariant speech recognition systems. In this paper, we empirically examine the difference in behavior between hybrid acoustic models and neural end-to-end systems when mixing acoustic training data from several domains. For these experiments we composed a multi-domain dataset from public sources, with the different domains in the corpus covering a wide variety of topics and acoustic conditions such as telephone conversations, lectures, read speech and broadcast news. We show that for the hybrid models, supplying additional training data from other domains with mismatched acoustic conditions does not increase the performance on specific domains. However, our end-to-end models optimized with sequence-based criterion generalize better than the hybrid models on diverse domains. In term of word-error-rate performance, our experimental acoustic-to-word and attention-based models trained on multi-domain dataset reach the performance of domain-specific long short-term memory (LSTM) hybrid models, thus resulting in multi-domain speech recognition systems that do not suffer in performance over domain specific ones. Moreover, the use of neural end-to-end models eliminates the need of domain-adapted language models during recognition, which is a great advantage when the input domain is unknown.
Improving sequence-to-sequence speech recognition training with on-the-fly data augmentation
Oct 29, 2019
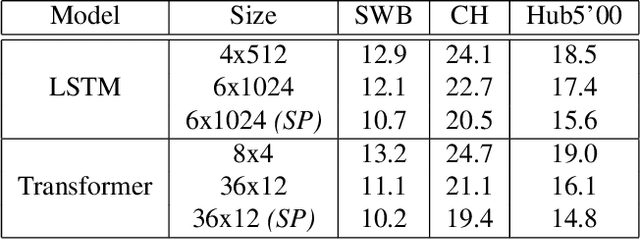
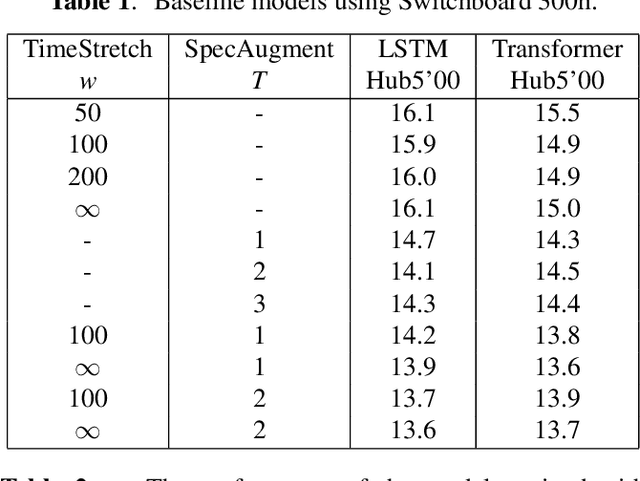
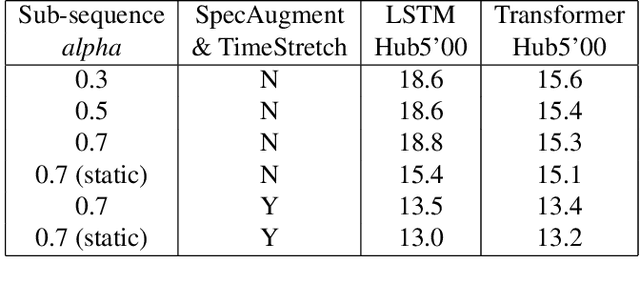
Sequence-to-Sequence (S2S) models recently started to show state-of-the-art performance for automatic speech recognition (ASR). With these large and deep models overfitting remains the largest problem, outweighing performance improvements that can be obtained from better architectures. One solution to the overfitting problem is increasing the amount of available training data and the variety exhibited by the training data with the help of data augmentation. In this paper we examine the influence of three data augmentation methods on the performance of two S2S model architectures. One of the data augmentation method comes from literature, while two other methods are our own development - a time perturbation in the frequency domain and sub-sequence sampling. Our experiments on Switchboard and Fisher data show state-of-the-art performance for S2S models that are trained solely on the speech training data and do not use additional text data.
Very Deep Self-Attention Networks for End-to-End Speech Recognition
May 03, 2019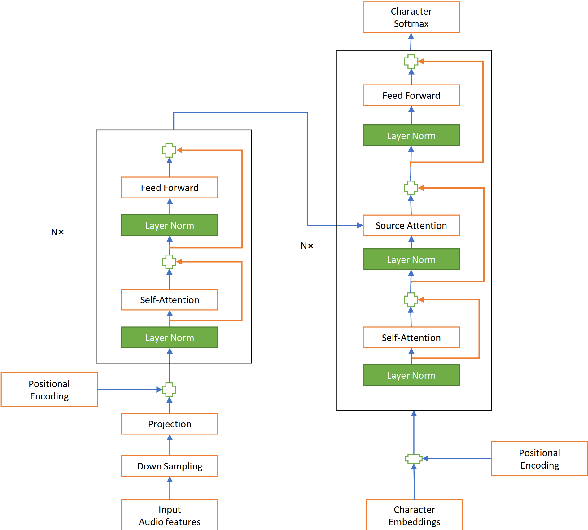
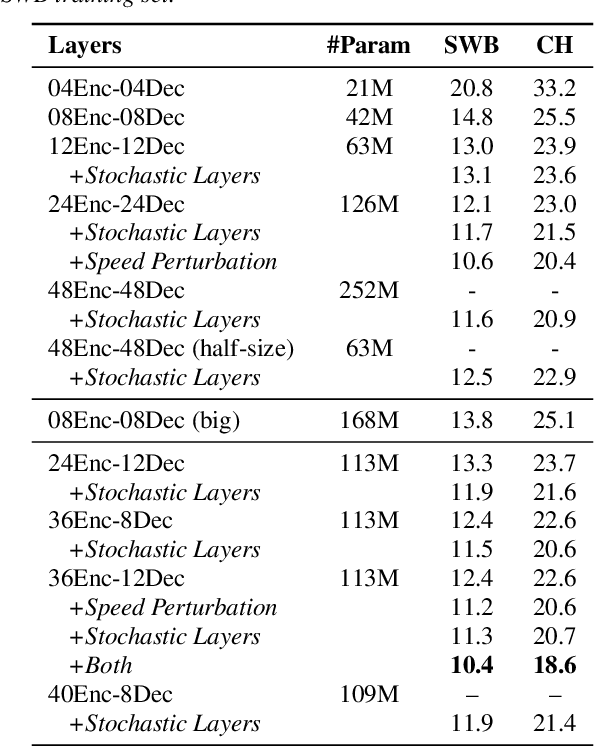
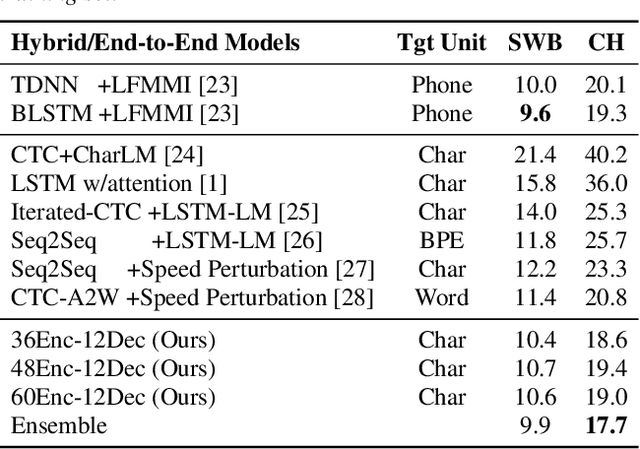

Recently, end-to-end sequence-to-sequence models for speech recognition have gained significant interest in the research community. While previous architecture choices revolve around time-delay neural networks (TDNN) and long short-term memory (LSTM) recurrent neural networks, we propose to use self-attention via the Transformer architecture as an alternative. Our analysis shows that deep Transformer networks with high learning capacity are able to exceed performance from previous end-to-end approaches and even match the conventional hybrid systems. Moreover, we trained very deep models with up to 48 Transformer layers for both encoder and decoders combined with stochastic residual connections, which greatly improve generalizability and training efficiency. The resulting models outperform all previous end-to-end ASR approaches on the Switchboard benchmark. An ensemble of these models achieve 9.9% and 17.7% WER on Switchboard and CallHome test sets respectively. This finding brings our end-to-end models to competitive levels with previous hybrid systems. Further, with model ensembling the Transformers can outperform certain hybrid systems, which are more complicated in terms of both structure and training procedure.
Learning Shared Encoding Representation for End-to-End Speech Recognition Models
Mar 31, 2019


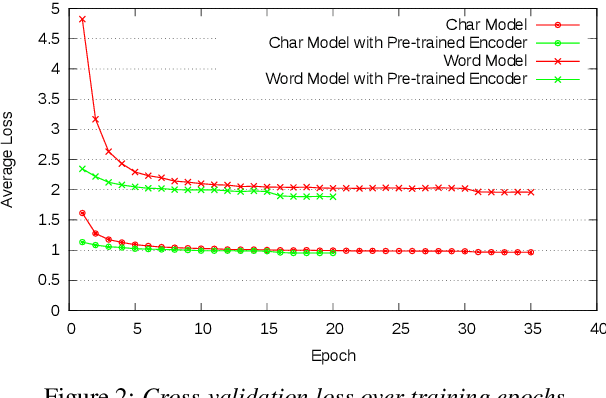
In this work, we learn a shared encoding representation for a multi-task neural network model optimized with connectionist temporal classification (CTC) and conventional framewise cross-entropy training criteria. Our experiments show that the multi-task training not only tackles the complexity of optimizing CTC models such as acoustic-to-word but also results in significant improvement compared to the plain-task training with an optimal setup. Furthermore, we propose to use the encoding representation learned by the multi-task network to initialize the encoder of attention-based models. Thereby, we train a deep attention-based end-to-end model with 10 long short-term memory (LSTM) layers of encoder which produces 12.2\% and 22.6\% word-error-rate on Switchboard and CallHome subsets of the Hub5 2000 evaluation.
Using multi-task learning to improve the performance of acoustic-to-word and conventional hybrid models
Feb 02, 2019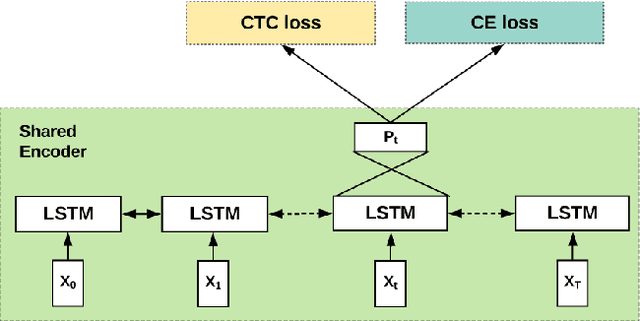
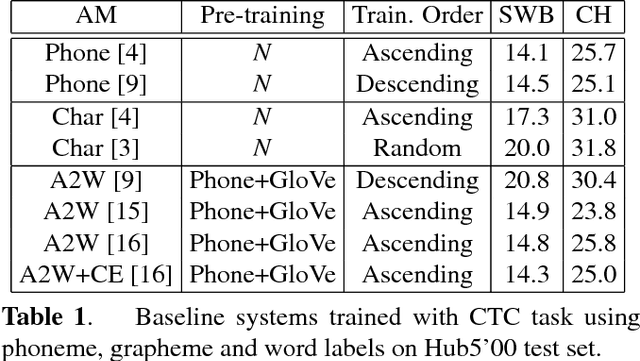
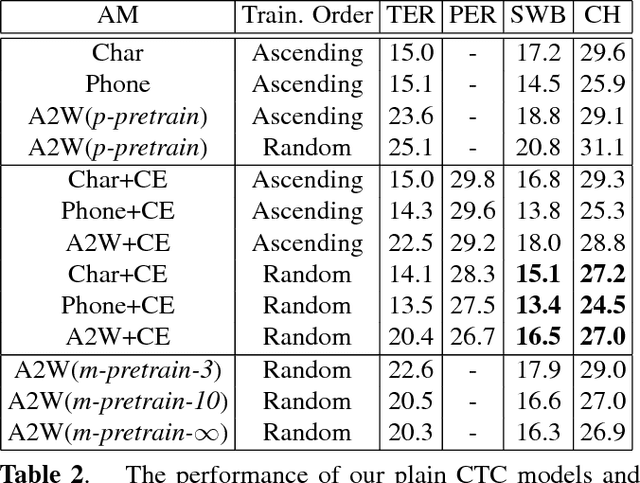
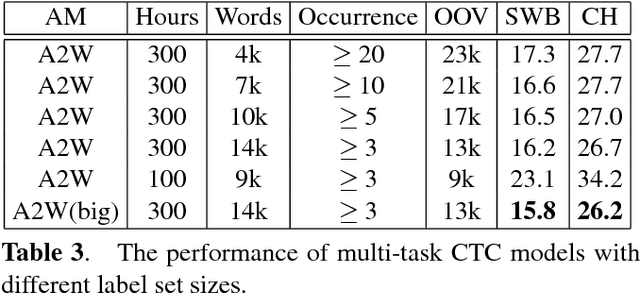
Acoustic-to-word (A2W) models that allow direct mapping from acoustic signals to word sequences are an appealing approach to end-to-end automatic speech recognition due to their simplicity. However, prior works have shown that modelling A2W typically encounters issues of data sparsity that prevent training such a model directly. So far, pre-training initialization is the only approach proposed to deal with this issue. In this work, we propose to build a shared neural network and optimize A2W and conventional hybrid models in a multi-task manner. Our results show that training an A2W model is much more stable with our multi-task model without pre-training initialization, and results in a significant improvement compared to a baseline model. Experiments also reveal that the performance of a hybrid acoustic model can be further improved when jointly training with a sequence-level optimization criterion such as acoustic-to-word.