 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Classifying UTI Risk Groups Using a Real-World Linked EHR and Pathology Lab Dataset
Nov 26, 2024



The use of machine learning and AI on electronic health records (EHRs) holds substantial potential for clinical insight. However, this approach faces significant challenges due to data heterogeneity, sparsity, temporal misalignment, and limited labeled outcomes. In this context, we leverage a linked EHR dataset of approximately one million de-identified individuals from Bristol, North Somerset, and South Gloucestershire, UK, to characterize urinary tract infections (UTIs) and develop predictive models focused on data quality, fairness and transparency. A comprehensive data pre-processing and curation pipeline transforms the raw EHR data into a structured format suitable for AI modeling. Given the limited availability and biases of ground truth UTI outcomes, we introduce a UTI risk estimation framework informed by clinical expertise to estimate UTI risk across individual patient timelines. Using this framework, we built pairwise XGBoost models to differentiate UTI risk categories with explainable AI techniques to identify key predictors while ensuring interpretability. Our findings reveal differences in clinical and demographic factors across risk groups, offering insights into UTI risk stratification and progression. This study demonstrates the added value of AI-driven insights into UTI clinical decision-making while prioritizing interpretability, transparency, and fairness, underscoring the importance of sound data practices in advancing health outcomes.
The ELITR ECA Corpus
Sep 15, 2021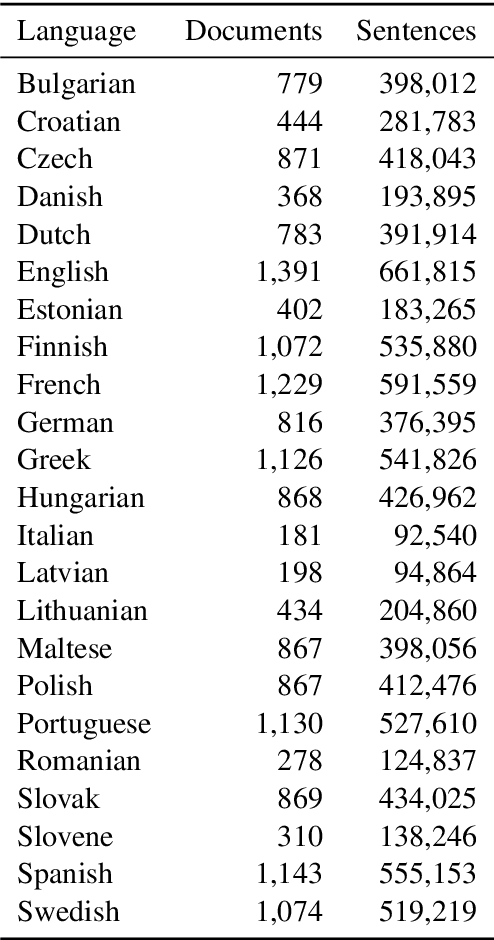

We present the ELITR ECA corpus, a multilingual corpus derived from publications of the European Court of Auditors. We use automatic translation together with Bleualign to identify parallel sentence pairs in all 506 translation directions. The result is a corpus comprising 264k document pairs and 41.9M sentence pairs.
ELITR Non-Native Speech Translation at IWSLT 2020
Jun 05, 2020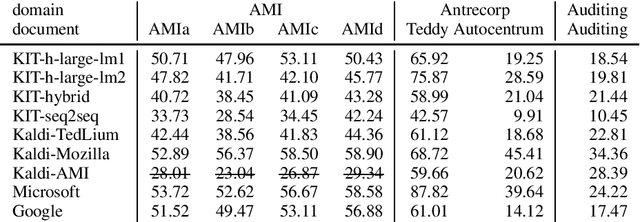
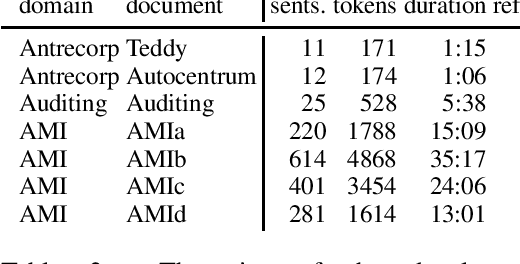
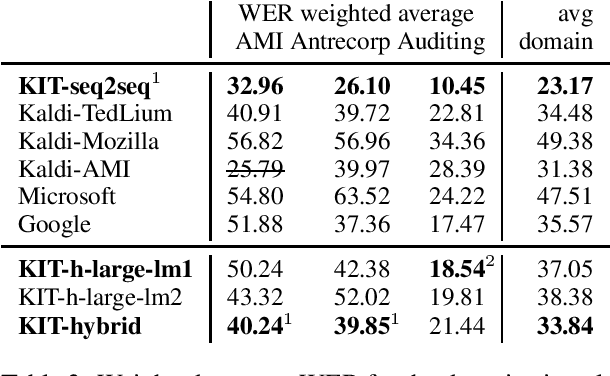

This paper is an ELITR system submission for the non-native speech translation task at IWSLT 2020. We describe systems for offline ASR, real-time ASR, and our cascaded approach to offline SLT and real-time SLT. We select our primary candidates from a pool of pre-existing systems, develop a new end-to-end general ASR system, and a hybrid ASR trained on non-native speech. The provided small validation set prevents us from carrying out a complex validation, but we submit all the unselected candidates for contrastive evaluation on the test set.
Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation
Apr 24, 2020
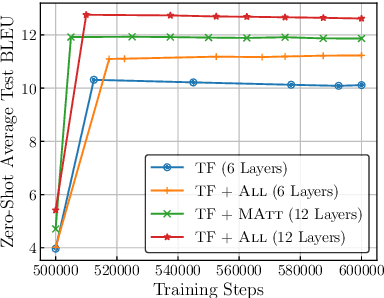

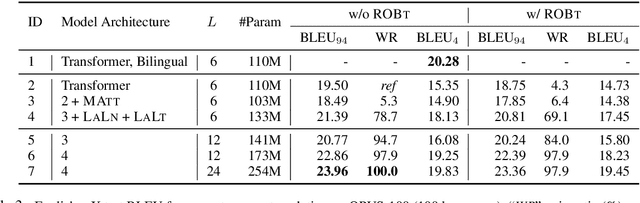
Massively multilingual models for neural machine translation (NMT) are theoretically attractive, but often underperform bilingual models and deliver poor zero-shot translations. In this paper, we explore ways to improve them. We argue that multilingual NMT requires stronger modeling capacity to support language pairs with varying typological characteristics, and overcome this bottleneck via language-specific components and deepening NMT architectures. We identify the off-target translation issue (i.e. translating into a wrong target language) as the major source of the inferior zero-shot performance, and propose random online backtranslation to enforce the translation of unseen training language pairs. Experiments on OPUS-100 (a novel multilingual dataset with 100 languages) show that our approach substantially narrows the performance gap with bilingual models in both one-to-many and many-to-many settings, and improves zero-shot performance by ~10 BLEU, approaching conventional pivot-based methods.
The University of Edinburgh's Neural MT Systems for WMT17
Aug 02, 2017
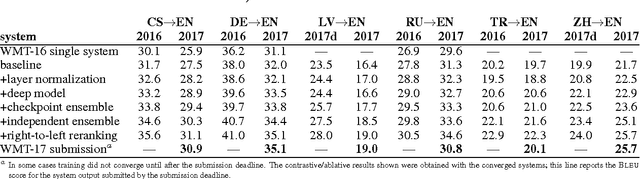
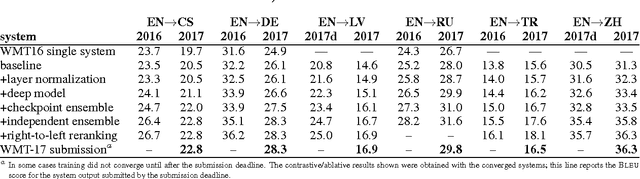
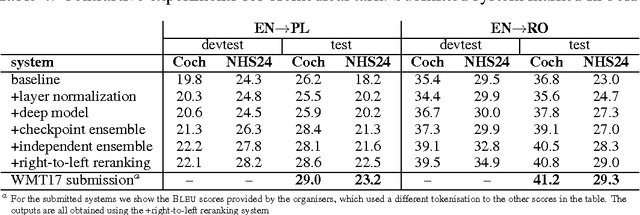
This paper describes the University of Edinburgh's submissions to the WMT17 shared news translation and biomedical translation tasks. We participated in 12 translation directions for news, translating between English and Czech, German, Latvian, Russian, Turkish and Chinese. For the biomedical task we submitted systems for English to Czech, German, Polish and Romanian. Our systems are neural machine translation systems trained with Nematus, an attentional encoder-decoder. We follow our setup from last year and build BPE-based models with parallel and back-translated monolingual training data. Novelties this year include the use of deep architectures, layer normalization, and more compact models due to weight tying and improvements in BPE segmentations. We perform extensive ablative experiments, reporting on the effectivenes of layer normalization, deep architectures, and different ensembling techniques.