Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ELITR ECA Corpus
Paper and Code
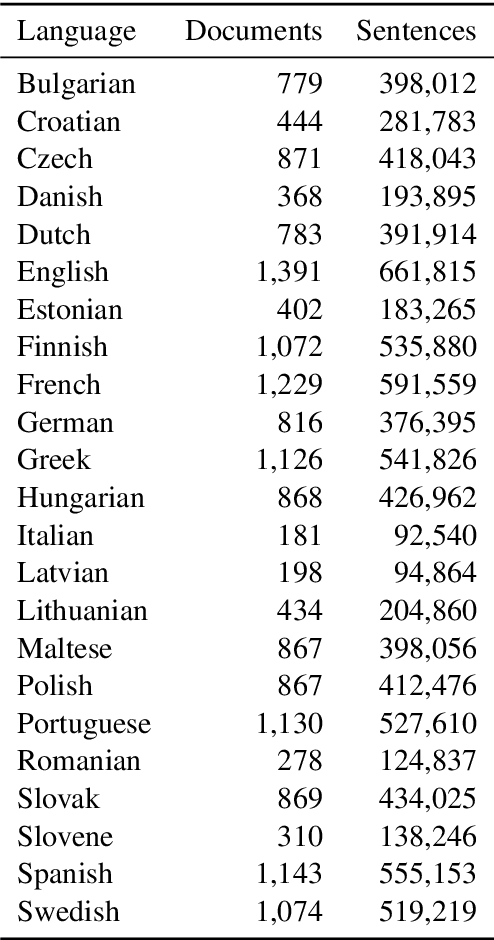

We present the ELITR ECA corpus, a multilingual corpus derived from publications of the European Court of Auditors. We use automatic translation together with Bleualign to identify parallel sentence pairs in all 506 translation directions. The result is a corpus comprising 264k document pairs and 41.9M sentence pairs.
View paper on