 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generation Orders for Masked Discrete Diffusion Models via Variational Inference
Feb 27, 2026Masked discrete diffusion models (MDMs) are a promising new approach to generative modelling, offering the ability for parallel token generation and therefore greater efficiency than autoregressive counterparts. However, achieving an optimal balance between parallel generation and sample quality remains an open problem. Current approaches primarily address this issue through fixed, heuristic parallel sampling methods. There exist some recent learning based approaches to this problem, but its formulation from the perspective of variational inference remains underexplored. In this work, we propose a variational inference framework for learning parallel generation orders for MDMs. As part of our method, we propose a parameterisation for the approximate posterior of generation orders which facilitates parallelism and efficient sampling during training. Using this method, we conduct preliminary experiments on the GSM8K dataset, where our method performs competitively against heuristic sampling strategies in the regime of highly parallel generation. For example, our method achieves 33.1\% accuracy with an average of only only 4 generation steps, compared to 23.7-29.0\% accuracy achieved by standard competitor methods in the same number of steps. We believe further experiments and analysis of the method will yield valuable insights into the problem of parallel generation with MDMs.
LEMON: Local Explanations via Modality-aware OptimizatioN
Feb 02, 2026Multimodal models are ubiquitous, yet existing explainability methods are often single-modal, architecture-dependent, or too computationally expensive to run at scale. We introduce LEMON (Local Explanations via Modality-aware OptimizatioN), a model-agnostic framework for local explanations of multimodal predictions. LEMON fits a single modality-aware surrogate with group-structured sparsity to produce unified explanations that disentangle modality-level contributions and feature-level attributions. The approach treats the predictor as a black box and is computationally efficient, requiring relatively few forward passes while remaining faithful under repeated perturbations. We evaluate LEMON on vision-language question answering and a clinical prediction task with image, text, and tabular inputs, comparing against representative multimodal baselines. Across backbones, LEMON achieves competitive deletion-based faithfulness while reducing black-box evaluations by 35-67 times and runtime by 2-8 times compared to strong multimodal baselines.
KnowEEG: Explainable Knowledge Driven EEG Classification
May 01, 2025



Electroencephalography (EEG) is a method of recording brain activity that shows significant promise in applications ranging from disease classification to emotion detection and brain-computer interfaces. Recent advances in deep learning have improved EEG classification performance yet model explainability remains an issue. To address this key limitation of explainability we introduce KnowEEG; a novel explainable machine learning approach for EEG classification. KnowEEG extracts a comprehensive set of per-electrode features, filters them using statistical tests, and integrates between-electrode connectivity statistics. These features are then input to our modified Random Forest model (Fusion Forest) that balances per electrode statistics with between electrode connectivity features in growing the trees of the forest. By incorporating knowledge from both the generalized time-series and EEG-specific domains, KnowEEG achieves performance comparable to or exceeding state-of-the-art deep learning models across five different classification tasks: emotion detection, mental workload classification, eyes open/closed detection, abnormal EEG classification, and event detection. In addition to high performance, KnowEEG provides inherent explainability through feature importance scores for understandable features. We demonstrate by example on the eyes closed/open classification task that this explainability can be used to discover knowledge about the classes. This discovered knowledge for eyes open/closed classification was proven to be correct by current neuroscience literature. Therefore, the impact of KnowEEG will be significant for domains where EEG explainability is critical such as healthcare.
Prototype-enhanced prediction in graph neural networks for climate applications
Apr 24, 2025


Data-driven emulators are increasingly being used to learn and emulate physics-based simulations, reducing computational expense and run time. Here, we present a structured way to improve the quality of these high-dimensional emulated outputs, through the use of prototypes: an approximation of the emulator's output passed as an input, which informs the model and leads to better predictions. We demonstrate our approach to emulate atmospheric dispersion, key for greenhouse gas emissions monitoring, by comparing a baseline model to models trained using prototypes as an additional input. The prototype models achieve better performance, even with few prototypes and even if they are chosen at random, but we show that choosing the prototypes through data-driven methods (k-means) can lead to almost 10\% increased performance in some metrics.
Explainable AI for Classifying UTI Risk Groups Using a Real-World Linked EHR and Pathology Lab Dataset
Nov 26, 2024



The use of machine learning and AI on electronic health records (EHRs) holds substantial potential for clinical insight. However, this approach faces significant challenges due to data heterogeneity, sparsity, temporal misalignment, and limited labeled outcomes. In this context, we leverage a linked EHR dataset of approximately one million de-identified individuals from Bristol, North Somerset, and South Gloucestershire, UK, to characterize urinary tract infections (UTIs) and develop predictive models focused on data quality, fairness and transparency. A comprehensive data pre-processing and curation pipeline transforms the raw EHR data into a structured format suitable for AI modeling. Given the limited availability and biases of ground truth UTI outcomes, we introduce a UTI risk estimation framework informed by clinical expertise to estimate UTI risk across individual patient timelines. Using this framework, we built pairwise XGBoost models to differentiate UTI risk categories with explainable AI techniques to identify key predictors while ensuring interpretability. Our findings reveal differences in clinical and demographic factors across risk groups, offering insights into UTI risk stratification and progression. This study demonstrates the added value of AI-driven insights into UTI clinical decision-making while prioritizing interpretability, transparency, and fairness, underscoring the importance of sound data practices in advancing health outcomes.
Exploring the Requirements of Clinicians for Explainable AI Decision Support Systems in Intensive Care
Nov 18, 2024There is a growing need to understand how digital systems can support clinical decision-making, particularly as artificial intelligence (AI) models become increasingly complex and less human-interpretable. This complexity raises concerns about trustworthiness, impacting safe and effective adoption of such technologies. Improved understanding of decision-making processes and requirements for explanations coming from decision support tools is a vital component in providing effective explainable solutions. This is particularly relevant in the data-intensive, fast-paced environments of intensive care units (ICUs). To explore these issues, group interviews were conducted with seven ICU clinicians, representing various roles and experience levels. Thematic analysis revealed three core themes: (T1) ICU decision-making relies on a wide range of factors, (T2) the complexity of patient state is challenging for shared decision-making, and (T3) requirements and capabilities of AI decision support systems. We include design recommendations from clinical input, providing insights to inform future AI systems for intensive care.
The Effect of Perceptual Metrics on Music Representation Learning for Genre Classification
Sep 25, 2024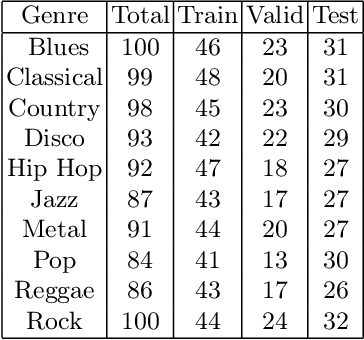
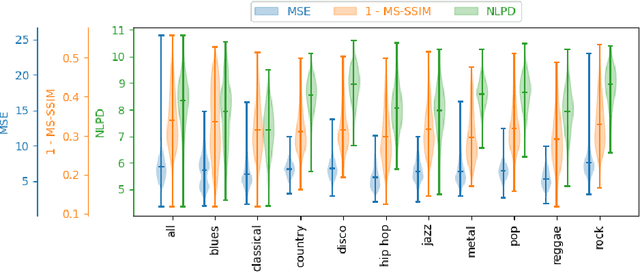
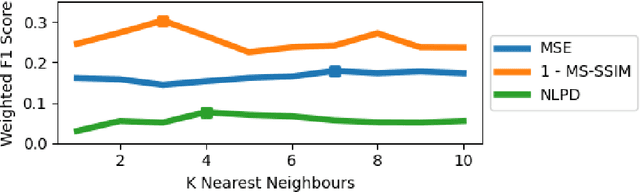
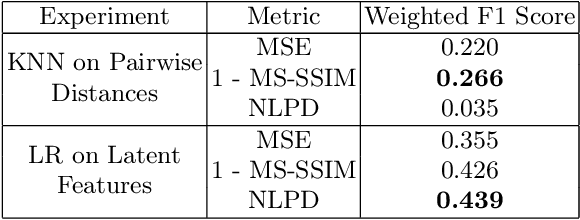
The subjective quality of natural signals can be approximated with objective perceptual metrics. Designed to approximate the perceptual behaviour of human observers, perceptual metrics often reflect structures found in natural signals and neurological pathways. Models trained with perceptual metrics as loss functions can capture perceptually meaningful features from the structures held within these metrics. We demonstrate that using features extracted from autoencoders trained with perceptual losses can improve performance on music understanding tasks, i.e. genre classification, over using these metrics directly as distances when learning a classifier. This result suggests improved generalisation to novel signals when using perceptual metrics as loss functions for representation learning.
Investigating Brain Connectivity and Regional Statistics from EEG for early stage Parkinson's Classification
Aug 01, 2024We evaluate the effectiveness of combining brain connectivity metrics with signal statistics for early stage Parkinson's Disease (PD) classification using electroencephalogram data (EEG). The data is from 5 arousal states - wakeful and four sleep stages (N1, N2, N3 and REM). Our pipeline uses an Ada Boost model for classification on a challenging early stage PD classification task with with only 30 participants (11 PD , 19 Healthy Control). Evaluating 9 brain connectivity metrics we find the best connectivity metric to be different for each arousal state with Phase Lag Index achieving the highest individual classification accuracy of 86\% on N1 data. Further to this our pipeline using regional signal statistics achieves an accuracy of 78\%, using brain connectivity only achieves an accuracy of 86\% whereas combining the two achieves a best accuracy of 91\%. This best performance is achieved on N1 data using Phase Lag Index (PLI) combined with statistics derived from the frequency characteristics of the EEG signal. This model also achieves a recall of 80 \% and precision of 96\%. Furthermore we find that on data from each arousal state, combining PLI with regional signal statistics improves classification accuracy versus using signal statistics or brain connectivity alone. Thus we conclude that combining brain connectivity statistics with regional EEG statistics is optimal for classifier performance on early stage Parkinson's. Additionally, we find outperformance of N1 EEG for classification of Parkinson's and expect this could be due to disrupted N1 sleep in PD. This should be explored in future work.
Towards Personalised Patient Risk Prediction Using Temporal Hospital Data Trajectories
Jul 12, 2024Quantifying a patient's health status provides clinicians with insight into patient risk, and the ability to better triage and manage resources. Early Warning Scores (EWS) are widely deployed to measure overall health status, and risk of adverse outcomes, in hospital patients. However, current EWS are limited both by their lack of personalisation and use of static observations. We propose a pipeline that groups intensive care unit patients by the trajectories of observations data throughout their stay as a basis for the development of personalised risk predictions. Feature importance is considered to provide model explainability. Using the MIMIC-IV dataset, six clusters were identified, capturing differences in disease codes, observations, lengths of admissions and outcomes. Applying the pipeline to data from just the first four hours of each ICU stay assigns the majority of patients to the same cluster as when the entire stay duration is considered. In-hospital mortality prediction models trained on individual clusters had higher F1 score performance in five of the six clusters when compared against the unclustered patient cohort. The pipeline could form the basis of a clinical decision support tool, working to improve the clinical characterisation of risk groups and the early detection of patient deterioration.
Safe and Robust Reinforcement Learning: Principles and Practice
Mar 30, 2024Reinforcement Learning (RL) has shown remarkable success in solving relatively complex tasks, yet the deployment of RL systems in real-world scenarios poses significant challenges related to safety and robustness. This paper aims to identify and further understand those challenges thorough the exploration of the main dimensions of the safe and robust RL landscape, encompassing algorithmic, ethical, and practical considerations. We conduct a comprehensive review of methodologies and open problems that summarizes the efforts in recent years to address the inherent risks associated with RL applications. After discussing and proposing definitions for both safe and robust RL, the paper categorizes existing research works into different algorithmic approaches that enhance the safety and robustness of RL agents. We examine techniques such as uncertainty estimation, optimisation methodologies, exploration-exploitation trade-offs, and adversarial training. Environmental factors, including sim-to-real transfer and domain adaptation, are also scrutinized to understand how RL systems can adapt to diverse and dynamic surroundings. Moreover, human involvement is an integral ingredient of the analysis, acknowledging the broad set of roles that humans can take in this context. Importantly, to aid practitioners in navigating the complexities of safe and robust RL implementation, this paper introduces a practical checklist derived from the synthesized literature. The checklist encompasses critical aspects of algorithm design, training environment considerations, and ethical guidelines. It will serve as a resource for developers and policymakers alike to ensure the responsible deployment of RL systems in many application domains.