 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Perceptual Metrics on Music Representation Learning for Genre Classification
Sep 25, 2024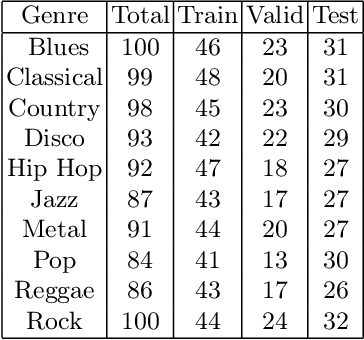
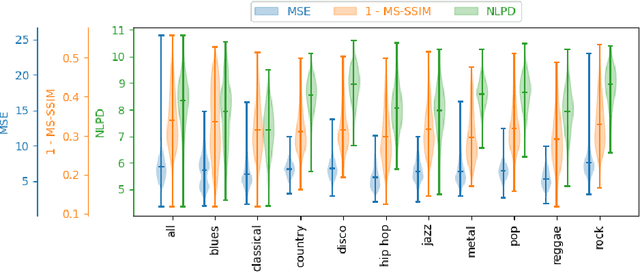
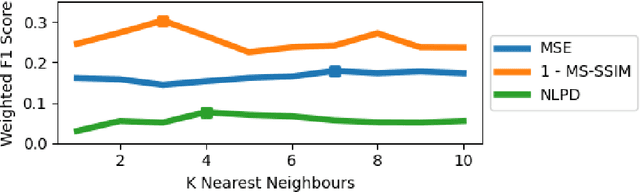
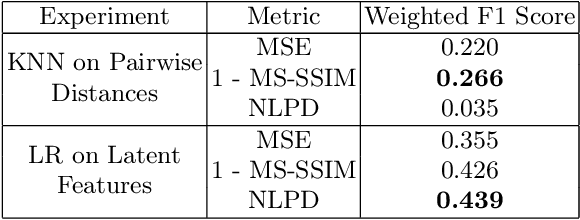
The subjective quality of natural signals can be approximated with objective perceptual metrics. Designed to approximate the perceptual behaviour of human observers, perceptual metrics often reflect structures found in natural signals and neurological pathways. Models trained with perceptual metrics as loss functions can capture perceptually meaningful features from the structures held within these metrics. We demonstrate that using features extracted from autoencoders trained with perceptual losses can improve performance on music understanding tasks, i.e. genre classification, over using these metrics directly as distances when learning a classifier. This result suggests improved generalisation to novel signals when using perceptual metrics as loss functions for representation learning.
Data is Overrated: Perceptual Metrics Can Lead Learning in the Absence of Training Data
Dec 06, 2023

Perceptual metrics are traditionally used to evaluate the quality of natural signals, such as images and audio. They are designed to mimic the perceptual behaviour of human observers and usually reflect structures found in natural signals. This motivates their use as loss functions for training generative models such that models will learn to capture the structure held in the metric. We take this idea to the extreme in the audio domain by training a compressive autoencoder to reconstruct uniform noise, in lieu of natural data. We show that training with perceptual losses improves the reconstruction of spectrograms and re-synthesized audio at test time over models trained with a standard Euclidean loss. This demonstrates better generalisation to unseen natural signals when using perceptual metrics.
JAMMIN-GPT: Text-based Improvisation using LLMs in Ableton Live
Dec 06, 2023
We introduce a system that allows users of Ableton Live to create MIDI-clips by naming them with musical descriptions. Users can compose by typing the desired musical content directly in Ableton's clip view, which is then inserted by our integrated system. This allows users to stay in the flow of their creative process while quickly generating musical ideas. The system works by prompting ChatGPT to reply using one of several text-based musical formats, such as ABC notation, chord symbols, or drum tablature. This is an important step in integrating generative AI tools into pre-existing musical workflows, and could be valuable for content makers who prefer to express their creative vision through descriptive language. Code is available at https://github.com/supersational/JAMMIN-GPT.
MIDI-Draw: Sketching to Control Melody Generation
May 19, 2023


We describe a proof-of-principle implementation of a system for drawing melodies that abstracts away from a note-level input representation via melodic contours. The aim is to allow users to express their musical intentions without requiring prior knowledge of how notes fit together melodiously. Current approaches to controllable melody generation often require users to choose parameters that are static across a whole sequence, via buttons or sliders. In contrast, our method allows users to quickly specify how parameters should change over time by drawing a contour.
What You Hear Is What You See: Audio Quality Metrics From Image Quality Metrics
May 19, 2023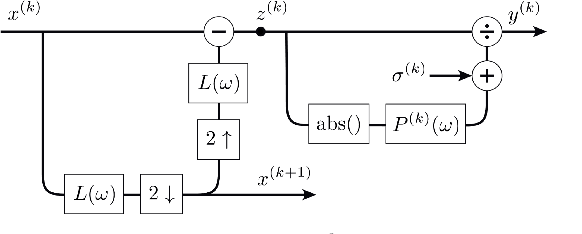


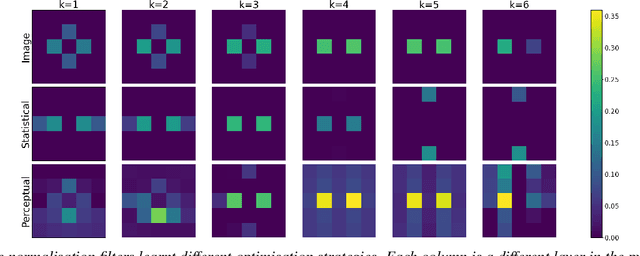
In this study, we investigate the feasibility of utilizing state-of-the-art image perceptual metrics for evaluating audio signals by representing them as spectrograms. The encouraging outcome of the proposed approach is based on the similarity between the neural mechanisms in the auditory and visual pathways. Furthermore, we customise one of the metrics which has a psychoacoustically plausible architecture to account for the peculiarities of sound signals. We evaluate the effectiveness of our proposed metric and several baseline metrics using a music dataset, with promising results in terms of the correlation between the metrics and the perceived quality of audio as rated by human evaluators.