 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual learning and refinement of causal models through dynamic predicate invention
Feb 19, 2026Efficiently navigating complex environments requires agents to internalize the underlying logic of their world, yet standard world modelling methods often struggle with sample inefficiency, lack of transparency, and poor scalability. We propose a framework for constructing symbolic causal world models entirely online by integrating continuous model learning and repair into the agent's decision loop, by leveraging the power of Meta-Interpretive Learning and predicate invention to find semantically meaningful and reusable abstractions, allowing an agent to construct a hierarchy of disentangled, high-quality concepts from its observations. We demonstrate that our lifted inference approach scales to domains with complex relational dynamics, where propositional methods suffer from combinatorial explosion, while achieving sample-efficiency orders of magnitude higher than the established PPO neural-network-based baseline.
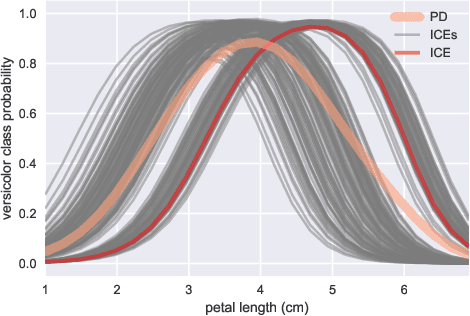
Explaining a probabilistic prediction on the simplex with Shapley compositions
Aug 02, 2024Originating in game theory, Shapley values are widely used for explaining a machine learning model's prediction by quantifying the contribution of each feature's value to the prediction. This requires a scalar prediction as in binary classification, whereas a multiclass probabilistic prediction is a discrete probability distribution, living on a multidimensional simplex. In such a multiclass setting the Shapley values are typically computed separately on each class in a one-vs-rest manner, ignoring the compositional nature of the output distribution. In this paper, we introduce Shapley compositions as a well-founded way to properly explain a multiclass probabilistic prediction, using the Aitchison geometry from compositional data analysis. We prove that the Shapley composition is the unique quantity satisfying linearity, symmetry and efficiency on the Aitchison simplex, extending the corresponding axiomatic properties of the standard Shapley value. We demonstrate this proper multiclass treatment in a range of scenarios.
Shapley Sets: Feature Attribution via Recursive Function Decomposition
Jul 04, 2023Despite their ubiquitous use, Shapley value feature attributions can be misleading due to feature interaction in both model and data. We propose an alternative attribution approach, Shapley Sets, which awards value to sets of features. Shapley Sets decomposes the underlying model into non-separable variable groups using a recursive function decomposition algorithm with log linear complexity in the number of variables. Shapley Sets attributes to each non-separable variable group their combined value for a particular prediction. We show that Shapley Sets is equivalent to the Shapley value over the transformed feature set and thus benefits from the same axioms of fairness. Shapley Sets is value function agnostic and we show theoretically and experimentally how Shapley Sets avoids pitfalls associated with Shapley value based alternatives and are particularly advantageous for data types with complex dependency structure.
MIDI-Draw: Sketching to Control Melody Generation
May 19, 2023


We describe a proof-of-principle implementation of a system for drawing melodies that abstracts away from a note-level input representation via melodic contours. The aim is to allow users to express their musical intentions without requiring prior knowledge of how notes fit together melodiously. Current approaches to controllable melody generation often require users to choose parameters that are static across a whole sequence, via buttons or sliders. In contrast, our method allows users to quickly specify how parameters should change over time by drawing a contour.
When the Ground Truth is not True: Modelling Human Biases in Temporal Annotations
Feb 06, 2023



In supervised learning, low quality annotations lead to poorly performing classification and detection models, while also rendering evaluation unreliable. This is particularly apparent on temporal data, where annotation quality is affected by multiple factors. For example, in the post-hoc self-reporting of daily activities, cognitive biases are one of the most common ingredients. In particular, reporting the start and duration of an activity after its finalisation may incorporate biases introduced by personal time perceptions, as well as the imprecision and lack of granularity due to time rounding. Here we propose a method to model human biases on temporal annotations and argue for the use of soft labels. Experimental results in synthetic data show that soft labels provide a better approximation of the ground truth for several metrics. We showcase the method on a real dataset of daily activities.
What and How of Machine Learning Transparency: Building Bespoke Explainability Tools with Interoperable Algorithmic Components
Sep 08, 2022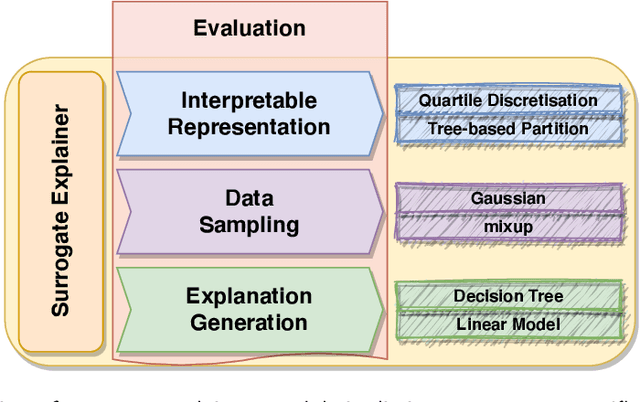
Explainability techniques for data-driven predictive models based on artificial intelligence and machine learning algorithms allow us to better understand the operation of such systems and help to hold them accountable. New transparency approaches are developed at breakneck speed, enabling us to peek inside these black boxes and interpret their decisions. Many of these techniques are introduced as monolithic tools, giving the impression of one-size-fits-all and end-to-end algorithms with limited customisability. Nevertheless, such approaches are often composed of multiple interchangeable modules that need to be tuned to the problem at hand to produce meaningful explanations. This paper introduces a collection of hands-on training materials -- slides, video recordings and Jupyter Notebooks -- that provide guidance through the process of building and evaluating bespoke modular surrogate explainers for tabular data. These resources cover the three core building blocks of this technique: interpretable representation composition, data sampling and explanation generation.
FAT Forensics: A Python Toolbox for Implementing and Deploying Fairness, Accountability and Transparency Algorithms in Predictive Systems
Sep 08, 2022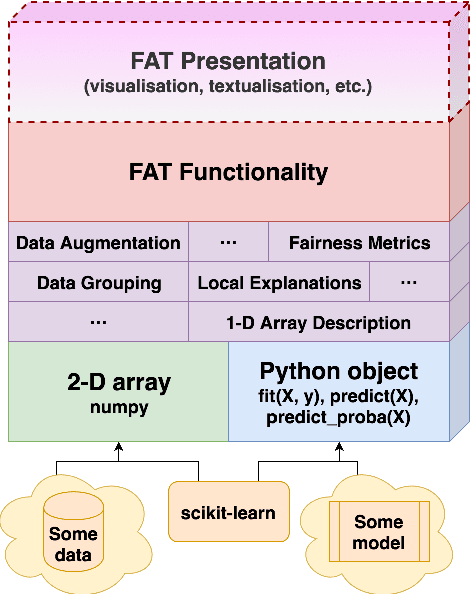
Predictive systems, in particular machine learning algorithms, can take important, and sometimes legally binding, decisions about our everyday life. In most cases, however, these systems and decisions are neither regulated nor certified. Given the potential harm that these algorithms can cause, their qualities such as fairness, accountability and transparency (FAT) are of paramount importance. To ensure high-quality, fair, transparent and reliable predictive systems, we developed an open source Python package called FAT Forensics. It can inspect important fairness, accountability and transparency aspects of predictive algorithms to automatically and objectively report them back to engineers and users of such systems. Our toolbox can evaluate all elements of a predictive pipeline: data (and their features), models and predictions. Published under the BSD 3-Clause open source licence, FAT Forensics is opened up for personal and commercial usage.
Simply Logical -- Intelligent Reasoning by Example (Fully Interactive Online Edition)
Aug 14, 2022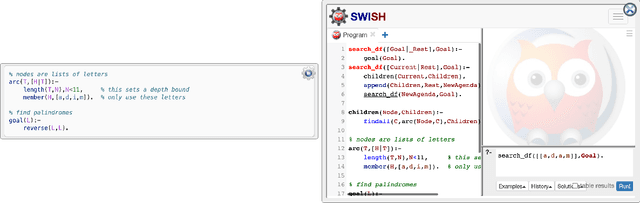
"Simply Logical -- Intelligent Reasoning by Example" by Peter Flach was first published by John Wiley in 1994. It could be purchased as book-only or with a 3.5 inch diskette containing the SWI-Prolog programmes printed in the book (for various operating systems). In 2007 the copyright reverted back to the author at which point the book and programmes were made freely available online; the print version is no longer distributed through John Wiley publishers. In 2015, as a pilot, we ported most of the original book into an online, interactive website using SWI-Prolog's SWISH platform. Since then, we launched the Simply Logical open source organisation committed to maintaining a suite of freely available interactive online educational resources about Artificial Intelligence and Logic Programming with Prolog. With the advent of new educational technologies we were inspired to rebuild the book from the ground up using the Jupyter Book platform enhanced with a collection of bespoke plugins that implement, among other things, interactive SWI-Prolog code blocks that can be executed directly in a web browser. This new version is more modular, easier to maintain, and can be split into custom teaching modules, in addition to being modern-looking, visually appealing, and compatible with a range of (mobile) devices of varying screen sizes.
The Weak Supervision Landscape
Mar 30, 2022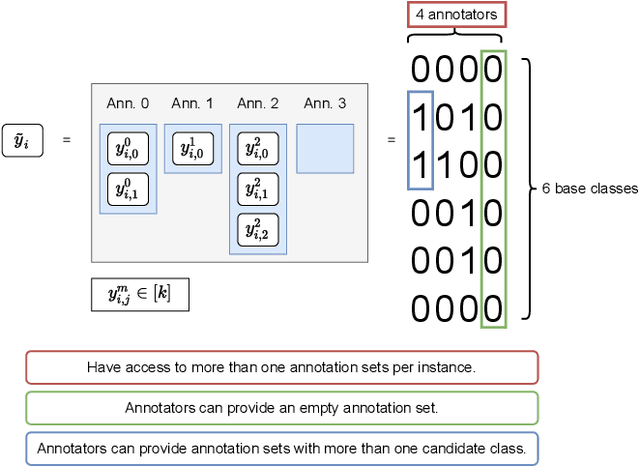
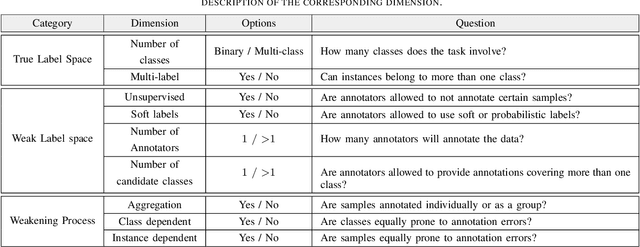
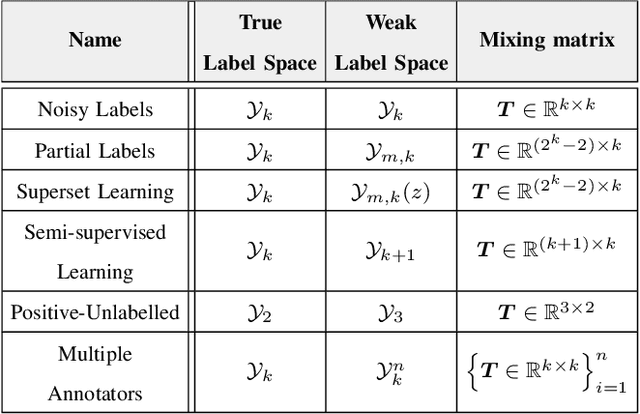
Many ways of annotating a dataset for machine learning classification tasks that go beyond the usual class labels exist in practice. These are of interest as they can simplify or facilitate the collection of annotations, while not greatly affecting the resulting machine learning model. Many of these fall under the umbrella term of weak labels or annotations. However, it is not always clear how different alternatives are related. In this paper we propose a framework for categorising weak supervision settings with the aim of: (1) helping the dataset owner or annotator navigate through the available options within weak supervision when prescribing an annotation process, and (2) describing existing annotations for a dataset to machine learning practitioners so that we allow them to understand the implications for the learning process. To this end, we identify the key elements that characterise weak supervision and devise a series of dimensions that categorise most of the existing approaches. We show how common settings in the literature fit within the framework and discuss its possible uses in practice.
Explainability Is in the Mind of the Beholder: Establishing the Foundations of Explainable Artificial Intelligence
Dec 29, 2021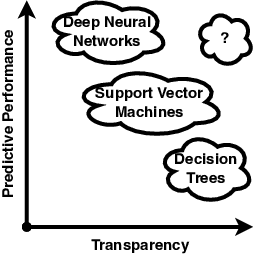

Explainable artificial intelligence and interpretable machine learning are research fields growing in importance. Yet, the underlying concepts remain somewhat elusive and lack generally agreed definitions. While recent inspiration from social sciences has refocused the work on needs and expectations of human recipients, the field still misses a concrete conceptualisation. We take steps towards addressing this challenge by reviewing the philosophical and social foundations of human explainability, which we then translate into the technological realm. In particular, we scrutinise the notion of algorithmic black boxes and the spectrum of understanding determined by explanatory processes and explainees' background knowledge. This approach allows us to define explainability as (logical) reasoning applied to transparent insights (into black boxes) interpreted under certain background knowledge - a process that engenders understanding in explainees. We then employ this conceptualisation to revisit the much disputed trade-off between transparency and predictive power and its implications for ante-hoc and post-hoc explainers as well as fairness and accountability engendered by explainability. We furthermore discuss components of the machine learning workflow that may be in need of interpretability, building on a range of ideas from human-centred explainability, with a focus on explainees, contrastive statements and explanatory processes. Our discussion reconciles and complements current research to help better navigate open questions - rather than attempting to address any individual issue - thus laying a solid foundation for a grounded discussion and future progress of explainable artificial intelligence and interpretable machine learning. We conclude with a summary of our findings, revisiting the human-centred explanatory process needed to achieve the desired level of algorithmic transparency.