 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Weak Supervision Landscape
Paper and Code
Mar 30, 2022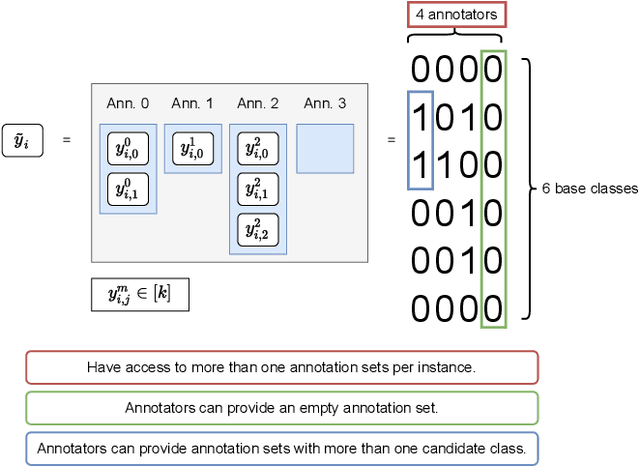
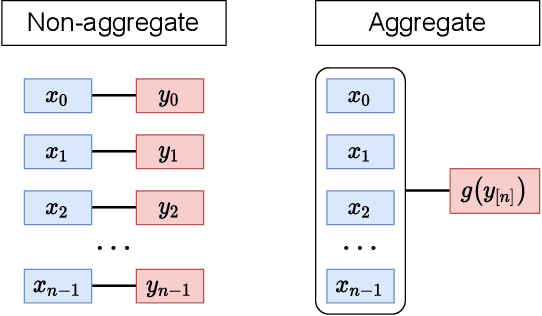
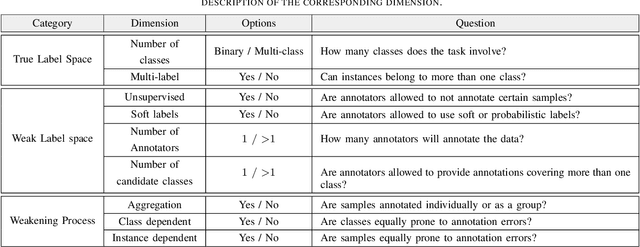
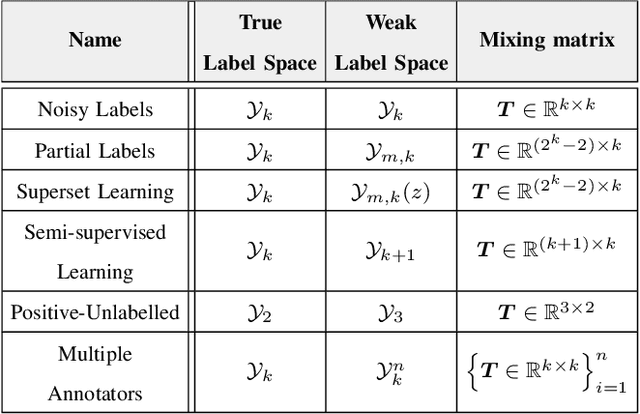
Many ways of annotating a dataset for machine learning classification tasks that go beyond the usual class labels exist in practice. These are of interest as they can simplify or facilitate the collection of annotations, while not greatly affecting the resulting machine learning model. Many of these fall under the umbrella term of weak labels or annotations. However, it is not always clear how different alternatives are related. In this paper we propose a framework for categorising weak supervision settings with the aim of: (1) helping the dataset owner or annotator navigate through the available options within weak supervision when prescribing an annotation process, and (2) describing existing annotations for a dataset to machine learning practitioners so that we allow them to understand the implications for the learning process. To this end, we identify the key elements that characterise weak supervision and devise a series of dimensions that categorise most of the existing approaches. We show how common settings in the literature fit within the framework and discuss its possible uses in practice.