 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Requirements of Clinicians for Explainable AI Decision Support Systems in Intensive Care
Nov 18, 2024There is a growing need to understand how digital systems can support clinical decision-making, particularly as artificial intelligence (AI) models become increasingly complex and less human-interpretable. This complexity raises concerns about trustworthiness, impacting safe and effective adoption of such technologies. Improved understanding of decision-making processes and requirements for explanations coming from decision support tools is a vital component in providing effective explainable solutions. This is particularly relevant in the data-intensive, fast-paced environments of intensive care units (ICUs). To explore these issues, group interviews were conducted with seven ICU clinicians, representing various roles and experience levels. Thematic analysis revealed three core themes: (T1) ICU decision-making relies on a wide range of factors, (T2) the complexity of patient state is challenging for shared decision-making, and (T3) requirements and capabilities of AI decision support systems. We include design recommendations from clinical input, providing insights to inform future AI systems for intensive care.
The Weak Supervision Landscape
Mar 30, 2022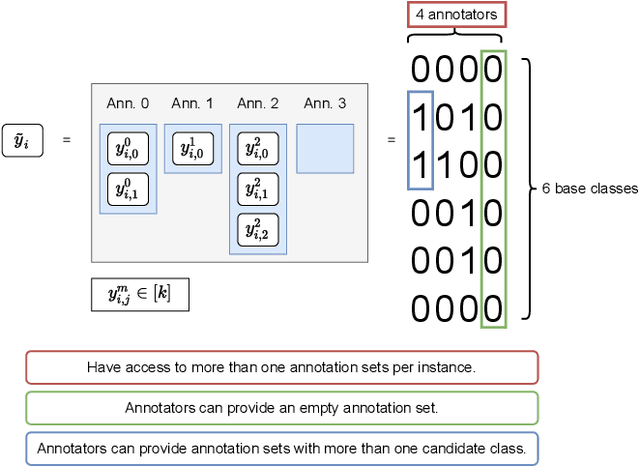
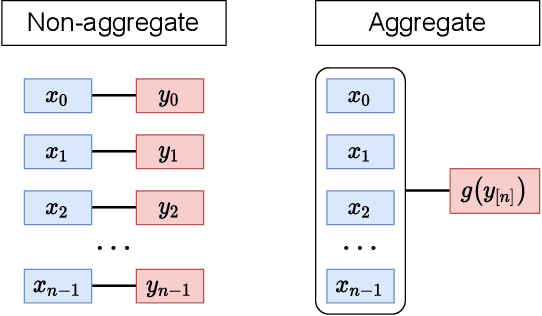
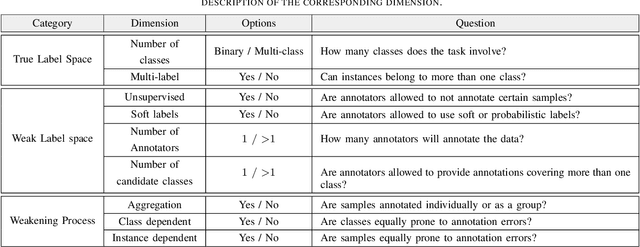
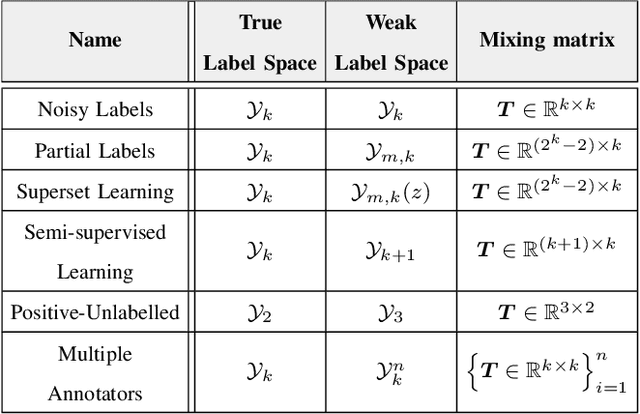
Many ways of annotating a dataset for machine learning classification tasks that go beyond the usual class labels exist in practice. These are of interest as they can simplify or facilitate the collection of annotations, while not greatly affecting the resulting machine learning model. Many of these fall under the umbrella term of weak labels or annotations. However, it is not always clear how different alternatives are related. In this paper we propose a framework for categorising weak supervision settings with the aim of: (1) helping the dataset owner or annotator navigate through the available options within weak supervision when prescribing an annotation process, and (2) describing existing annotations for a dataset to machine learning practitioners so that we allow them to understand the implications for the learning process. To this end, we identify the key elements that characterise weak supervision and devise a series of dimensions that categorise most of the existing approaches. We show how common settings in the literature fit within the framework and discuss its possible uses in practice.
Classifier Calibration: How to assess and improve predicted class probabilities: a survey
Dec 20, 2021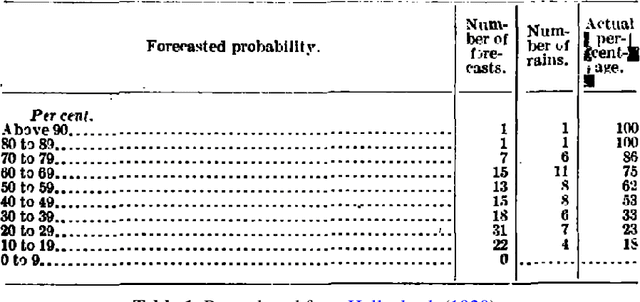
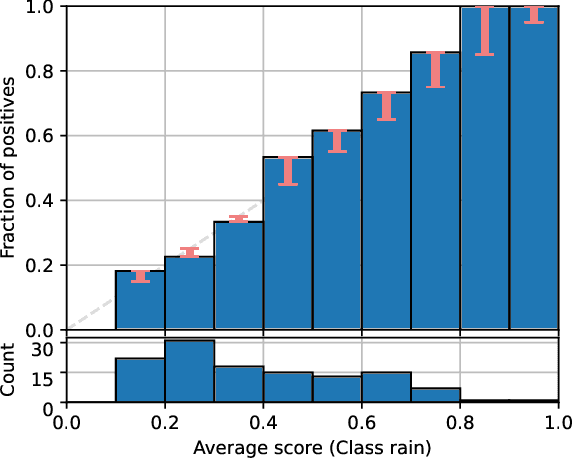
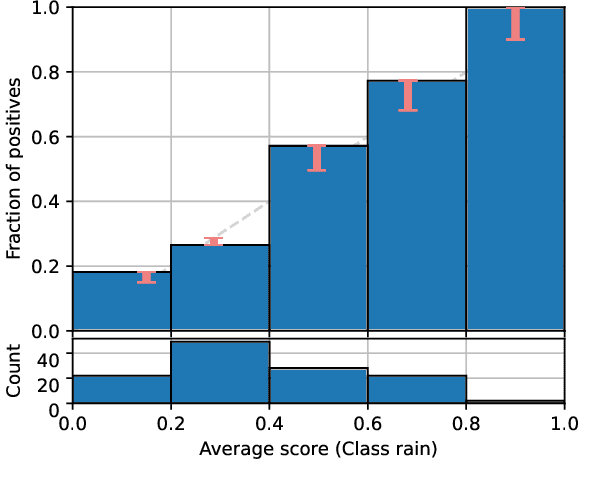
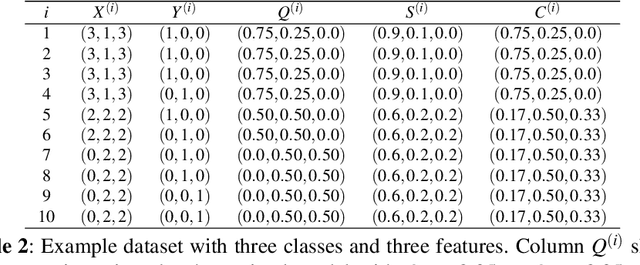
This paper provides both an introduction to and a detailed overview of the principles and practice of classifier calibration. A well-calibrated classifier correctly quantifies the level of uncertainty or confidence associated with its instance-wise predictions. This is essential for critical applications, optimal decision making, cost-sensitive classification, and for some types of context change. Calibration research has a rich history which predates the birth of machine learning as an academic field by decades. However, a recent increase in the interest on calibration has led to new methods and the extension from binary to the multiclass setting. The space of options and issues to consider is large, and navigating it requires the right set of concepts and tools. We provide both introductory material and up-to-date technical details of the main concepts and methods, including proper scoring rules and other evaluation metrics, visualisation approaches, a comprehensive account of post-hoc calibration methods for binary and multiclass classification, and several advanced topics.
Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with Dirichlet calibration
Oct 28, 2019
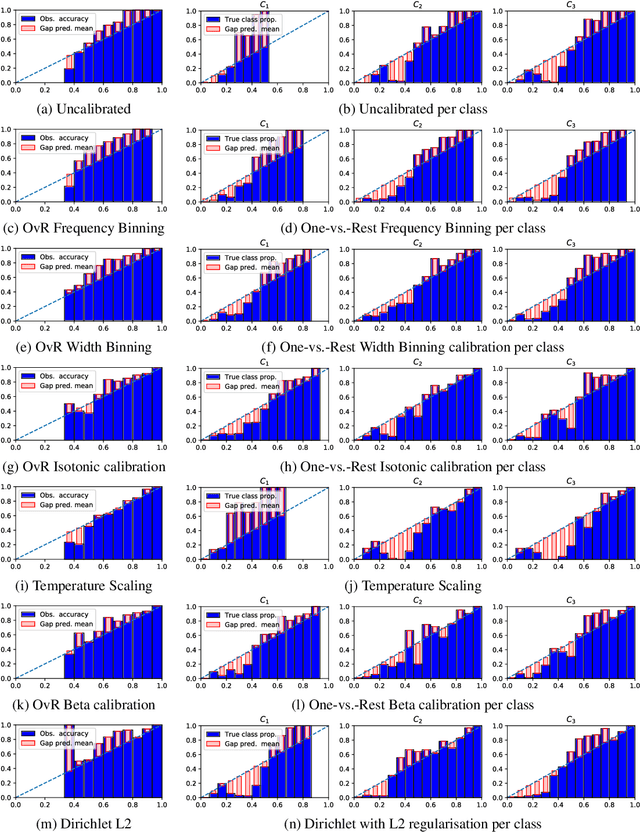

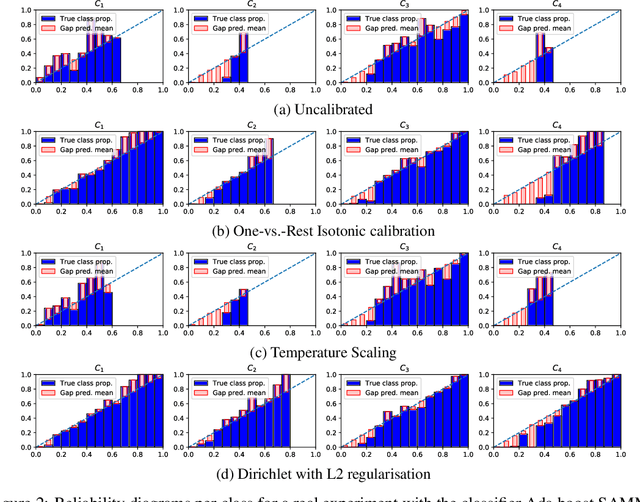
Class probabilities predicted by most multiclass classifiers are uncalibrated, often tending towards over-confidence. With neural networks, calibration can be improved by temperature scaling, a method to learn a single corrective multiplicative factor for inputs to the last softmax layer. On non-neural models the existing methods apply binary calibration in a pairwise or one-vs-rest fashion. We propose a natively multiclass calibration method applicable to classifiers from any model class, derived from Dirichlet distributions and generalising the beta calibration method from binary classification. It is easily implemented with neural nets since it is equivalent to log-transforming the uncalibrated probabilities, followed by one linear layer and softmax. Experiments demonstrate improved probabilistic predictions according to multiple measures (confidence-ECE, classwise-ECE, log-loss, Brier score) across a wide range of datasets and classifiers. Parameters of the learned Dirichlet calibration map provide insights to the biases in the uncalibrated model.
HyperStream: a Workflow Engine for Streaming Data
Aug 07, 2019
This paper describes HyperStream, a large-scale, flexible and robust software package, written in the Python language, for processing streaming data with workflow creation capabilities. HyperStream overcomes the limitations of other computational engines and provides high-level interfaces to execute complex nesting, fusion, and prediction both in online and offline forms in streaming environments. HyperStream is a general purpose tool that is well-suited for the design, development, and deployment of Machine Learning algorithms and predictive models in a wide space of sequential predictive problems. Source code, installation instructions, examples, and documentation can be found at: https://github.com/IRC-SPHERE/HyperStream.