 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Uncertainty Estimation Scales with Sampling in Reasoning Models
Mar 19, 2026Uncertainty estimation is critical for deploying reasoning language models, yet remains poorly understood under extended chain-of-thought reasoning. We study parallel sampling as a fully black-box approach using verbalized confidence and self-consistency. Across three reasoning models and 17 tasks spanning mathematics, STEM, and humanities, we characterize how these signals scale. Both self-consistency and verbalized confidence scale in reasoning models, but self-consistency exhibits lower initial discrimination and lags behind verbalized confidence under moderate sampling. Most uncertainty gains, however, arise from signal combination: with just two samples, a hybrid estimator improves AUROC by up to $+12$ on average and already outperforms either signal alone even when scaled to much larger budgets, after which returns diminish. These effects are domain-dependent: in mathematics, the native domain of RLVR-style post-training, reasoning models achieve higher uncertainty quality and exhibit both stronger complementarity and faster scaling than in STEM or humanities.
The Confidence Trap: Gender Bias and Predictive Certainty in LLMs
Jan 12, 2026The increased use of Large Language Models (LLMs) in sensitive domains leads to growing interest in how their confidence scores correspond to fairness and bias. This study examines the alignment between LLM-predicted confidence and human-annotated bias judgments. Focusing on gender bias, the research investigates probability confidence calibration in contexts involving gendered pronoun resolution. The goal is to evaluate if calibration metrics based on predicted confidence scores effectively capture fairness-related disparities in LLMs. The results show that, among the six state-of-the-art models, Gemma-2 demonstrates the worst calibration according to the gender bias benchmark. The primary contribution of this work is a fairness-aware evaluation of LLMs' confidence calibration, offering guidance for ethical deployment. In addition, we introduce a new calibration metric, Gender-ECE, designed to measure gender disparities in resolution tasks.
Calibrated Perception Uncertainty Across Objects and Regions in Bird's-Eye-View
Nov 08, 2022
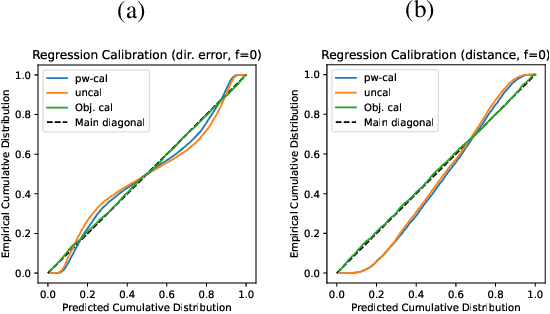


In driving scenarios with poor visibility or occlusions, it is important that the autonomous vehicle would take into account all the uncertainties when making driving decisions, including choice of a safe speed. The grid-based perception outputs, such as occupancy grids, and object-based outputs, such as lists of detected objects, must then be accompanied by well-calibrated uncertainty estimates. We highlight limitations in the state-of-the-art and propose a more complete set of uncertainties to be reported, particularly including undetected-object-ahead probabilities. We suggest a novel way to get these probabilistic outputs from bird's-eye-view probabilistic semantic segmentation, in the example of the FIERY model. We demonstrate that the obtained probabilities are not calibrated out-of-the-box and propose methods to achieve well-calibrated uncertainties.
On the Usefulness of the Fit-on-the-Test View on Evaluating Calibration of Classifiers
Mar 21, 2022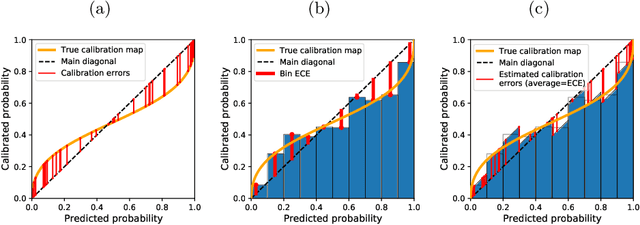

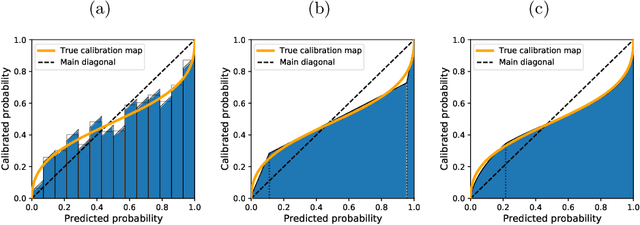
Every uncalibrated classifier has a corresponding true calibration map that calibrates its confidence. Deviations of this idealistic map from the identity map reveal miscalibration. Such calibration errors can be reduced with many post-hoc calibration methods which fit some family of calibration maps on a validation dataset. In contrast, evaluation of calibration with the expected calibration error (ECE) on the test set does not explicitly involve fitting. However, as we demonstrate, ECE can still be viewed as if fitting a family of functions on the test data. This motivates the fit-on-the-test view on evaluation: first, approximate a calibration map on the test data, and second, quantify its distance from the identity. Exploiting this view allows us to unlock missed opportunities: (1) use the plethora of post-hoc calibration methods for evaluating calibration; (2) tune the number of bins in ECE with cross-validation. Furthermore, we introduce: (3) benchmarking on pseudo-real data where the true calibration map can be estimated very precisely; and (4) novel calibration and evaluation methods using new calibration map families PL and PL3.
Correlated daily time series and forecasting in the M4 competition
Mar 31, 2020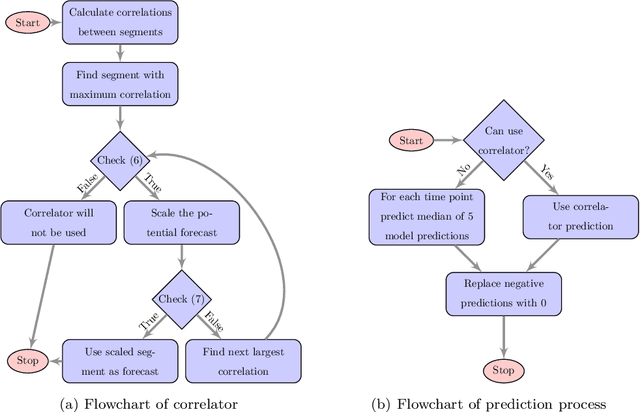
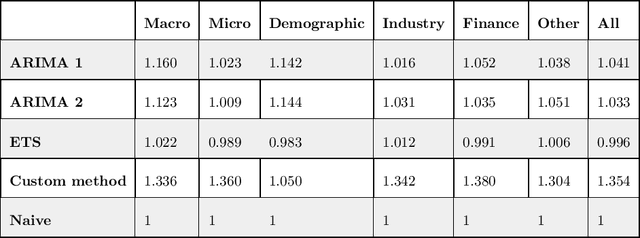
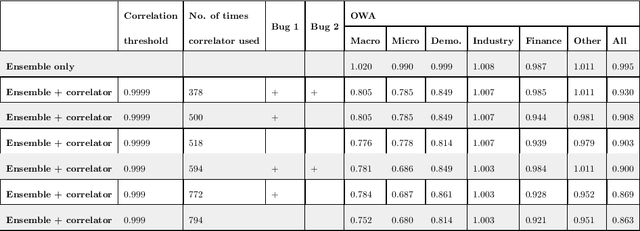
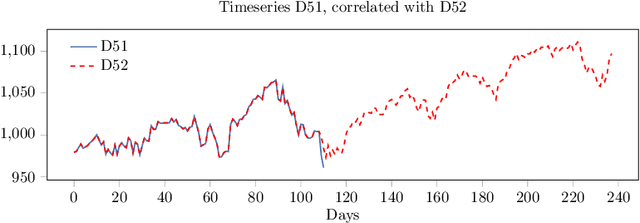
We participated in the M4 competition for time series forecasting and describe here our methods for forecasting daily time series. We used an ensemble of five statistical forecasting methods and a method that we refer to as the correlator. Our retrospective analysis using the ground truth values published by the M4 organisers after the competition demonstrates that the correlator was responsible for most of our gains over the naive constant forecasting method. We identify data leakage as one reason for its success, partly due to test data selected from different time intervals, and partly due to quality issues in the original time series. We suggest that future forecasting competitions should provide actual dates for the time series so that some of those leakages could be avoided by the participants.
Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with Dirichlet calibration
Oct 28, 2019
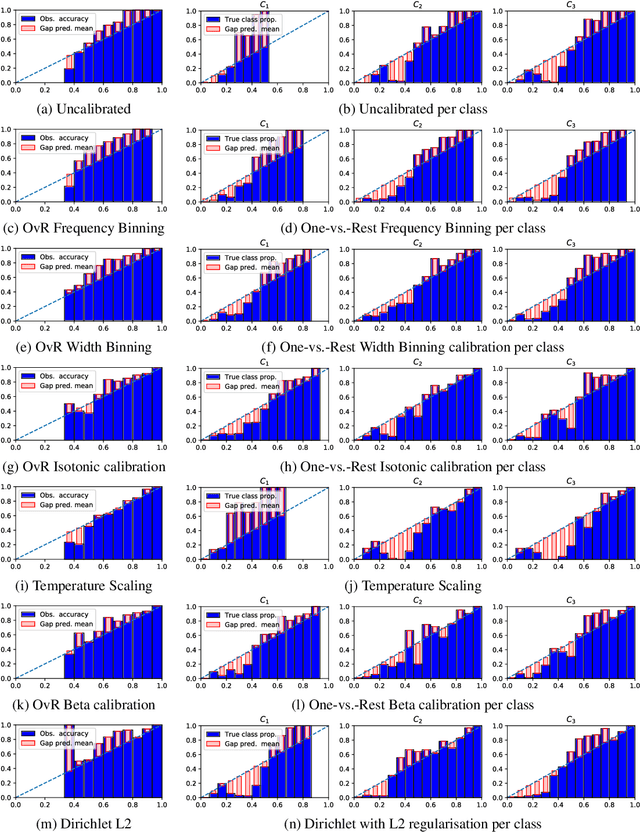

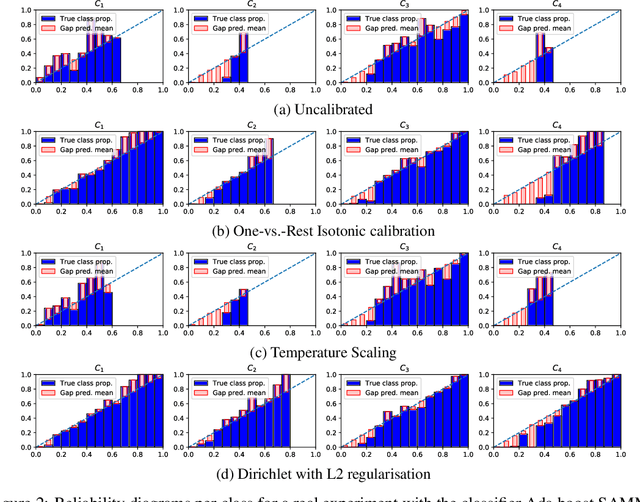
Class probabilities predicted by most multiclass classifiers are uncalibrated, often tending towards over-confidence. With neural networks, calibration can be improved by temperature scaling, a method to learn a single corrective multiplicative factor for inputs to the last softmax layer. On non-neural models the existing methods apply binary calibration in a pairwise or one-vs-rest fashion. We propose a natively multiclass calibration method applicable to classifiers from any model class, derived from Dirichlet distributions and generalising the beta calibration method from binary classification. It is easily implemented with neural nets since it is equivalent to log-transforming the uncalibrated probabilities, followed by one linear layer and softmax. Experiments demonstrate improved probabilistic predictions according to multiple measures (confidence-ECE, classwise-ECE, log-loss, Brier score) across a wide range of datasets and classifiers. Parameters of the learned Dirichlet calibration map provide insights to the biases in the uncalibrated model.