 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtremely low-resource machine translation for closely related languages
May 27, 2021



An effective method to improve extremely low-resource neural machine translation is multilingual training, which can be improved by leveraging monolingual data to create synthetic bilingual corpora using the back-translation method. This work focuses on closely related languages from the Uralic language family: from Estonian and Finnish geographical regions. We find that multilingual learning and synthetic corpora increase the translation quality in every language pair for which we have data. We show that transfer learning and fine-tuning are very effective for doing low-resource machine translation and achieve the best results. We collected new parallel data for V\~oro, North and South Saami and present first results of neural machine translation for these languages.
Explicit Representation of the Translation Space: Automatic Paraphrasing for Machine Translation Evaluation
Apr 30, 2020

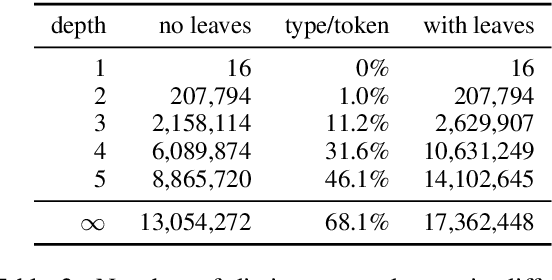

Following previous work on automatic paraphrasing, we assess the feasibility of improving BLEU (Papineni et al., 2002) using state-of-the-art neural paraphrasing techniques to generate additional references. We explore the extent to which diverse paraphrases can adequately cover the space of valid translations and compare to an alternative approach of generating paraphrases constrained by MT outputs. We compare both approaches to human-produced references in terms of diversity and the improvement in BLEU's correlation with human judgements of MT quality. Our experiments on the WMT19 metrics tasks for all into-English language directions show that somewhat surprisingly, the addition of diverse paraphrases, even those produced by humans, leads to only small, inconsistent changes in BLEU's correlation with human judgments, suggesting that BLEU's ability to correctly exploit multiple references is limited
Correlated daily time series and forecasting in the M4 competition
Mar 31, 2020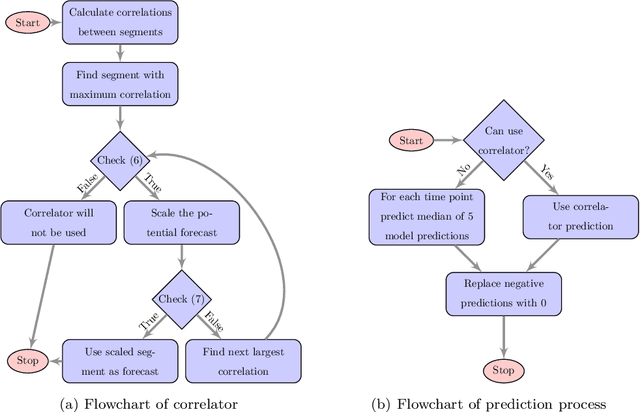
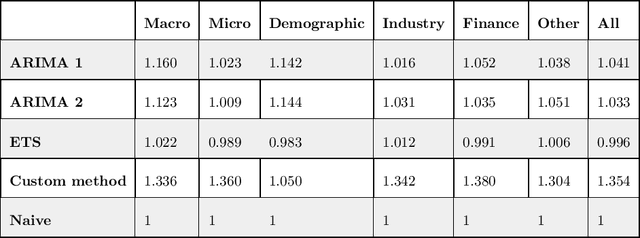
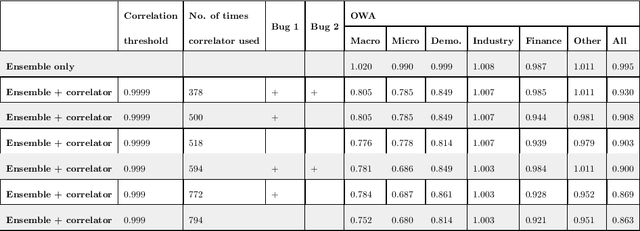
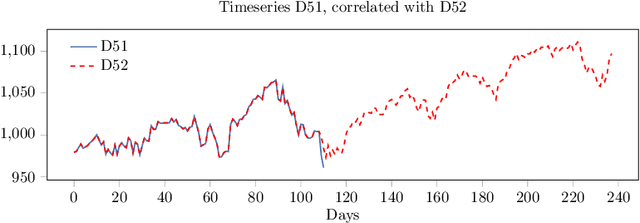
We participated in the M4 competition for time series forecasting and describe here our methods for forecasting daily time series. We used an ensemble of five statistical forecasting methods and a method that we refer to as the correlator. Our retrospective analysis using the ground truth values published by the M4 organisers after the competition demonstrates that the correlator was responsible for most of our gains over the naive constant forecasting method. We identify data leakage as one reason for its success, partly due to test data selected from different time intervals, and partly due to quality issues in the original time series. We suggest that future forecasting competitions should provide actual dates for the time series so that some of those leakages could be avoided by the participants.