 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Representation of the Translation Space: Automatic Paraphrasing for Machine Translation Evaluation
Paper and Code


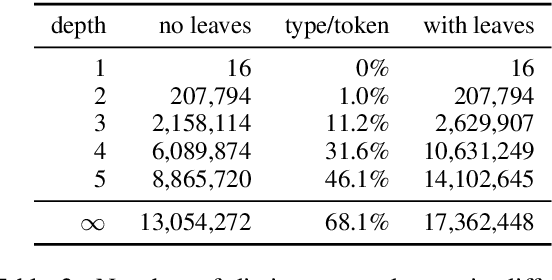

Following previous work on automatic paraphrasing, we assess the feasibility of improving BLEU (Papineni et al., 2002) using state-of-the-art neural paraphrasing techniques to generate additional references. We explore the extent to which diverse paraphrases can adequately cover the space of valid translations and compare to an alternative approach of generating paraphrases constrained by MT outputs. We compare both approaches to human-produced references in terms of diversity and the improvement in BLEU's correlation with human judgements of MT quality. Our experiments on the WMT19 metrics tasks for all into-English language directions show that somewhat surprisingly, the addition of diverse paraphrases, even those produced by humans, leads to only small, inconsistent changes in BLEU's correlation with human judgments, suggesting that BLEU's ability to correctly exploit multiple references is limited