 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnySurf: Any Surface Generation with Directed Edge
May 23, 2026Open surface components prevail in real industrial 3D content and support rendering, physical simulation and geometric editing. Garments serve as a typical open surface type, with numerous existing generation methods leveraging sewing patterns to generate 2D panels and stitch them into 3D shapes. Such domain-specific designs lack scalability and cannot generalize to shoes and accessories. Common field-based 3D generators prioritize watertight meshes and tend to create flawed double-layer structures on open surfaces. Though Trellis2 adopts field-free representation, its open surface results still contain normal and topology errors. We present AnySurf, a unified framework generating open, closed and hybrid 3D surfaces with accurate face orientation. Built on directed-edge enhanced Flexible Dual Grid (FDG-D), our representation retains normal direction information via oriented grid edges. We also propose ROS-FT post-training and a lightweight DE-Adapter with merely 1% extra parameters, facilitating directed edge learning while preserving original generation performance. We further construct Outfit3D dataset containing industrial garments and closed accessories. Our work transforms garment modeling into a universal 3D generation task. Experimental results demonstrate superior mesh quality and better practicality for downstream applications.
AFMRL: Attribute-Enhanced Fine-Grained Multi-Modal Representation Learning in E-commerce
Apr 22, 2026Multimodal representation is crucial for E-commerce tasks such as identical product retrieval. Large representation models (e.g., VLM2Vec) demonstrate strong multimodal understanding capabilities, yet they struggle with fine-grained semantic comprehension, which is essential for distinguishing highly similar items. To address this, we propose Attribute-Enhanced Fine-Grained Multi-Modal Representation Learning (AFMRL), which defines product fine-grained understanding as an attribute generation task. It leverages the generative power of Multimodal Large Language Models (MLLMs) to extract key attributes from product images and text, and enhances representation learning through a two-stage training framework: 1) Attribute-Guided Contrastive Learning (AGCL), where the key attributes generated by the MLLM are used in the image-text contrastive learning training process to identify hard samples and filter out noisy false negatives. 2) Retrieval-aware Attribute Reinforcement (RAR), where the improved retrieval performance of the representation model post-attribute integration serves as a reward signal to enhance MLLM's attribute generation during multimodal fine-tuning. Extensive experiments on large-scale E-commerce datasets demonstrate that our method achieves state-of-the-art performance on multiple downstream retrieval tasks, validating the effectiveness of harnessing generative models to advance fine-grained representation learning.
FACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
Mar 03, 2026Autoregressive models for 3D mesh generation suffer from a fundamental limitation: they flatten meshes into long vertex-coordinate sequences. This results in prohibitive computational costs, hindering the efficient synthesis of high-fidelity geometry. We argue this bottleneck stems from operating at the wrong semantic level. We introduce FACE, a novel Autoregressive Autoencoder (ARAE) framework that reconceptualizes the task by generating meshes at the face level. Our one-face-one-token strategy treats each triangle face, the fundamental building block of a mesh, as a single, unified token. This simple yet powerful design reduces the sequence length by a factor of nine, leading to an unprecedented compression ratio of 0.11, halving the previous state-of-the-art. This dramatic efficiency gain does not compromise quality; by pairing our face-level decoder with a powerful VecSet encoder, FACE achieves state-of-the-art reconstruction quality on standard benchmarks. The versatility of the learned latent space is further demonstrated by training a latent diffusion model that achieves high-fidelity, single-image-to-mesh generation. FACE provides a simple, scalable, and powerful paradigm that lowers the barrier to high-quality structured 3D content creation.
T5Gemma 2: Seeing, Reading, and Understanding Longer
Dec 23, 2025We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.
PoseGAM: Robust Unseen Object Pose Estimation via Geometry-Aware Multi-View Reasoning
Dec 11, 20256D object pose estimation, which predicts the transformation of an object relative to the camera, remains challenging for unseen objects. Existing approaches typically rely on explicitly constructing feature correspondences between the query image and either the object model or template images. In this work, we propose PoseGAM, a geometry-aware multi-view framework that directly predicts object pose from a query image and multiple template images, eliminating the need for explicit matching. Built upon recent multi-view-based foundation model architectures, the method integrates object geometry information through two complementary mechanisms: explicit point-based geometry and learned features from geometry representation networks. In addition, we construct a large-scale synthetic dataset containing more than 190k objects under diverse environmental conditions to enhance robustness and generalization. Extensive evaluations across multiple benchmarks demonstrate our state-of-the-art performance, yielding an average AR improvement of 5.1% over prior methods and achieving up to 17.6% gains on individual datasets, indicating strong generalization to unseen objects. Project page: https://windvchen.github.io/PoseGAM/ .
Human Geometry Distribution for 3D Animation Generation
Dec 08, 2025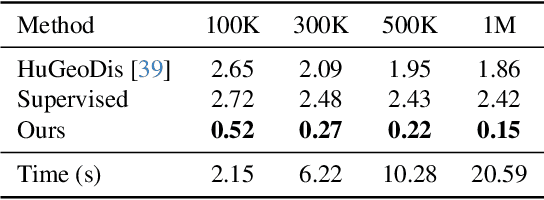
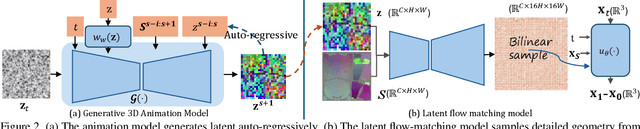
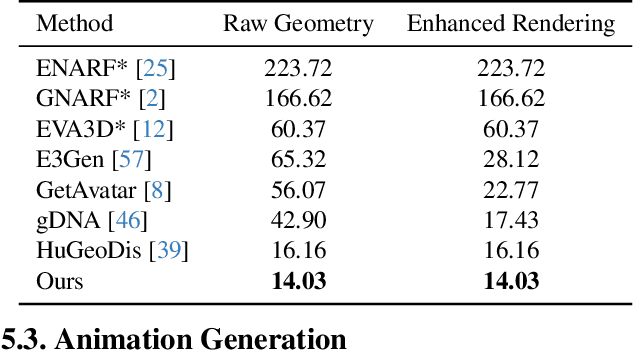
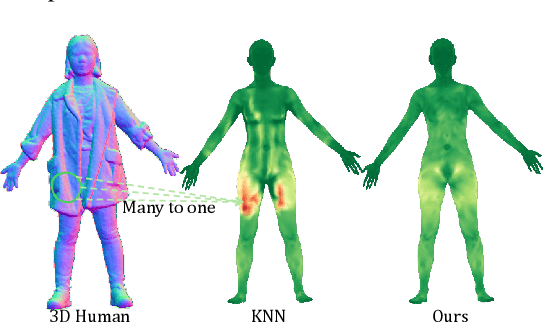
Generating realistic human geometry animations remains a challenging task, as it requires modeling natural clothing dynamics with fine-grained geometric details under limited data. To address these challenges, we propose two novel designs. First, we propose a compact distribution-based latent representation that enables efficient and high-quality geometry generation. We improve upon previous work by establishing a more uniform mapping between SMPL and avatar geometries. Second, we introduce a generative animation model that fully exploits the diversity of limited motion data. We focus on short-term transitions while maintaining long-term consistency through an identity-conditioned design. These two designs formulate our method as a two-stage framework: the first stage learns a latent space, while the second learns to generate animations within this latent space. We conducted experiments on both our latent space and animation model. We demonstrate that our latent space produces high-fidelity human geometry surpassing previous methods ($90\%$ lower Chamfer Dist.). The animation model synthesizes diverse animations with detailed and natural dynamics ($2.2 \times$ higher user study score), achieving the best results across all evaluation metrics.
Encoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model
Oct 30, 2025Recent large language model (LLM) research has undergone an architectural shift from encoder-decoder modeling to nowadays the dominant decoder-only modeling. This rapid transition, however, comes without a rigorous comparative analysis especially \textit{from the scaling perspective}, raising concerns that the potential of encoder-decoder models may have been overlooked. To fill this gap, we revisit encoder-decoder LLM (RedLLM), enhancing it with recent recipes from decoder-only LLM (DecLLM). We conduct a comprehensive comparison between RedLLM, pretrained with prefix language modeling (LM), and DecLLM, pretrained with causal LM, at different model scales, ranging from $\sim$150M to $\sim$8B. Using RedPajama V1 (1.6T tokens) for pretraining and FLAN for instruction tuning, our experiments show that RedLLM produces compelling scaling properties and surprisingly strong performance. While DecLLM is overall more compute-optimal during pretraining, RedLLM demonstrates comparable scaling and context length extrapolation capabilities. After instruction tuning, RedLLM achieves comparable and even better results on various downstream tasks while enjoying substantially better inference efficiency. We hope our findings could inspire more efforts on re-examining RedLLM, unlocking its potential for developing powerful and efficient LLMs.
SMEC: Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression
Oct 14, 2025Large language models (LLMs) generate high-dimensional embeddings that capture rich semantic and syntactic information. However, high-dimensional embeddings exacerbate computational complexity and storage requirements, thereby hindering practical deployment. To address these challenges, we propose a novel training framework named Sequential Matryoshka Embedding Compression (SMEC). This framework introduces the Sequential Matryoshka Representation Learning(SMRL) method to mitigate gradient variance during training, the Adaptive Dimension Selection (ADS) module to reduce information degradation during dimension pruning, and the Selectable Cross-batch Memory (S-XBM) module to enhance unsupervised learning between high- and low-dimensional embeddings. Experiments on image, text, and multimodal datasets demonstrate that SMEC achieves significant dimensionality reduction while maintaining performance. For instance, on the BEIR dataset, our approach improves the performance of compressed LLM2Vec embeddings (256 dimensions) by 1.1 points and 2.7 points compared to the Matryoshka-Adaptor and Search-Adaptor models, respectively.
efunc: An Efficient Function Representation without Neural Networks
May 27, 2025Function fitting/approximation plays a fundamental role in computer graphics and other engineering applications. While recent advances have explored neural networks to address this task, these methods often rely on architectures with many parameters, limiting their practical applicability. In contrast, we pursue high-quality function approximation using parameter-efficient representations that eliminate the dependency on neural networks entirely. We first propose a novel framework for continuous function modeling. Most existing works can be formulated using this framework. We then introduce a compact function representation, which is based on polynomials interpolated using radial basis functions, bypassing both neural networks and complex/hierarchical data structures. We also develop memory-efficient CUDA-optimized algorithms that reduce computational time and memory consumption to less than 10% compared to conventional automatic differentiation frameworks. Finally, we validate our representation and optimization pipeline through extensive experiments on 3D signed distance functions (SDFs). The proposed representation achieves comparable or superior performance to state-of-the-art techniques (e.g., octree/hash-grid techniques) with significantly fewer parameters.
LaRI: Layered Ray Intersections for Single-view 3D Geometric Reasoning
Apr 25, 2025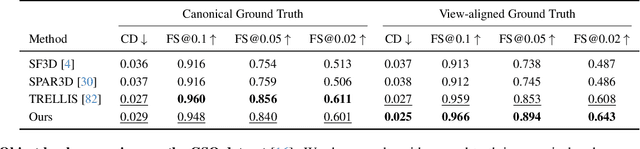
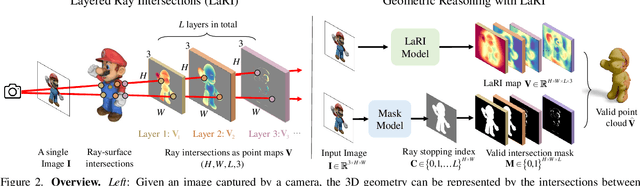
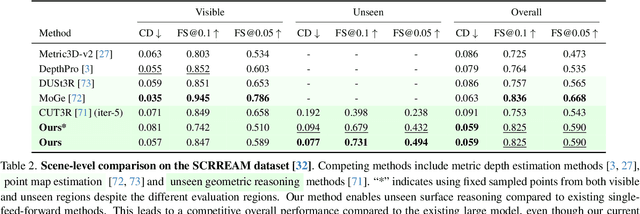

We present layered ray intersections (LaRI), a new method for unseen geometry reasoning from a single image. Unlike conventional depth estimation that is limited to the visible surface, LaRI models multiple surfaces intersected by the camera rays using layered point maps. Benefiting from the compact and layered representation, LaRI enables complete, efficient, and view-aligned geometric reasoning to unify object- and scene-level tasks. We further propose to predict the ray stopping index, which identifies valid intersecting pixels and layers from LaRI's output. We build a complete training data generation pipeline for synthetic and real-world data, including 3D objects and scenes, with necessary data cleaning steps and coordination between rendering engines. As a generic method, LaRI's performance is validated in two scenarios: It yields comparable object-level results to the recent large generative model using 4% of its training data and 17% of its parameters. Meanwhile, it achieves scene-level occluded geometry reasoning in only one feed-forward.