 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefReward-SR: LR-Conditioned Reward Modeling for Preference-Aligned Super-Resolution
Mar 25, 2026Recent advances in generative super-resolution (SR) have greatly improved visual realism, yet existing evaluation and optimization frameworks remain misaligned with human perception. Full-Reference and No-Reference metrics often fail to reflect perceptual preference, either penalizing semantically plausible details due to pixel misalignment or favoring visually sharp but inconsistent artifacts. Moreover, most SR methods rely on ground-truth (GT)-dependent distribution matching, which does not necessarily correspond to human judgments. In this work, we propose RefReward-SR, a low-resolution (LR) reference-aware reward model for preference-aligned SR. Instead of relying on GT supervision or NR evaluation, RefReward-SR assesses high-resolution (HR) reconstructions conditioned on their LR inputs, treating the LR image as a semantic anchor. Leveraging the visual-linguistic priors of a Multimodal Large Language Models (MLLM), it evaluates semantic consistency and plausibility in a reasoning-aware manner. To support this paradigm, we construct RefSR-18K, the first large-scale LR-conditioned preference dataset for SR, providing pairwise rankings based on LR-HR consistency and HR naturalness. We fine-tune the MLLM with Group Relative Policy Optimization (GRPO) using LR-conditioned ranking rewards, and further integrate GRPO into SR model training with RefReward-SR as the core reward signal for preference-aligned generation. Extensive experiments show that our framework achieves substantially better alignment with human judgments, producing reconstructions that preserve semantic consistency while enhancing perceptual plausibility and visual naturalness. Code, models, and datasets will be released upon paper acceptance.
FACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
Mar 03, 2026Autoregressive models for 3D mesh generation suffer from a fundamental limitation: they flatten meshes into long vertex-coordinate sequences. This results in prohibitive computational costs, hindering the efficient synthesis of high-fidelity geometry. We argue this bottleneck stems from operating at the wrong semantic level. We introduce FACE, a novel Autoregressive Autoencoder (ARAE) framework that reconceptualizes the task by generating meshes at the face level. Our one-face-one-token strategy treats each triangle face, the fundamental building block of a mesh, as a single, unified token. This simple yet powerful design reduces the sequence length by a factor of nine, leading to an unprecedented compression ratio of 0.11, halving the previous state-of-the-art. This dramatic efficiency gain does not compromise quality; by pairing our face-level decoder with a powerful VecSet encoder, FACE achieves state-of-the-art reconstruction quality on standard benchmarks. The versatility of the learned latent space is further demonstrated by training a latent diffusion model that achieves high-fidelity, single-image-to-mesh generation. FACE provides a simple, scalable, and powerful paradigm that lowers the barrier to high-quality structured 3D content creation.
iFlame: Interleaving Full and Linear Attention for Efficient Mesh Generation
Mar 20, 2025This paper propose iFlame, a novel transformer-based network architecture for mesh generation. While attention-based models have demonstrated remarkable performance in mesh generation, their quadratic computational complexity limits scalability, particularly for high-resolution 3D data. Conversely, linear attention mechanisms offer lower computational costs but often struggle to capture long-range dependencies, resulting in suboptimal outcomes. To address this trade-off, we propose an interleaving autoregressive mesh generation framework that combines the efficiency of linear attention with the expressive power of full attention mechanisms. To further enhance efficiency and leverage the inherent structure of mesh representations, we integrate this interleaving approach into an hourglass architecture, which significantly boosts efficiency. Our approach reduces training time while achieving performance comparable to pure attention-based models. To improve inference efficiency, we implemented a caching algorithm that almost doubles the speed and reduces the KV cache size by seven-eighths compared to the original Transformer. We evaluate our framework on ShapeNet and Objaverse, demonstrating its ability to generate high-quality 3D meshes efficiently. Our results indicate that the proposed interleaving framework effectively balances computational efficiency and generative performance, making it a practical solution for mesh generation. The training takes only 2 days with 4 GPUs on 39k data with a maximum of 4k faces on Objaverse.
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expression
Dec 13, 2024



Audio-driven talking head generation necessitates seamless integration of audio and visual data amidst the challenges posed by diverse input portraits and intricate correlations between audio and facial motions. In response, we propose a robust framework GoHD designed to produce highly realistic, expressive, and controllable portrait videos from any reference identity with any motion. GoHD innovates with three key modules: Firstly, an animation module utilizing latent navigation is introduced to improve the generalization ability across unseen input styles. This module achieves high disentanglement of motion and identity, and it also incorporates gaze orientation to rectify unnatural eye movements that were previously overlooked. Secondly, a conformer-structured conditional diffusion model is designed to guarantee head poses that are aware of prosody. Thirdly, to estimate lip-synchronized and realistic expressions from the input audio within limited training data, a two-stage training strategy is devised to decouple frequent and frame-wise lip motion distillation from the generation of other more temporally dependent but less audio-related motions, e.g., blinks and frowns. Extensive experiments validate GoHD's advanced generalization capabilities, demonstrating its effectiveness in generating realistic talking face results on arbitrary subjects.
PointCFormer: a Relation-based Progressive Feature Extraction Network for Point Cloud Completion
Dec 11, 2024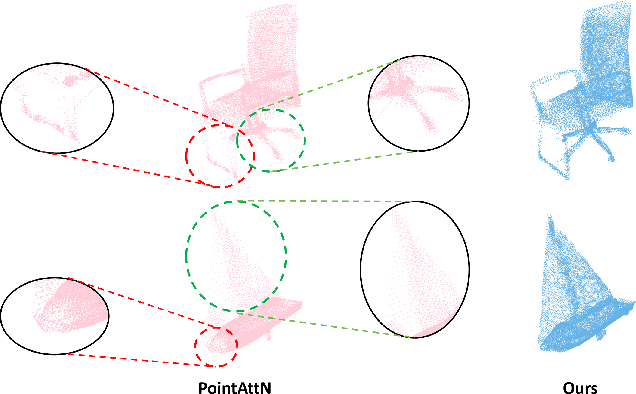
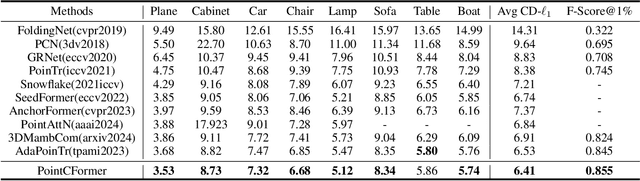
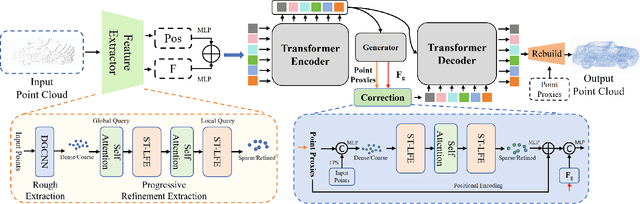
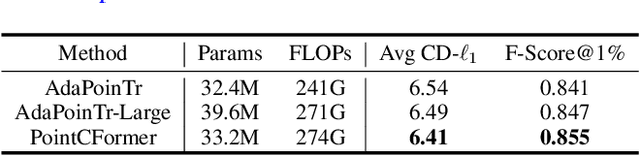
Point cloud completion aims to reconstruct the complete 3D shape from incomplete point clouds, and it is crucial for tasks such as 3D object detection and segmentation. Despite the continuous advances in point cloud analysis techniques, feature extraction methods are still confronted with apparent limitations. The sparse sampling of point clouds, used as inputs in most methods, often results in a certain loss of global structure information. Meanwhile, traditional local feature extraction methods usually struggle to capture the intricate geometric details. To overcome these drawbacks, we introduce PointCFormer, a transformer framework optimized for robust global retention and precise local detail capture in point cloud completion. This framework embraces several key advantages. First, we propose a relation-based local feature extraction method to perceive local delicate geometry characteristics. This approach establishes a fine-grained relationship metric between the target point and its k-nearest neighbors, quantifying each neighboring point's contribution to the target point's local features. Secondly, we introduce a progressive feature extractor that integrates our local feature perception method with self-attention. Starting with a denser sampling of points as input, it iteratively queries long-distance global dependencies and local neighborhood relationships. This extractor maintains enhanced global structure and refined local details, without generating substantial computational overhead. Additionally, we develop a correction module after generating point proxies in the latent space to reintroduce denser information from the input points, enhancing the representation capability of the point proxies. PointCFormer demonstrates state-of-the-art performance on several widely used benchmarks.
OCMG-Net: Neural Oriented Normal Refinement for Unstructured Point Clouds
Sep 02, 2024We present a robust refinement method for estimating oriented normals from unstructured point clouds. In contrast to previous approaches that either suffer from high computational complexity or fail to achieve desirable accuracy, our novel framework incorporates sign orientation and data augmentation in the feature space to refine the initial oriented normals, striking a balance between efficiency and accuracy. To address the issue of noise-caused direction inconsistency existing in previous approaches, we introduce a new metric called the Chamfer Normal Distance, which faithfully minimizes the estimation error by correcting the annotated normal with the closest point found on the potentially clean point cloud. This metric not only tackles the challenge but also aids in network training and significantly enhances network robustness against noise. Moreover, we propose an innovative dual-parallel architecture that integrates Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion, which enables the network to capture intricate geometric details more effectively and notably reduces ambiguity in scale selection. Extensive experiments demonstrate the superiority and versatility of our method in both unoriented and oriented normal estimation tasks across synthetic and real-world datasets among indoor and outdoor scenarios. The code is available at https://github.com/YingruiWoo/OCMG-Net.git.
E$^3$-Net: Efficient E-Equivariant Normal Estimation Network
Jun 01, 2024Point cloud normal estimation is a fundamental task in 3D geometry processing. While recent learning-based methods achieve notable advancements in normal prediction, they often overlook the critical aspect of equivariance. This results in inefficient learning of symmetric patterns. To address this issue, we propose E3-Net to achieve equivariance for normal estimation. We introduce an efficient random frame method, which significantly reduces the training resources required for this task to just 1/8 of previous work and improves the accuracy. Further, we design a Gaussian-weighted loss function and a receptive-aware inference strategy that effectively utilizes the local properties of point clouds. Our method achieves superior results on both synthetic and real-world datasets, and outperforms current state-of-the-art techniques by a substantial margin. We improve RMSE by 4% on the PCPNet dataset, 2.67% on the SceneNN dataset, and 2.44% on the FamousShape dataset.
TCAN: Text-oriented Cross Attention Network for Multimodal Sentiment Analysis
Apr 06, 2024



Multimodal Sentiment Analysis (MSA) endeavors to understand human sentiment by leveraging language, visual, and acoustic modalities. Despite the remarkable performance exhibited by previous MSA approaches, the presence of inherent multimodal heterogeneities poses a challenge, with the contribution of different modalities varying considerably. Past research predominantly focused on improving representation learning techniques and feature fusion strategies. However, many of these efforts overlooked the variation in semantic richness among different modalities, treating each modality uniformly. This approach may lead to underestimating the significance of strong modalities while overemphasizing the importance of weak ones. Motivated by these insights, we introduce a Text-oriented Cross-Attention Network (TCAN), emphasizing the predominant role of the text modality in MSA. Specifically, for each multimodal sample, by taking unaligned sequences of the three modalities as inputs, we initially allocate the extracted unimodal features into a visual-text and an acoustic-text pair. Subsequently, we implement self-attention on the text modality and apply text-queried cross-attention to the visual and acoustic modalities. To mitigate the influence of noise signals and redundant features, we incorporate a gated control mechanism into the framework. Additionally, we introduce unimodal joint learning to gain a deeper understanding of homogeneous emotional tendencies across diverse modalities through backpropagation. Experimental results demonstrate that TCAN consistently outperforms state-of-the-art MSA methods on two datasets (CMU-MOSI and CMU-MOSEI).
Deep Learning-based Image and Video Inpainting: A Survey
Jan 07, 2024Image and video inpainting is a classic problem in computer vision and computer graphics, aiming to fill in the plausible and realistic content in the missing areas of images and videos. With the advance of deep learning, this problem has achieved significant progress recently. The goal of this paper is to comprehensively review the deep learning-based methods for image and video inpainting. Specifically, we sort existing methods into different categories from the perspective of their high-level inpainting pipeline, present different deep learning architectures, including CNN, VAE, GAN, diffusion models, etc., and summarize techniques for module design. We review the training objectives and the common benchmark datasets. We present evaluation metrics for low-level pixel and high-level perceptional similarity, conduct a performance evaluation, and discuss the strengths and weaknesses of representative inpainting methods. We also discuss related real-world applications. Finally, we discuss open challenges and suggest potential future research directions.
CMG-Net: Robust Normal Estimation for Point Clouds via Chamfer Normal Distance and Multi-scale Geometry
Dec 14, 2023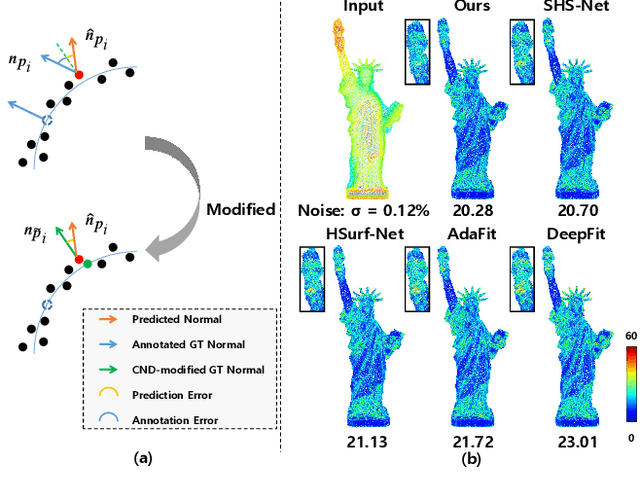
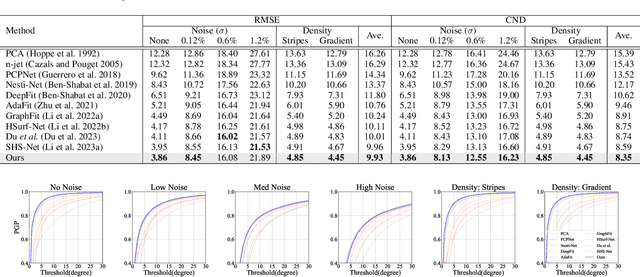
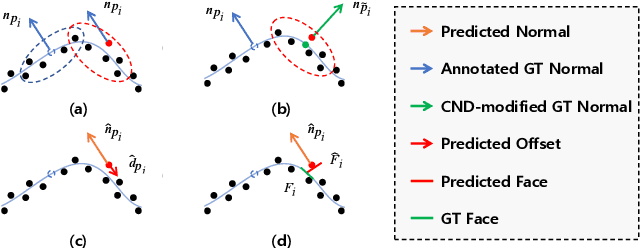
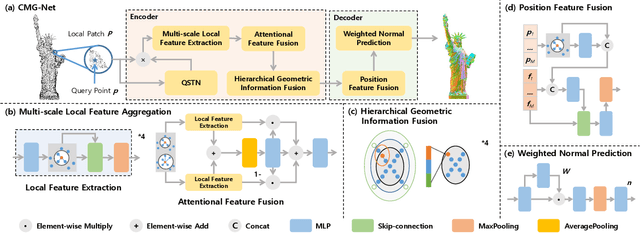
This work presents an accurate and robust method for estimating normals from point clouds. In contrast to predecessor approaches that minimize the deviations between the annotated and the predicted normals directly, leading to direction inconsistency, we first propose a new metric termed Chamfer Normal Distance to address this issue. This not only mitigates the challenge but also facilitates network training and substantially enhances the network robustness against noise. Subsequently, we devise an innovative architecture that encompasses Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion. This design empowers the network to capture intricate geometric details more effectively and alleviate the ambiguity in scale selection. Extensive experiments demonstrate that our method achieves the state-of-the-art performance on both synthetic and real-world datasets, particularly in scenarios contaminated by noise. Our implementation is available at https://github.com/YingruiWoo/CMG-Net_Pytorch.