 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearnShield: Shielding Forgotten Privacy against Unlearning Inversion
Jan 28, 2026Machine unlearning is an emerging technique that aims to remove the influence of specific data from trained models, thereby enhancing privacy protection. However, recent research has uncovered critical privacy vulnerabilities, showing that adversaries can exploit unlearning inversion to reconstruct data that was intended to be erased. Despite the severity of this threat, dedicated defenses remain lacking. To address this gap, we propose UnlearnShield, the first defense specifically tailored to counter unlearning inversion. UnlearnShield introduces directional perturbations in the cosine representation space and regulates them through a constraint module to jointly preserve model accuracy and forgetting efficacy, thereby reducing inversion risk while maintaining utility. Experiments demonstrate that it achieves a good trade-off among privacy protection, accuracy, and forgetting.
Erosion Attack for Adversarial Training to Enhance Semantic Segmentation Robustness
Jan 21, 2026Existing segmentation models exhibit significant vulnerability to adversarial attacks.To improve robustness, adversarial training incorporates adversarial examples into model training. However, existing attack methods consider only global semantic information and ignore contextual semantic relationships within the samples, limiting the effectiveness of adversarial training. To address this issue, we propose EroSeg-AT, a vulnerability-aware adversarial training framework that leverages EroSeg to generate adversarial examples. EroSeg first selects sensitive pixels based on pixel-level confidence and then progressively propagates perturbations to higher-confidence pixels, effectively disrupting the semantic consistency of the samples. Experimental results show that, compared to existing methods, our approach significantly improves attack effectiveness and enhances model robustness under adversarial training.
Enhancing Text-to-Image Generation via End-Edge Collaborative Hybrid Super-Resolution
Jan 21, 2026Artificial Intelligence-Generated Content (AIGC) has made significant strides, with high-resolution text-to-image (T2I) generation becoming increasingly critical for improving users' Quality of Experience (QoE). Although resource-constrained edge computing adequately supports fast low-resolution T2I generations, achieving high-resolution output still faces the challenge of ensuring image fidelity at the cost of latency. To address this, we first investigate the performance of super-resolution (SR) methods for image enhancement, confirming a fundamental trade-off that lightweight learning-based SR struggles to recover fine details, while diffusion-based SR achieves higher fidelity at a substantial computational cost. Motivated by these observations, we propose an end-edge collaborative generation-enhancement framework. Upon receiving a T2I generation task, the system first generates a low-resolution image based on adaptively selected denoising steps and super-resolution scales at the edge side, which is then partitioned into patches and processed by a region-aware hybrid SR policy. This policy applies a diffusion-based SR model to foreground patches for detail recovery and a lightweight learning-based SR model to background patches for efficient upscaling, ultimately stitching the enhanced ones into the high-resolution image. Experiments show that our system reduces service latency by 33% compared with baselines while maintaining competitive image quality.
UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
Dec 12, 2025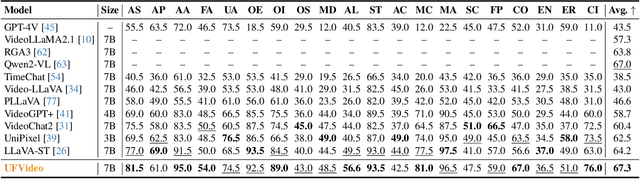
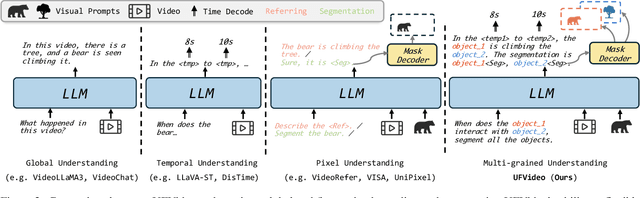
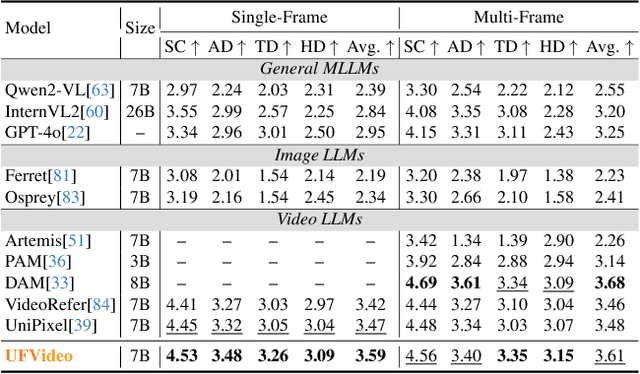
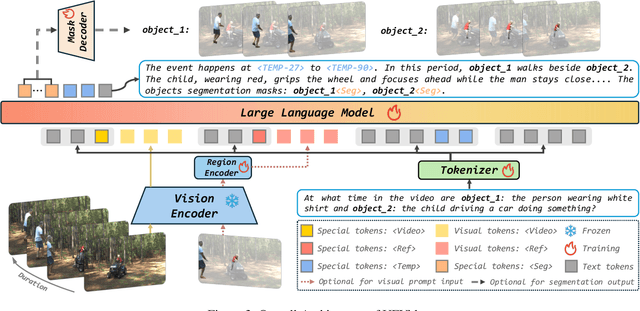
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.
Towards Real-World Deepfake Detection: A Diverse In-the-wild Dataset of Forgery Faces
Oct 09, 2025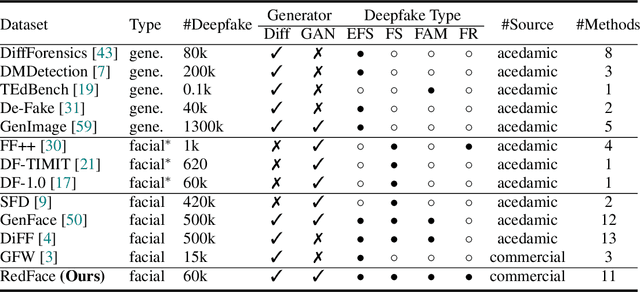


Deepfakes, leveraging advanced AIGC (Artificial Intelligence-Generated Content) techniques, create hyper-realistic synthetic images and videos of human faces, posing a significant threat to the authenticity of social media. While this real-world threat is increasingly prevalent, existing academic evaluations and benchmarks for detecting deepfake forgery often fall short to achieve effective application for their lack of specificity, limited deepfake diversity, restricted manipulation techniques.To address these limitations, we introduce RedFace (Real-world-oriented Deepfake Face), a specialized facial deepfake dataset, comprising over 60,000 forged images and 1,000 manipulated videos derived from authentic facial features, to bridge the gap between academic evaluations and real-world necessity. Unlike prior benchmarks, which typically rely on academic methods to generate deepfakes, RedFace utilizes 9 commercial online platforms to integrate the latest deepfake technologies found "in the wild", effectively simulating real-world black-box scenarios.Moreover, RedFace's deepfakes are synthesized using bespoke algorithms, allowing it to capture diverse and evolving methods used by real-world deepfake creators. Extensive experimental results on RedFace (including cross-domain, intra-domain, and real-world social network dissemination simulations) verify the limited practicality of existing deepfake detection schemes against real-world applications. We further perform a detailed analysis of the RedFace dataset, elucidating the reason of its impact on detection performance compared to conventional datasets. Our dataset is available at: https://github.com/kikyou-220/RedFace.
Say One Thing, Do Another? Diagnosing Reasoning-Execution Gaps in VLM-Powered Mobile-Use Agents
Oct 02, 2025Mobile-use agents powered by vision-language models (VLMs) have shown great potential in interpreting natural language instructions and generating corresponding actions based on mobile graphical user interface. Recent studies suggest that incorporating chain-of-thought (CoT) reasoning tends to improve the execution accuracy. However, existing evaluations emphasize execution accuracy while neglecting whether CoT reasoning aligns with ground-truth actions. This oversight fails to assess potential reasoning-execution gaps, which in turn foster over-trust: users relying on seemingly plausible CoTs may unknowingly authorize harmful actions, potentially resulting in financial loss or trust crisis. In this work, we introduce a new evaluation framework to diagnose reasoning-execution gaps. At its core lies Ground-Truth Alignment (GTA), which measures whether the action implied by a CoT matches the ground-truth action. By combining GTA with the standard Exact Match (EM) metric, we jointly assess both the reasoning accuracy and execution accuracy. This joint perspective reveals two types of reasoning-execution gaps: (i) Execution Gap (EG), where the reasoning correctly identifies the correct action but execution fails, and (ii) Reasoning Gap (RG), where execution succeeds but reasoning process conflicts with the actual execution. Experimental results across a wide range of mobile interaction tasks reveal that reasoning-execution gaps are prevalent, with execution gaps occurring more frequently than reasoning gaps. Moreover, while scaling up model size reduces the overall gap, sizable execution gaps persist even in the largest models. Further analysis shows that our framework reliably reflects systematic EG/RG patterns in state-of-the-art models. These findings offer concrete diagnostics and support the development of more trustworthy mobile-use agents.
Towards Reliable Forgetting: A Survey on Machine Unlearning Verification, Challenges, and Future Directions
Jun 18, 2025With growing demands for privacy protection, security, and legal compliance (e.g., GDPR), machine unlearning has emerged as a critical technique for ensuring the controllability and regulatory alignment of machine learning models. However, a fundamental challenge in this field lies in effectively verifying whether unlearning operations have been successfully and thoroughly executed. Despite a growing body of work on unlearning techniques, verification methodologies remain comparatively underexplored and often fragmented. Existing approaches lack a unified taxonomy and a systematic framework for evaluation. To bridge this gap, this paper presents the first structured survey of machine unlearning verification methods. We propose a taxonomy that organizes current techniques into two principal categories -- behavioral verification and parametric verification -- based on the type of evidence used to assess unlearning fidelity. We examine representative methods within each category, analyze their underlying assumptions, strengths, and limitations, and identify potential vulnerabilities in practical deployment. In closing, we articulate a set of open problems in current verification research, aiming to provide a foundation for developing more robust, efficient, and theoretically grounded unlearning verification mechanisms.
Test-Time Backdoor Detection for Object Detection Models
Mar 19, 2025Object detection models are vulnerable to backdoor attacks, where attackers poison a small subset of training samples by embedding a predefined trigger to manipulate prediction. Detecting poisoned samples (i.e., those containing triggers) at test time can prevent backdoor activation. However, unlike image classification tasks, the unique characteristics of object detection -- particularly its output of numerous objects -- pose fresh challenges for backdoor detection. The complex attack effects (e.g., "ghost" object emergence or "vanishing" object) further render current defenses fundamentally inadequate. To this end, we design TRAnsformation Consistency Evaluation (TRACE), a brand-new method for detecting poisoned samples at test time in object detection. Our journey begins with two intriguing observations: (1) poisoned samples exhibit significantly more consistent detection results than clean ones across varied backgrounds. (2) clean samples show higher detection consistency when introduced to different focal information. Based on these phenomena, TRACE applies foreground and background transformations to each test sample, then assesses transformation consistency by calculating the variance in objects confidences. TRACE achieves black-box, universal backdoor detection, with extensive experiments showing a 30% improvement in AUROC over state-of-the-art defenses and resistance to adaptive attacks.
NumbOD: A Spatial-Frequency Fusion Attack Against Object Detectors
Dec 22, 2024With the advancement of deep learning, object detectors (ODs) with various architectures have achieved significant success in complex scenarios like autonomous driving. Previous adversarial attacks against ODs have been focused on designing customized attacks targeting their specific structures (e.g., NMS and RPN), yielding some results but simultaneously constraining their scalability. Moreover, most efforts against ODs stem from image-level attacks originally designed for classification tasks, resulting in redundant computations and disturbances in object-irrelevant areas (e.g., background). Consequently, how to design a model-agnostic efficient attack to comprehensively evaluate the vulnerabilities of ODs remains challenging and unresolved. In this paper, we propose NumbOD, a brand-new spatial-frequency fusion attack against various ODs, aimed at disrupting object detection within images. We directly leverage the features output by the OD without relying on its internal structures to craft adversarial examples. Specifically, we first design a dual-track attack target selection strategy to select high-quality bounding boxes from OD outputs for targeting. Subsequently, we employ directional perturbations to shift and compress predicted boxes and change classification results to deceive ODs. Additionally, we focus on manipulating the high-frequency components of images to confuse ODs' attention on critical objects, thereby enhancing the attack efficiency. Our extensive experiments on nine ODs and two datasets show that NumbOD achieves powerful attack performance and high stealthiness.
Breaking Barriers in Physical-World Adversarial Examples: Improving Robustness and Transferability via Robust Feature
Dec 22, 2024



As deep neural networks (DNNs) are widely applied in the physical world, many researches are focusing on physical-world adversarial examples (PAEs), which introduce perturbations to inputs and cause the model's incorrect outputs. However, existing PAEs face two challenges: unsatisfactory attack performance (i.e., poor transferability and insufficient robustness to environment conditions), and difficulty in balancing attack effectiveness with stealthiness, where better attack effectiveness often makes PAEs more perceptible. In this paper, we explore a novel perturbation-based method to overcome the challenges. For the first challenge, we introduce a strategy Deceptive RF injection based on robust features (RFs) that are predictive, robust to perturbations, and consistent across different models. Specifically, it improves the transferability and robustness of PAEs by covering RFs of other classes onto the predictive features in clean images. For the second challenge, we introduce another strategy Adversarial Semantic Pattern Minimization, which removes most perturbations and retains only essential adversarial patterns in AEsBased on the two strategies, we design our method Robust Feature Coverage Attack (RFCoA), comprising Robust Feature Disentanglement and Adversarial Feature Fusion. In the first stage, we extract target class RFs in feature space. In the second stage, we use attention-based feature fusion to overlay these RFs onto predictive features of clean images and remove unnecessary perturbations. Experiments show our method's superior transferability, robustness, and stealthiness compared to existing state-of-the-art methods. Additionally, our method's effectiveness can extend to Large Vision-Language Models (LVLMs), indicating its potential applicability to more complex tasks.