 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real-AD: A Modular Sim-to-Real Framework for Deploying VLM-Guided Reinforcement Learning in Real-World Autonomous Driving
Apr 03, 2026Deploying reinforcement learning policies trained in simulation to real autonomous vehicles remains a fundamental challenge, particularly for VLM-guided RL frameworks whose policies are typically learned with simulator-native observations and simulator-coupled action semantics that are unavailable on physical platforms. This paper presents Sim2Real-AD, a modular framework for zero-shot sim-to-real transfer of CARLA-trained VLM-guided RL policies to full-scale vehicles without any real-world RL training data. The framework decomposes the transfer problem into four components: a Geometric Observation Bridge (GOB) that converts monocular front-view images into simulator-compatible bird's-eye-view (BEV) observations, a Physics-Aware Action Mapping (PAM) that translates policy outputs into platform-agnostic physical commands, a Two-Phase Progressive Training (TPT) strategy that stabilizes adaptation by separating action-space and observation-space transfer, and a Real-time Deployment Pipeline (RDP) that integrates perception, policy inference, control conversion, and safety monitoring for closed-loop execution. Simulation experiments show that the framework preserves the relative performance ordering of representative RL algorithms across different reward paradigms and validate the contribution of each module. Zero-shot deployment on a full-scale Ford E-Transit achieves success rates of 90%, 80%, and 75% in car-following, obstacle avoidance, and stop-sign interaction scenarios, respectively. To the best of our knowledge, this study is among the first to demonstrate zero-shot closed-loop deployment of a CARLA-trained VLM-guided RL policy on a full-scale real vehicle without any real-world RL training data. The demo video and code are available at: https://zilin-huang.github.io/Sim2Real-AD-website/.
TagaVLM: Topology-Aware Global Action Reasoning for Vision-Language Navigation
Mar 03, 2026Vision-Language Navigation (VLN) presents a unique challenge for Large Vision-Language Models (VLMs) due to their inherent architectural mismatch: VLMs are primarily pretrained on static, disembodied vision-language tasks, which fundamentally clash with the dynamic, embodied, and spatially-structured nature of navigation. Existing large-model-based methods often resort to converting rich visual and spatial information into text, forcing models to implicitly infer complex visual-topological relationships or limiting their global action capabilities. To bridge this gap, we propose TagaVLM (Topology-Aware Global Action reasoning), an end-to-end framework that explicitly injects topological structures into the VLM backbone. To introduce topological edge information, Spatial Topology Aware Residual Attention (STAR-Att) directly integrates it into the VLM's self-attention mechanism, enabling intrinsic spatial reasoning while preserving pretrained knowledge. To enhance topological node information, an Interleaved Navigation Prompt strengthens node-level visual-text alignment. Finally, with the embedded topological graph, the model is capable of global action reasoning, allowing for robust path correction. On the R2R benchmark, TagaVLM achieves state-of-the-art performance among large-model-based methods, with a Success Rate (SR) of 51.09% and SPL of 47.18 in unseen environments, outperforming prior work by 3.39% in SR and 9.08 in SPL. This demonstrates that, for embodied spatial reasoning, targeted enhancements on smaller open-source VLMs can be more effective than brute-force model scaling. The code will be released upon publication.Project page: https://apex-bjut.github.io/Taga-VLM
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025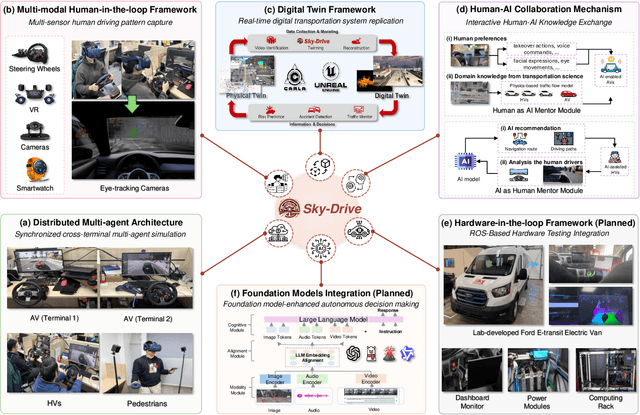
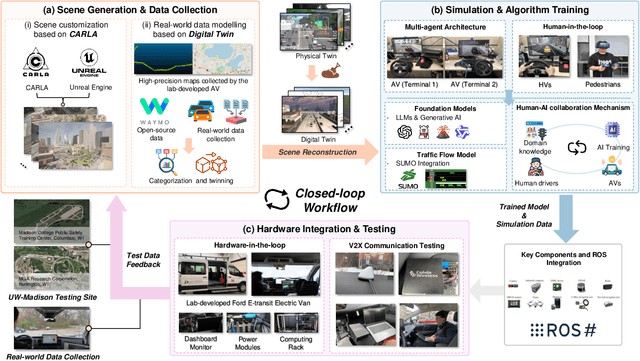
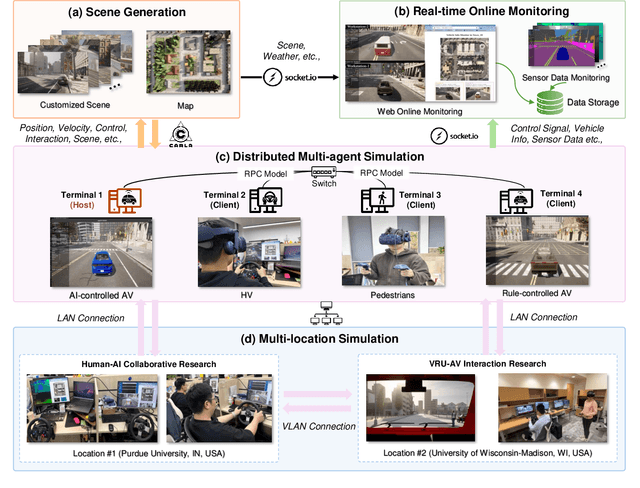
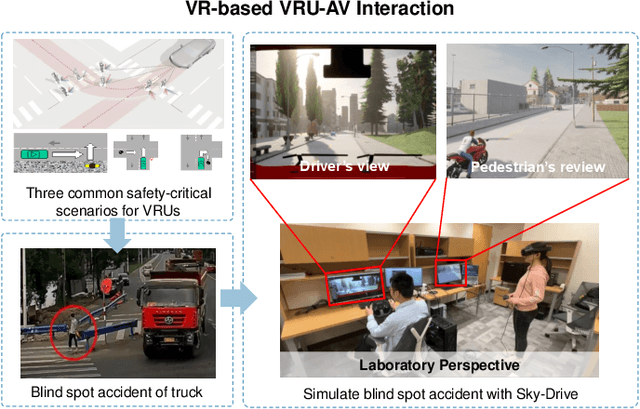
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
In-context Learning for Automated Driving Scenarios
May 07, 2024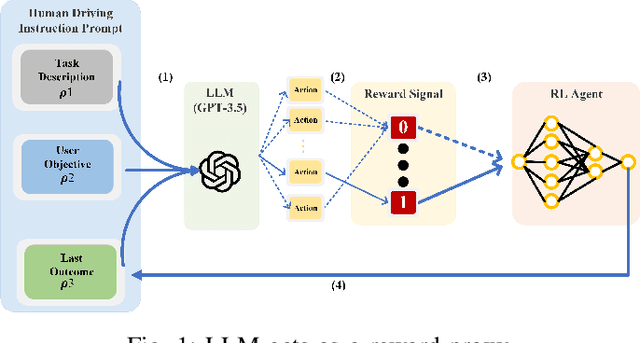
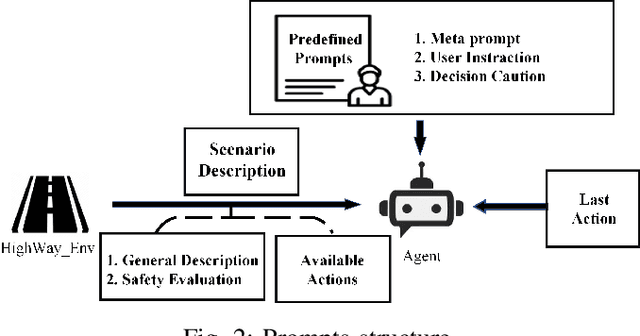
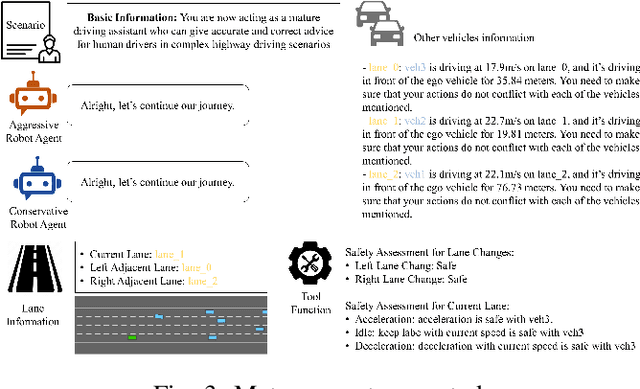

One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
IME: Integrating Multi-curvature Shared and Specific Embedding for Temporal Knowledge Graph Completion
Mar 28, 2024



Temporal Knowledge Graphs (TKGs) incorporate a temporal dimension, allowing for a precise capture of the evolution of knowledge and reflecting the dynamic nature of the real world. Typically, TKGs contain complex geometric structures, with various geometric structures interwoven. However, existing Temporal Knowledge Graph Completion (TKGC) methods either model TKGs in a single space or neglect the heterogeneity of different curvature spaces, thus constraining their capacity to capture these intricate geometric structures. In this paper, we propose a novel Integrating Multi-curvature shared and specific Embedding (IME) model for TKGC tasks. Concretely, IME models TKGs into multi-curvature spaces, including hyperspherical, hyperbolic, and Euclidean spaces. Subsequently, IME incorporates two key properties, namely space-shared property and space-specific property. The space-shared property facilitates the learning of commonalities across different curvature spaces and alleviates the spatial gap caused by the heterogeneous nature of multi-curvature spaces, while the space-specific property captures characteristic features. Meanwhile, IME proposes an Adjustable Multi-curvature Pooling (AMP) approach to effectively retain important information. Furthermore, IME innovatively designs similarity, difference, and structure loss functions to attain the stated objective. Experimental results clearly demonstrate the superior performance of IME over existing state-of-the-art TKGC models.
TPLLM: A Traffic Prediction Framework Based on Pretrained Large Language Models
Mar 04, 2024



Traffic prediction constitutes a pivotal facet within the purview of Intelligent Transportation Systems (ITS), and the attainment of highly precise predictions holds profound significance for efficacious traffic management. The precision of prevailing deep learning-driven traffic prediction models typically sees an upward trend with a rise in the volume of training data. However, the procurement of comprehensive spatiotemporal datasets for traffic is often fraught with challenges, primarily stemming from the substantial costs associated with data collection and retention. Consequently, developing a model that can achieve accurate predictions and good generalization ability in areas with limited historical traffic data is a challenging problem. It is noteworthy that the rapidly advancing pretrained Large Language Models (LLMs) of recent years have demonstrated exceptional proficiency in cross-modality knowledge transfer and few-shot learning. Recognizing the sequential nature of traffic data, similar to language, we introduce TPLLM, a novel traffic prediction framework leveraging LLMs. In this framework, we construct a sequence embedding layer based on Convolutional Neural Networks (CNNs) and a graph embedding layer based on Graph Convolutional Networks (GCNs) to extract sequence features and spatial features, respectively. These are subsequently integrated to form inputs that are suitable for LLMs. A Low-Rank Adaptation (LoRA) fine-tuning approach is applied to TPLLM, thereby facilitating efficient learning and minimizing computational demands. Experiments on two real-world datasets demonstrate that TPLLM exhibits commendable performance in both full-sample and few-shot prediction scenarios, effectively supporting the development of ITS in regions with scarce historical traffic data.
Center Focusing Network for Real-Time LiDAR Panoptic Segmentation
Nov 16, 2023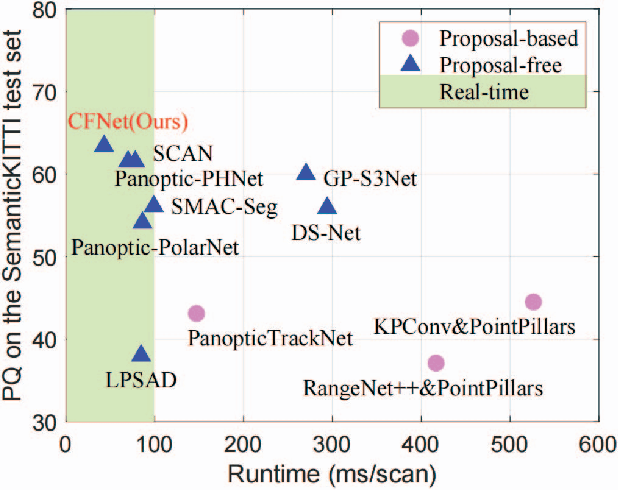
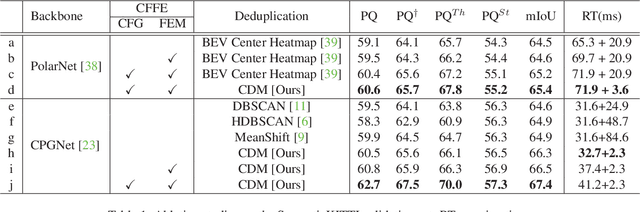
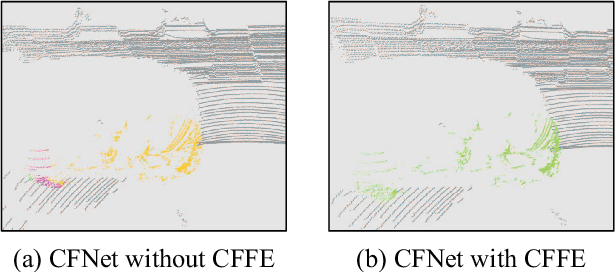
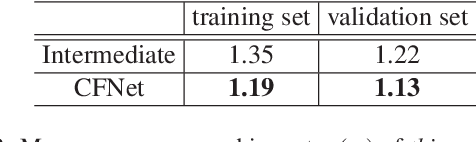
LiDAR panoptic segmentation facilitates an autonomous vehicle to comprehensively understand the surrounding objects and scenes and is required to run in real time. The recent proposal-free methods accelerate the algorithm, but their effectiveness and efficiency are still limited owing to the difficulty of modeling non-existent instance centers and the costly center-based clustering modules. To achieve accurate and real-time LiDAR panoptic segmentation, a novel center focusing network (CFNet) is introduced. Specifically, the center focusing feature encoding (CFFE) is proposed to explicitly understand the relationships between the original LiDAR points and virtual instance centers by shifting the LiDAR points and filling in the center points. Moreover, to leverage the redundantly detected centers, a fast center deduplication module (CDM) is proposed to select only one center for each instance. Experiments on the SemanticKITTI and nuScenes panoptic segmentation benchmarks demonstrate that our CFNet outperforms all existing methods by a large margin and is 1.6 times faster than the most efficient method. The code is available at https://github.com/GangZhang842/CFNet.
A Survey on Temporal Knowledge Graph Completion: Taxonomy, Progress, and Prospects
Aug 04, 2023Temporal characteristics are prominently evident in a substantial volume of knowledge, which underscores the pivotal role of Temporal Knowledge Graphs (TKGs) in both academia and industry. However, TKGs often suffer from incompleteness for three main reasons: the continuous emergence of new knowledge, the weakness of the algorithm for extracting structured information from unstructured data, and the lack of information in the source dataset. Thus, the task of Temporal Knowledge Graph Completion (TKGC) has attracted increasing attention, aiming to predict missing items based on the available information. In this paper, we provide a comprehensive review of TKGC methods and their details. Specifically, this paper mainly consists of three components, namely, 1)Background, which covers the preliminaries of TKGC methods, loss functions required for training, as well as the dataset and evaluation protocol; 2)Interpolation, that estimates and predicts the missing elements or set of elements through the relevant available information. It further categorizes related TKGC methods based on how to process temporal information; 3)Extrapolation, which typically focuses on continuous TKGs and predicts future events, and then classifies all extrapolation methods based on the algorithms they utilize. We further pinpoint the challenges and discuss future research directions of TKGC.
CaEGCN: Cross-Attention Fusion based Enhanced Graph Convolutional Network for Clustering
Jan 18, 2021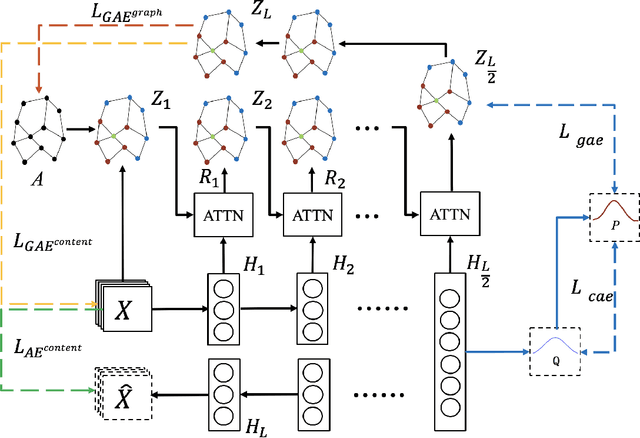
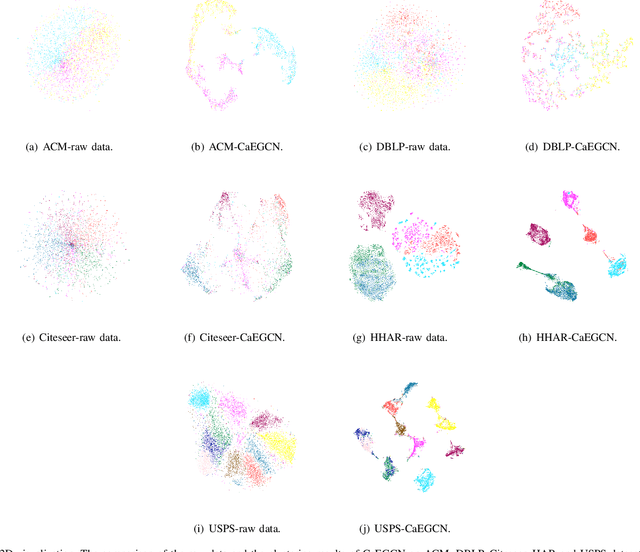
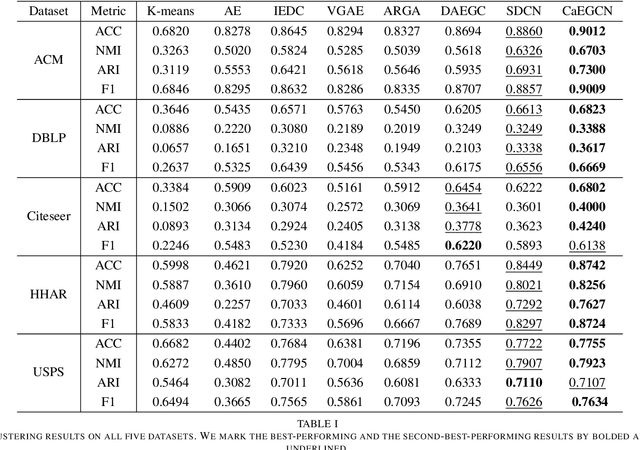

With the powerful learning ability of deep convolutional networks, deep clustering methods can extract the most discriminative information from individual data and produce more satisfactory clustering results. However, existing deep clustering methods usually ignore the relationship between the data. Fortunately, the graph convolutional network can handle such relationship, opening up a new research direction for deep clustering. In this paper, we propose a cross-attention based deep clustering framework, named Cross-Attention Fusion based Enhanced Graph Convolutional Network (CaEGCN), which contains four main modules: the cross-attention fusion module which innovatively concatenates the Content Auto-encoder module (CAE) relating to the individual data and Graph Convolutional Auto-encoder module (GAE) relating to the relationship between the data in a layer-by-layer manner, and the self-supervised model that highlights the discriminative information for clustering tasks. While the cross-attention fusion module fuses two kinds of heterogeneous representation, the CAE module supplements the content information for the GAE module, which avoids the over-smoothing problem of GCN. In the GAE module, two novel loss functions are proposed that reconstruct the content and relationship between the data, respectively. Finally, the self-supervised module constrains the distributions of the middle layer representations of CAE and GAE to be consistent. Experimental results on different types of datasets prove the superiority and robustness of the proposed CaEGCN.