 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvision4D: Envisioning Visual Futures via Feed-forward 4D Gaussian Splatting for Autonomous Driving
Jun 09, 2026Forecasting the future evolution of dynamic scenes is crucial in autonomous driving. However, existing feed-forward paradigms are primarily designed for interpolation. When extended to future extrapolation, they suffer from ghosting artifacts under large displacements and are constrained by simplified motion assumptions or strict future priors. To overcome these challenges, we propose Envision4D, a fully self-supervised feed-forward framework for pose-free future extrapolation. Specifically, we introduce a Future Pose Prediction module that infers future camera parameters via an iterative denoising process. Furthermore, to capture non-linear dynamics, we propose In-layer Temporal Attention and employ Conditioned Motion Lifting, which transforms the highly uncertain extrapolation process into robust relational mappings. Finally, a Progressive Training Strategy is utilized to stabilize unsupervised motion learning against error accumulation. Extensive experiments demonstrate that Envision4D achieves state-of-the-art performance, significantly outperforming existing methods in future view synthesis.
Physics-informed Deep Mixture-of-Koopmans Vehicle Dynamics Model with Dual-branch Encoder for Distributed Electric-drive Trucks
Mar 18, 2026Advanced autonomous driving systems require accurate vehicle dynamics modeling. However, identifying a precise dynamics model remains challenging due to strong nonlinearities and the coupled longitudinal and lateral dynamic characteristics. Previous research has employed physics-based analytical models or neural networks to construct vehicle dynamics representations. Nevertheless, these approaches often struggle to simultaneously achieve satisfactory performance in terms of system identification efficiency, modeling accuracy, and compatibility with linear control strategies. In this paper, we propose a fully data-driven dynamics modeling method tailored for complex distributed electric-drive trucks (DETs), leveraging Koopman operator theory to represent highly nonlinear dynamics in a lifted linear embedding space. To achieve high-precision modeling, we first propose a novel dual-branch encoder which encodes dynamic states and provides a powerful basis for the proposed Koopman-based methods entitled KODE. A physics-informed supervision mechanism, grounded in the geometric consistency of temporal vehicle motion, is incorporated into the training process to facilitate effective learning of both the encoder and the Koopman operator. Furthermore, to accommodate the diverse driving patterns of DETs, we extend the vanilla Koopman operator to a mixture-of-Koopman operator framework, enhancing modeling capability. Simulations conducted in a high-fidelity TruckSim environment and real-world experiments demonstrate that the proposed approach achieves state-of-the-art performance in long-term dynamics state estimation.
ForSim: Stepwise Forward Simulation for Traffic Policy Fine-Tuning
Feb 02, 2026As the foundation of closed-loop training and evaluation in autonomous driving, traffic simulation still faces two fundamental challenges: covariate shift introduced by open-loop imitation learning and limited capacity to reflect the multimodal behaviors observed in real-world traffic. Although recent frameworks such as RIFT have partially addressed these issues through group-relative optimization, their forward simulation procedures remain largely non-reactive, leading to unrealistic agent interactions within the virtual domain and ultimately limiting simulation fidelity. To address these issues, we propose ForSim, a stepwise closed-loop forward simulation paradigm. At each virtual timestep, the traffic agent propagates the virtual candidate trajectory that best spatiotemporally matches the reference trajectory through physically grounded motion dynamics, thereby preserving multimodal behavioral diversity while ensuring intra-modality consistency. Other agents are updated with stepwise predictions, yielding coherent and interaction-aware evolution. When incorporated into the RIFT traffic simulation framework, ForSim operates in conjunction with group-relative optimization to fine-tune traffic policy. Extensive experiments confirm that this integration consistently improves safety while maintaining efficiency, realism, and comfort. These results underscore the importance of modeling closed-loop multimodal interactions within forward simulation and enhance the fidelity and reliability of traffic simulation for autonomous driving. Project Page: https://currychen77.github.io/ForSim/
DTCCL: Disengagement-Triggered Contrastive Continual Learning for Autonomous Bus Planners
Dec 22, 2025Autonomous buses run on fixed routes but must operate in open, dynamic urban environments. Disengagement events on these routes are often geographically concentrated and typically arise from planner failures in highly interactive regions. Such policy-level failures are difficult to correct using conventional imitation learning, which easily overfits to sparse disengagement data. To address this issue, this paper presents a Disengagement-Triggered Contrastive Continual Learning (DTCCL) framework that enables autonomous buses to improve planning policies through real-world operation. Each disengagement triggers cloud-based data augmentation that generates positive and negative samples by perturbing surrounding agents while preserving route context. Contrastive learning refines policy representations to better distinguish safe and unsafe behaviors, and continual updates are applied in a cloud-edge loop without human supervision. Experiments on urban bus routes demonstrate that DTCCL improves overall planning performance by 48.6 percent compared with direct retraining, validating its effectiveness for scalable, closed-loop policy improvement in autonomous public transport.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
LEGO-Motion: Learning-Enhanced Grids with Occupancy Instance Modeling for Class-Agnostic Motion Prediction
Mar 10, 2025



Accurate and reliable spatial and motion information plays a pivotal role in autonomous driving systems. However, object-level perception models struggle with handling open scenario categories and lack precise intrinsic geometry. On the other hand, occupancy-based class-agnostic methods excel in representing scenes but fail to ensure physics consistency and ignore the importance of interactions between traffic participants, hindering the model's ability to learn accurate and reliable motion. In this paper, we introduce a novel occupancy-instance modeling framework for class-agnostic motion prediction tasks, named LEGO-Motion, which incorporates instance features into Bird's Eye View (BEV) space. Our model comprises (1) a BEV encoder, (2) an Interaction-Augmented Instance Encoder, and (3) an Instance-Enhanced BEV Encoder, improving both interaction relationships and physics consistency within the model, thereby ensuring a more accurate and robust understanding of the environment. Extensive experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches. Furthermore, the effectiveness of our framework is validated on the advanced FMCW LiDAR benchmark, showcasing its practical applicability and generalization capabilities. The code will be made publicly available to facilitate further research.
PriorMotion: Generative Class-Agnostic Motion Prediction with Raster-Vector Motion Field Priors
Dec 05, 2024



Reliable perception of spatial and motion information is crucial for safe autonomous navigation. Traditional approaches typically fall into two categories: object-centric and class-agnostic methods. While object-centric methods often struggle with missed detections, leading to inaccuracies in motion prediction, many class-agnostic methods focus heavily on encoder design, often overlooking important priors like rigidity and temporal consistency, leading to suboptimal performance, particularly with sparse LiDAR data at distant region. To address these issues, we propose $\textbf{PriorMotion}$, a generative framework that extracts rasterized and vectorized scene representations to model spatio-temporal priors. Our model comprises a BEV encoder, an Raster-Vector prior Encoder, and a Spatio-Temporal prior Generator, improving both spatial and temporal consistency in motion prediction. Additionally, we introduce a standardized evaluation protocol for class-agnostic motion prediction. Experiments on the nuScenes dataset show that PriorMotion achieves state-of-the-art performance, with further validation on advanced FMCW LiDAR confirming its robustness.
FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
Nov 27, 2024



Ensuring safe, comfortable, and efficient navigation is a critical goal for autonomous driving systems. While end-to-end models trained on large-scale datasets excel in common driving scenarios, they often struggle with rare, long-tail events. Recent progress in large language models (LLMs) has introduced enhanced reasoning capabilities, but their computational demands pose challenges for real-time decision-making and precise planning. This paper presents FASIONAD, a novel dual-system framework inspired by the cognitive model "Thinking, Fast and Slow." The fast system handles routine navigation tasks using rapid, data-driven path planning, while the slow system focuses on complex reasoning and decision-making in challenging or unfamiliar situations. A dynamic switching mechanism based on score distribution and feedback allows seamless transitions between the two systems. Visual prompts generated by the fast system enable human-like reasoning in the slow system, which provides high-quality feedback to enhance the fast system's decision-making. To evaluate FASIONAD, we introduce a new benchmark derived from the nuScenes dataset, specifically designed to differentiate fast and slow scenarios. FASIONAD achieves state-of-the-art performance on this benchmark, establishing a new standard for frameworks integrating fast and slow cognitive processes in autonomous driving. This approach paves the way for more adaptive, human-like autonomous driving systems.
High Definition Map Mapping and Update: A General Overview and Future Directions
Sep 15, 2024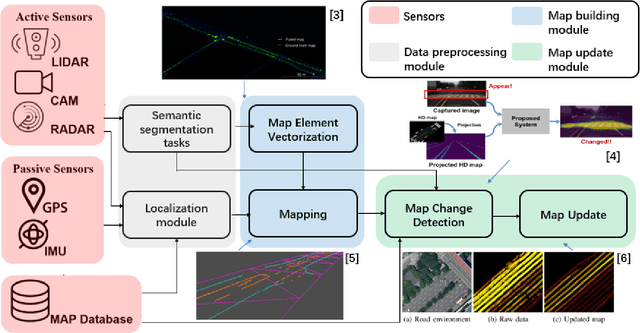
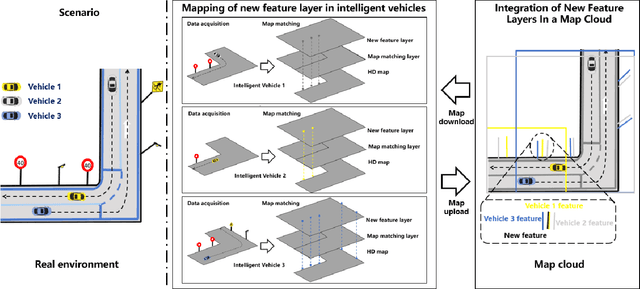
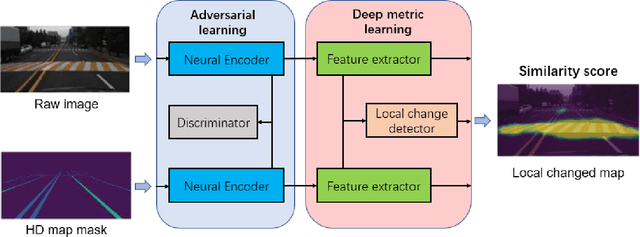
Along with the rapid growth of autonomous vehicles (AVs), more and more demands are required for environment perception technology. Among others, HD mapping has become one of the more prominent roles in helping the vehicle realize essential tasks such as localization and path planning. While increasing research efforts have been directed toward HD Map development. However, a comprehensive overview of the overall HD map mapping and update framework is still lacking. This article introduces the development and current state of the algorithm involved in creating HD map mapping and its maintenance. As part of this study, the primary data preprocessing approach of processing raw data to information ready to feed for mapping and update purposes, semantic segmentation, and localization are also briefly reviewed. Moreover, the map taxonomy, ontology, and quality assessment are extensively discussed, the map data's general representation method is presented, and the mapping algorithm ranging from SLAM to transformers learning-based approaches are also discussed. The development of the HD map update algorithm, from change detection to the update methods, is also presented. Finally, the authors discuss possible future developments and the remaining challenges in HD map mapping and update technology. This paper simultaneously serves as a position paper and tutorial to those new to HD map mapping and update domains.