 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
Nov 27, 2024



Ensuring safe, comfortable, and efficient navigation is a critical goal for autonomous driving systems. While end-to-end models trained on large-scale datasets excel in common driving scenarios, they often struggle with rare, long-tail events. Recent progress in large language models (LLMs) has introduced enhanced reasoning capabilities, but their computational demands pose challenges for real-time decision-making and precise planning. This paper presents FASIONAD, a novel dual-system framework inspired by the cognitive model "Thinking, Fast and Slow." The fast system handles routine navigation tasks using rapid, data-driven path planning, while the slow system focuses on complex reasoning and decision-making in challenging or unfamiliar situations. A dynamic switching mechanism based on score distribution and feedback allows seamless transitions between the two systems. Visual prompts generated by the fast system enable human-like reasoning in the slow system, which provides high-quality feedback to enhance the fast system's decision-making. To evaluate FASIONAD, we introduce a new benchmark derived from the nuScenes dataset, specifically designed to differentiate fast and slow scenarios. FASIONAD achieves state-of-the-art performance on this benchmark, establishing a new standard for frameworks integrating fast and slow cognitive processes in autonomous driving. This approach paves the way for more adaptive, human-like autonomous driving systems.
End-to-End Probabilistic Geometry-Guided Regression for 6DoF Object Pose Estimation
Sep 18, 20246D object pose estimation is the problem of identifying the position and orientation of an object relative to a chosen coordinate system, which is a core technology for modern XR applications. State-of-the-art 6D object pose estimators directly predict an object pose given an object observation. Due to the ill-posed nature of the pose estimation problem, where multiple different poses can correspond to a single observation, generating additional plausible estimates per observation can be valuable. To address this, we reformulate the state-of-the-art algorithm GDRNPP and introduce EPRO-GDR (End-to-End Probabilistic Geometry-Guided Regression). Instead of predicting a single pose per detection, we estimate a probability density distribution of the pose. Using the evaluation procedure defined by the BOP (Benchmark for 6D Object Pose Estimation) Challenge, we test our approach on four of its core datasets and demonstrate superior quantitative results for EPRO-GDR on LM-O, YCB-V, and ITODD. Our probabilistic solution shows that predicting a pose distribution instead of a single pose can improve state-of-the-art single-view pose estimation while providing the additional benefit of being able to sample multiple meaningful pose candidates.
Unsupervised Sentence Representation Learning with Frequency-induced Adversarial Tuning and Incomplete Sentence Filtering
May 15, 2023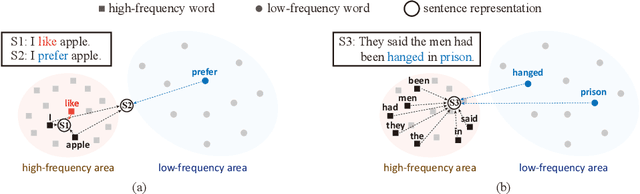
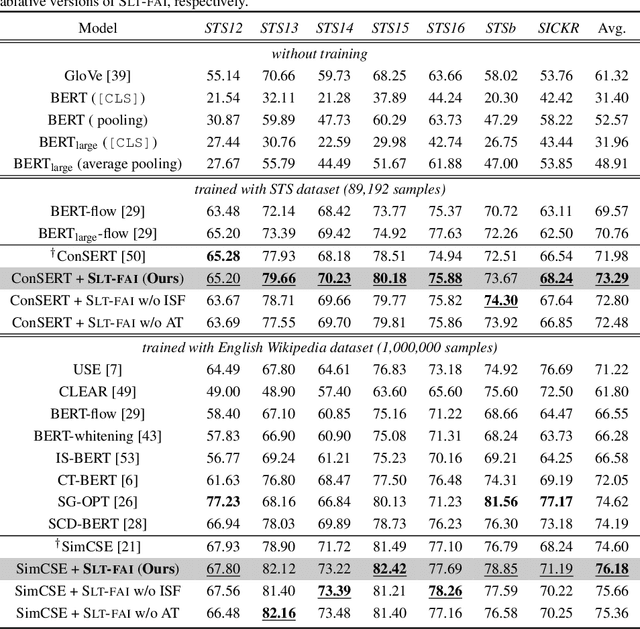

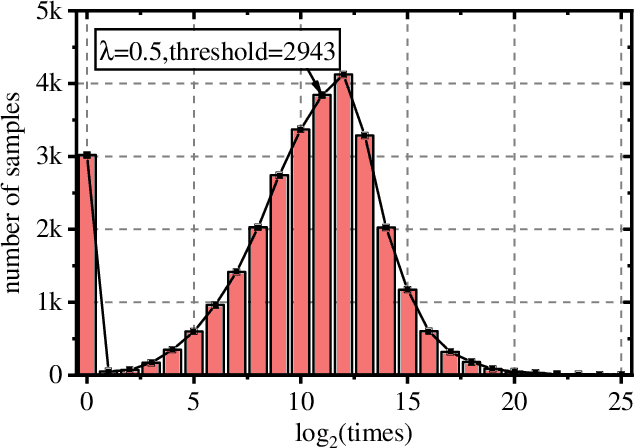
Pre-trained Language Model (PLM) is nowadays the mainstay of Unsupervised Sentence Representation Learning (USRL). However, PLMs are sensitive to the frequency information of words from their pre-training corpora, resulting in anisotropic embedding space, where the embeddings of high-frequency words are clustered but those of low-frequency words disperse sparsely. This anisotropic phenomenon results in two problems of similarity bias and information bias, lowering the quality of sentence embeddings. To solve the problems, we fine-tune PLMs by leveraging the frequency information of words and propose a novel USRL framework, namely Sentence Representation Learning with Frequency-induced Adversarial tuning and Incomplete sentence filtering (SLT-FAI). We calculate the word frequencies over the pre-training corpora of PLMs and assign words thresholding frequency labels. With them, (1) we incorporate a similarity discriminator used to distinguish the embeddings of high-frequency and low-frequency words, and adversarially tune the PLM with it, enabling to achieve uniformly frequency-invariant embedding space; and (2) we propose a novel incomplete sentence detection task, where we incorporate an information discriminator to distinguish the embeddings of original sentences and incomplete sentences by randomly masking several low-frequency words, enabling to emphasize the more informative low-frequency words. Our SLT-FAI is a flexible and plug-and-play framework, and it can be integrated with existing USRL techniques. We evaluate SLT-FAI with various backbones on benchmark datasets. Empirical results indicate that SLT-FAI can be superior to the existing USRL baselines. Our code is released in \url{https://github.com/wangbing1416/SLT-FAI}.