 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoder as Editor: Code-driven Interpretable Molecular Optimization
Oct 16, 2025Molecular optimization is a central task in drug discovery that requires precise structural reasoning and domain knowledge. While large language models (LLMs) have shown promise in generating high-level editing intentions in natural language, they often struggle to faithfully execute these modifications-particularly when operating on non-intuitive representations like SMILES. We introduce MECo, a framework that bridges reasoning and execution by translating editing actions into executable code. MECo reformulates molecular optimization for LLMs as a cascaded framework: generating human-interpretable editing intentions from a molecule and property goal, followed by translating those intentions into executable structural edits via code generation. Our approach achieves over 98% accuracy in reproducing held-out realistic edits derived from chemical reactions and target-specific compound pairs. On downstream optimization benchmarks spanning physicochemical properties and target activities, MECo substantially improves consistency by 38-86 percentage points to 90%+ and achieves higher success rates over SMILES-based baselines while preserving structural similarity. By aligning intention with execution, MECo enables consistent, controllable and interpretable molecular design, laying the foundation for high-fidelity feedback loops and collaborative human-AI workflows in drug discovery.
Low-Cost Test-Time Adaptation for Robust Video Editing
Jul 29, 2025

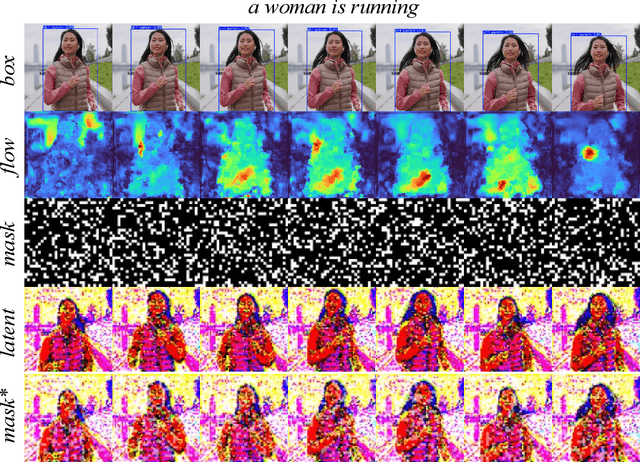

Video editing is a critical component of content creation that transforms raw footage into coherent works aligned with specific visual and narrative objectives. Existing approaches face two major challenges: temporal inconsistencies due to failure in capturing complex motion patterns, and overfitting to simple prompts arising from limitations in UNet backbone architectures. While learning-based methods can enhance editing quality, they typically demand substantial computational resources and are constrained by the scarcity of high-quality annotated data. In this paper, we present Vid-TTA, a lightweight test-time adaptation framework that personalizes optimization for each test video during inference through self-supervised auxiliary tasks. Our approach incorporates a motion-aware frame reconstruction mechanism that identifies and preserves crucial movement regions, alongside a prompt perturbation and reconstruction strategy that strengthens model robustness to diverse textual descriptions. These innovations are orchestrated by a meta-learning driven dynamic loss balancing mechanism that adaptively adjusts the optimization process based on video characteristics. Extensive experiments demonstrate that Vid-TTA significantly improves video temporal consistency and mitigates prompt overfitting while maintaining low computational overhead, offering a plug-and-play performance boost for existing video editing models.
AANet: Virtual Screening under Structural Uncertainty via Alignment and Aggregation
Jun 06, 2025Virtual screening (VS) is a critical component of modern drug discovery, yet most existing methods--whether physics-based or deep learning-based--are developed around holo protein structures with known ligand-bound pockets. Consequently, their performance degrades significantly on apo or predicted structures such as those from AlphaFold2, which are more representative of real-world early-stage drug discovery, where pocket information is often missing. In this paper, we introduce an alignment-and-aggregation framework to enable accurate virtual screening under structural uncertainty. Our method comprises two core components: (1) a tri-modal contrastive learning module that aligns representations of the ligand, the holo pocket, and cavities detected from structures, thereby enhancing robustness to pocket localization error; and (2) a cross-attention based adapter for dynamically aggregating candidate binding sites, enabling the model to learn from activity data even without precise pocket annotations. We evaluated our method on a newly curated benchmark of apo structures, where it significantly outperforms state-of-the-art methods in blind apo setting, improving the early enrichment factor (EF1%) from 11.75 to 37.19. Notably, it also maintains strong performance on holo structures. These results demonstrate the promise of our approach in advancing first-in-class drug discovery, particularly in scenarios lacking experimentally resolved protein-ligand complexes.
Optimizing Multi-Round Enhanced Training in Diffusion Models for Improved Preference Understanding
Apr 25, 2025Generative AI has significantly changed industries by enabling text-driven image generation, yet challenges remain in achieving high-resolution outputs that align with fine-grained user preferences. Consequently, multi-round interactions are necessary to ensure the generated images meet expectations. Previous methods enhanced prompts via reward feedback but did not optimize over a multi-round dialogue dataset. In this work, we present a Visual Co-Adaptation (VCA) framework incorporating human-in-the-loop feedback, leveraging a well-trained reward model aligned with human preferences. Using a diverse multi-turn dialogue dataset, our framework applies multiple reward functions, such as diversity, consistency, and preference feedback, while fine-tuning the diffusion model through LoRA, thus optimizing image generation based on user input. We also construct multi-round dialogue datasets of prompts and image pairs aligned with user intent. Experiments demonstrate that our method outperforms state-of-the-art baselines, significantly improving image consistency and alignment with user intent. Our approach consistently surpasses competing models in user satisfaction, especially in multi-turn dialogue scenarios.
Efficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025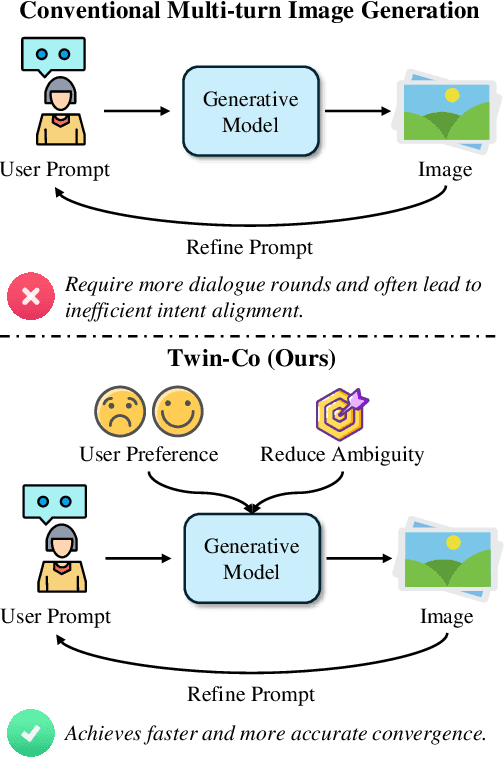
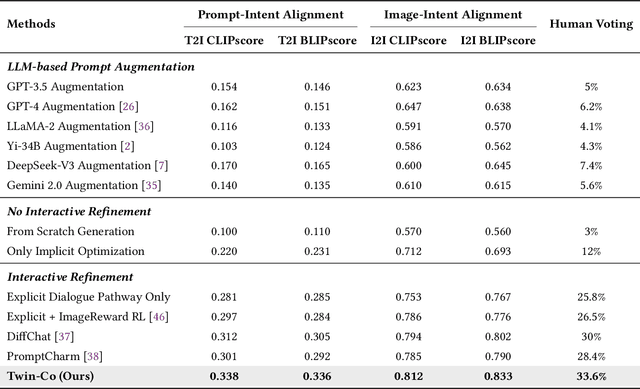
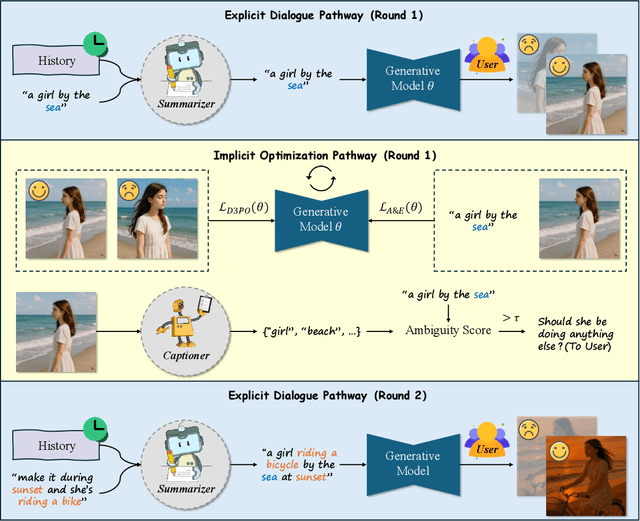

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
DebFlow: Automating Agent Creation via Agent Debate
Mar 31, 2025
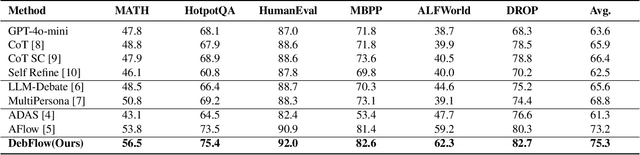
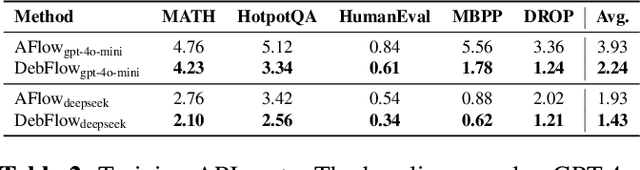
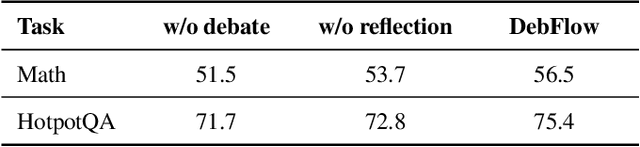
Large language models (LLMs) have demonstrated strong potential and impressive performance in automating the generation and optimization of workflows. However, existing approaches are marked by limited reasoning capabilities, high computational demands, and significant resource requirements. To address these issues, we propose DebFlow, a framework that employs a debate mechanism to optimize workflows and integrates reflexion to improve based on previous experiences. We evaluated our method across six benchmark datasets, including HotpotQA, MATH, and ALFWorld. Our approach achieved a 3\% average performance improvement over the latest baselines, demonstrating its effectiveness in diverse problem domains. In particular, during training, our framework reduces resource consumption by 37\% compared to the state-of-the-art baselines. Additionally, we performed ablation studies. Removing the Debate component resulted in a 4\% performance drop across two benchmark datasets, significantly greater than the 2\% drop observed when the Reflection component was removed. These findings strongly demonstrate the critical role of Debate in enhancing framework performance, while also highlighting the auxiliary contribution of reflexion to overall optimization.
SCORE: Story Coherence and Retrieval Enhancement for AI Narratives
Mar 30, 2025



Large Language Models (LLMs) excel at generating creative narratives but struggle with long-term coherence and emotional consistency in complex stories. To address this, we propose SCORE (Story Coherence and Retrieval Enhancement), a framework integrating three components: 1) Dynamic State Tracking (monitoring objects/characters via symbolic logic), 2) Context-Aware Summarization (hierarchical episode summaries for temporal progression), and 3) Hybrid Retrieval (combining TF-IDF keyword relevance with cosine similarity-based semantic embeddings). The system employs a temporally-aligned Retrieval-Augmented Generation (RAG) pipeline to validate contextual consistency. Evaluations show SCORE achieves 23.6% higher coherence (NCI-2.0 benchmark), 89.7% emotional consistency (EASM metric), and 41.8% fewer hallucinations versus baseline GPT models. Its modular design supports incremental knowledge graph construction for persistent story memory and multi-LLM backend compatibility, offering an explainable solution for industrial-scale narrative systems requiring long-term consistency.
MARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
MaRI: Material Retrieval Integration across Domains
Mar 11, 2025Accurate material retrieval is critical for creating realistic 3D assets. Existing methods rely on datasets that capture shape-invariant and lighting-varied representations of materials, which are scarce and face challenges due to limited diversity and inadequate real-world generalization. Most current approaches adopt traditional image search techniques. They fall short in capturing the unique properties of material spaces, leading to suboptimal performance in retrieval tasks. Addressing these challenges, we introduce MaRI, a framework designed to bridge the feature space gap between synthetic and real-world materials. MaRI constructs a shared embedding space that harmonizes visual and material attributes through a contrastive learning strategy by jointly training an image and a material encoder, bringing similar materials and images closer while separating dissimilar pairs within the feature space. To support this, we construct a comprehensive dataset comprising high-quality synthetic materials rendered with controlled shape variations and diverse lighting conditions, along with real-world materials processed and standardized using material transfer techniques. Extensive experiments demonstrate the superior performance, accuracy, and generalization capabilities of MaRI across diverse and complex material retrieval tasks, outperforming existing methods.