 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Domain Benchmark for Detecting AI-Generated Text-Rich Images from GPT-Image-2
Jun 17, 2026Text-rich images often contain privacy-sensitive, transactional, or decision-relevant information. As recent multimodal image generation models become increasingly capable of synthesizing realistic textual content and structured visual designs, detecting AI-generated text-rich images has become an important challenge for digital trust and content authenticity. Existing benchmarks, however, largely focus on object-centric images and provide limited coverage of scenarios where textual semantics and layout organization are central. In this paper, we introduce a multi-domain benchmark for detecting text-rich images generated by OpenAI's GPT Image 2. The benchmark contains 8,602 images across six representative categories: commercial posters, infographics, academic posters, receipts, tables, and UI screenshots. Using this benchmark, we evaluate five representative AI-generated image detectors in a zero-shot setting and analyze their overall, category-wise, and post-processing robustness. Our results show that detector performance is highly domain-dependent: methods that perform well in some categories often fail on others, and even the strongest conventional detector exhibits severe sensitivity to JPEG compression. We further conduct an exploratory evaluation with a multimodal vision-language model, revealing both its promise and its limitations on structured formats. These findings highlight the need for text- and layout-aware detection methods for modern AI-generated images. Our dataset is released at XXX.
FlyMirage: A Fully Automated Generation Pipeline for Diverse and Scalable UAV Flight Data via Generative World Model
May 19, 2026In the field of Vision-Language Navigation (VLN), aerial datasets remain limited in their ability to combine scale, diversity, and realism, often relying on either costly real-world scenes or visually limited simulations. To address these challenges, we introduce FlyMirage, a highly scalable and fully automated data generation pipeline for aerial VLN. Our approach leverages large language models (LLM) as an environment designer to promote scene diversity, paired with a generative world model that instantiates these designs into high-fidelity 3D Gaussian Splatting (3DGS) scenes. To substantially reduce human labor and ensure the feasibility of flight data, FlyMirage automates scene exploration and semantic information acquisition, and further integrates a dynamically feasible planner for uncrewed aerial vehicle (UAV) trajectory generation. Utilizing this toolchain, we generate a large-scale, diverse, and photorealistic aerial VLN dataset, with dynamically feasible flying trajectories, designed to support the development of next-generation embodied navigation models.
Beyond Cosine Similarity: Zero-Initialized Residual Complex Projection for Aspect-Based Sentiment Analysis
Mar 30, 2026Aspect-Based Sentiment Analysis (ABSA) is fundamentally challenged by representation entanglement, where aspect semantics and sentiment polarities are often conflated in real-valued embedding spaces. Furthermore, standard contrastive learning suffers from false-negative collisions, severely degrading performance on high-frequency aspects. In this paper, we propose a novel framework featuring a Zero-Initialized Residual Complex Projection (ZRCP) and an Anti-collision Masked Angle Loss,inspired by quantum projection and entanglement ideas. Our approach projects textual features into a complex semantic space, systematically utilizing the phase to disentangle sentiment polarities while allowing the amplitude to encode the semantic intensity and lexical richness of subjective descriptions. To tackle the collision bottleneck, we introduce an anti-collision mask that elegantly preserves intra-polarity aspect cohesion while expanding the inter-polarity discriminative margin by over 50%. Experimental results demonstrate that our framework achieves a state-of-the-art Macro-F1 score of 0.8851. Deep geometric analyses further reveal that explicitly penalizing the complex amplitude catastrophically over-regularizes subjective representations, proving that our unconstrained-amplitude and phase-driven objective is crucial for robust, fine-grained sentiment disentanglement.
DebFlow: Automating Agent Creation via Agent Debate
Mar 31, 2025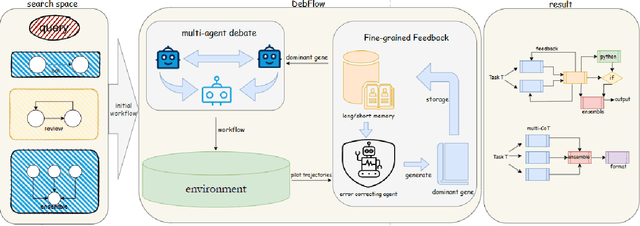
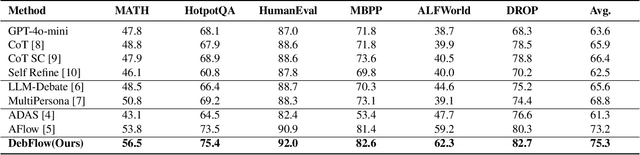
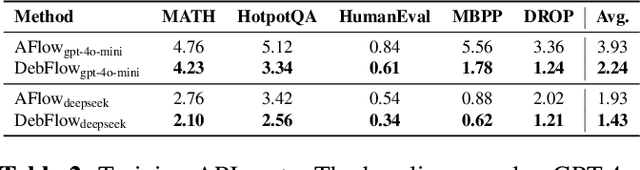
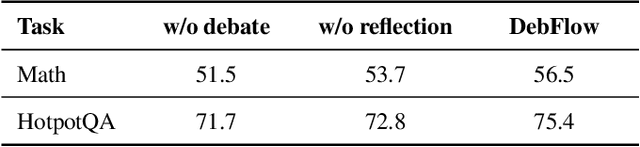
Large language models (LLMs) have demonstrated strong potential and impressive performance in automating the generation and optimization of workflows. However, existing approaches are marked by limited reasoning capabilities, high computational demands, and significant resource requirements. To address these issues, we propose DebFlow, a framework that employs a debate mechanism to optimize workflows and integrates reflexion to improve based on previous experiences. We evaluated our method across six benchmark datasets, including HotpotQA, MATH, and ALFWorld. Our approach achieved a 3\% average performance improvement over the latest baselines, demonstrating its effectiveness in diverse problem domains. In particular, during training, our framework reduces resource consumption by 37\% compared to the state-of-the-art baselines. Additionally, we performed ablation studies. Removing the Debate component resulted in a 4\% performance drop across two benchmark datasets, significantly greater than the 2\% drop observed when the Reflection component was removed. These findings strongly demonstrate the critical role of Debate in enhancing framework performance, while also highlighting the auxiliary contribution of reflexion to overall optimization.
MARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
Enhancing Intent Understanding for Ambiguous Prompts through Human-Machine Co-Adaptation
Jan 25, 2025



Modern image generation systems can produce high-quality visuals, yet user prompts often contain ambiguities, requiring multiple revisions. Existing methods struggle to address the nuanced needs of non-expert users. We propose Visual Co-Adaptation (VCA), a novel framework that iteratively refines prompts and aligns generated images with user preferences. VCA employs a fine-tuned language model with reinforcement learning and multi-turn dialogues for prompt disambiguation. Key components include the Incremental Context-Enhanced Dialogue Block for interactive clarification, the Semantic Exploration and Disambiguation Module (SESD) leveraging Retrieval-Augmented Generation (RAG) and CLIP scoring, and the Pixel Precision and Consistency Optimization Module (PPCO) for refining image details using Proximal Policy Optimization (PPO). A human-in-the-loop feedback mechanism further improves performance. Experiments show that VCA surpasses models like DALL-E 3 and Stable Diffusion, reducing dialogue rounds to 4.3, achieving a CLIP score of 0.92, and enhancing user satisfaction to 4.73/5. Additionally, we introduce a novel multi-round dialogue dataset with prompt-image pairs and user intent annotations.
Elucidating the Design Choice of Probability Paths in Flow Matching for Forecasting
Oct 04, 2024Flow matching has recently emerged as a powerful paradigm for generative modeling and has been extended to probabilistic time series forecasting in latent spaces. However, the impact of the specific choice of probability path model on forecasting performance remains under-explored. In this work, we demonstrate that forecasting spatio-temporal data with flow matching is highly sensitive to the selection of the probability path model. Motivated by this insight, we propose a novel probability path model designed to improve forecasting performance. Our empirical results across various dynamical system benchmarks show that our model achieves faster convergence during training and improved predictive performance compared to existing probability path models. Importantly, our approach is efficient during inference, requiring only a few sampling steps. This makes our proposed model practical for real-world applications and opens new avenues for probabilistic forecasting.
One-Shot Robust Imitation Learning for Long-Horizon Visuomotor Tasks from Unsegmented Demonstrations
Oct 02, 2024In contrast to single-skill tasks, long-horizon tasks play a crucial role in our daily life, e.g., a pouring task requires a proper concatenation of reaching, grasping and pouring subtasks. As an efficient solution for transferring human skills to robots, imitation learning has achieved great progress over the last two decades. However, when learning long-horizon visuomotor skills, imitation learning often demands a large amount of semantically segmented demonstrations. Moreover, the performance of imitation learning could be susceptible to external perturbation and visual occlusion. In this paper, we exploit dynamical movement primitives and meta-learning to provide a new framework for imitation learning, called Meta-Imitation Learning with Adaptive Dynamical Primitives (MiLa). MiLa allows for learning unsegmented long-horizon demonstrations and adapting to unseen tasks with a single demonstration. MiLa can also resist external disturbances and visual occlusion during task execution. Real-world robotic experiments demonstrate the superiority of MiLa, irrespective of visual occlusion and random perturbations on robots.
Flusion: Integrating multiple data sources for accurate influenza predictions
Jul 26, 2024Over the last ten years, the US Centers for Disease Control and Prevention (CDC) has organized an annual influenza forecasting challenge with the motivation that accurate probabilistic forecasts could improve situational awareness and yield more effective public health actions. Starting with the 2021/22 influenza season, the forecasting targets for this challenge have been based on hospital admissions reported in the CDC's National Healthcare Safety Network (NHSN) surveillance system. Reporting of influenza hospital admissions through NHSN began within the last few years, and as such only a limited amount of historical data are available for this signal. To produce forecasts in the presence of limited data for the target surveillance system, we augmented these data with two signals that have a longer historical record: 1) ILI+, which estimates the proportion of outpatient doctor visits where the patient has influenza; and 2) rates of laboratory-confirmed influenza hospitalizations at a selected set of healthcare facilities. Our model, Flusion, is an ensemble that combines gradient boosting quantile regression models with a Bayesian autoregressive model. The gradient boosting models were trained on all three data signals, while the autoregressive model was trained on only the target signal; all models were trained jointly on data for multiple locations. Flusion was the top-performing model in the CDC's influenza prediction challenge for the 2023/24 season. In this article we investigate the factors contributing to Flusion's success, and we find that its strong performance was primarily driven by the use of a gradient boosting model that was trained jointly on data from multiple surveillance signals and locations. These results indicate the value of sharing information across locations and surveillance signals, especially when doing so adds to the pool of available training data.
Auto-LfD: Towards Closing the Loop for Learning from Demonstrations
Oct 15, 2023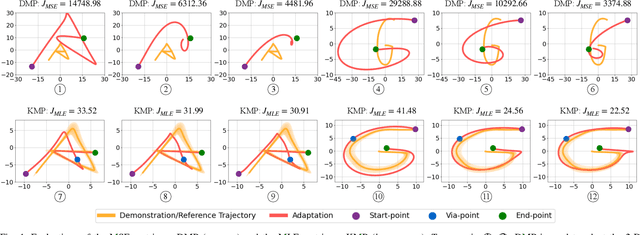
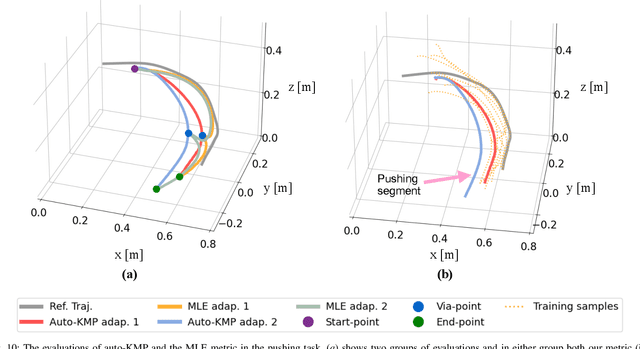
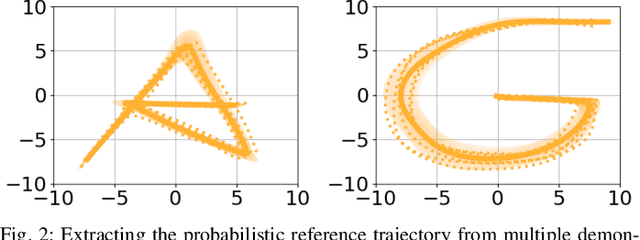
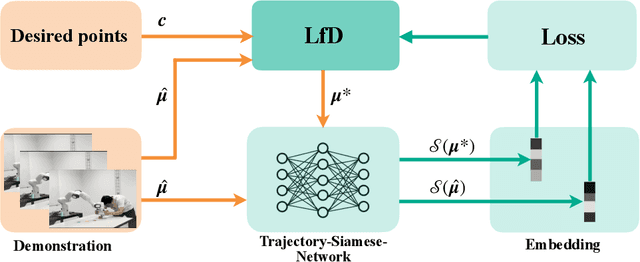
Over the past few years, there have been numerous works towards advancing the generalization capability of robots, among which learning from demonstrations (LfD) has drawn much attention by virtue of its user-friendly and data-efficient nature. While many LfD solutions have been reported, a key question has not been properly addressed: how can we evaluate the generalization performance of LfD? For instance, when a robot draws a letter that needs to pass through new desired points, how does it ensure the new trajectory maintains a similar shape to the demonstration? This question becomes more relevant when a new task is significantly far from the demonstrated region. To tackle this issue, a user often resorts to manual tuning of the hyperparameters of an LfD approach until a satisfactory trajectory is attained. In this paper, we aim to provide closed-loop evaluative feedback for LfD and optimize LfD in an automatic fashion. Specifically, we consider dynamical movement primitives (DMP) and kernelized movement primitives (KMP) as examples and develop a generic optimization framework capable of measuring the generalization performance of DMP and KMP and auto-optimizing their hyperparameters without any human inputs. Evaluations including a peg-in-hole task and a pushing task on a real robot evidence the applicability of our framework.