 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComfySearch: Autonomous Exploration and Reasoning for ComfyUI Workflows
Jan 07, 2026AI-generated content has progressed from monolithic models to modular workflows, especially on platforms like ComfyUI, allowing users to customize complex creative pipelines. However, the large number of components in ComfyUI and the difficulty of maintaining long-horizon structural consistency under strict graph constraints frequently lead to low pass rates and workflows of limited quality. To tackle these limitations, we present ComfySearch, an agentic framework that can effectively explore the component space and generate functional ComfyUI pipelines via validation-guided workflow construction. Experiments demonstrate that ComfySearch substantially outperforms existing methods on complex and creative tasks, achieving higher executability (pass) rates, higher solution rates, and stronger generalization.
DebFlow: Automating Agent Creation via Agent Debate
Mar 31, 2025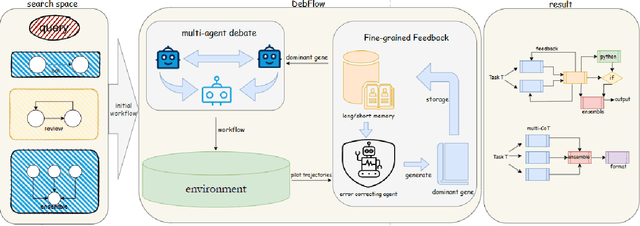
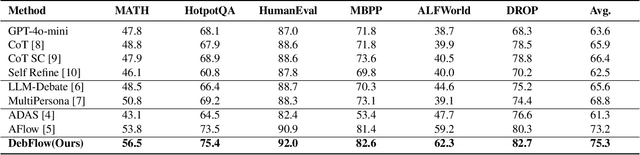
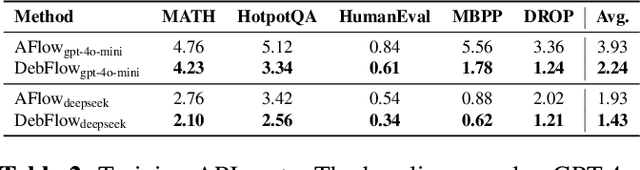
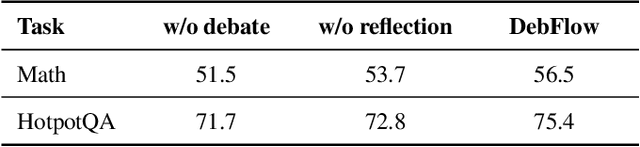
Large language models (LLMs) have demonstrated strong potential and impressive performance in automating the generation and optimization of workflows. However, existing approaches are marked by limited reasoning capabilities, high computational demands, and significant resource requirements. To address these issues, we propose DebFlow, a framework that employs a debate mechanism to optimize workflows and integrates reflexion to improve based on previous experiences. We evaluated our method across six benchmark datasets, including HotpotQA, MATH, and ALFWorld. Our approach achieved a 3\% average performance improvement over the latest baselines, demonstrating its effectiveness in diverse problem domains. In particular, during training, our framework reduces resource consumption by 37\% compared to the state-of-the-art baselines. Additionally, we performed ablation studies. Removing the Debate component resulted in a 4\% performance drop across two benchmark datasets, significantly greater than the 2\% drop observed when the Reflection component was removed. These findings strongly demonstrate the critical role of Debate in enhancing framework performance, while also highlighting the auxiliary contribution of reflexion to overall optimization.
Enhancing Code LLMs with Reinforcement Learning in Code Generation
Dec 29, 2024



With the rapid evolution of large language models (LLM), reinforcement learning (RL) has emerged as a pivotal technique for code generation and optimization in various domains. This paper presents a systematic survey of the application of RL in code optimization and generation, highlighting its role in enhancing compiler optimization, resource allocation, and the development of frameworks and tools. Subsequent sections first delve into the intricate processes of compiler optimization, where RL algorithms are leveraged to improve efficiency and resource utilization. The discussion then progresses to the function of RL in resource allocation, emphasizing register allocation and system optimization. We also explore the burgeoning role of frameworks and tools in code generation, examining how RL can be integrated to bolster their capabilities. This survey aims to serve as a comprehensive resource for researchers and practitioners interested in harnessing the power of RL to advance code generation and optimization techniques.
FALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system
Oct 28, 2024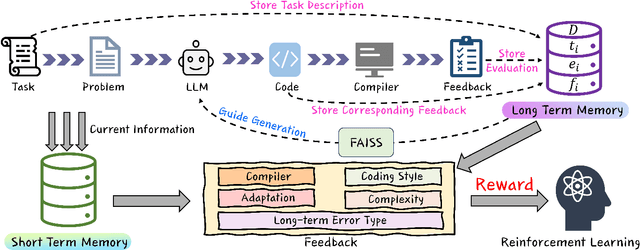
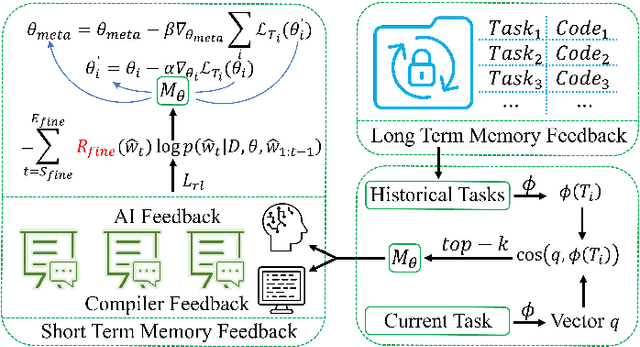
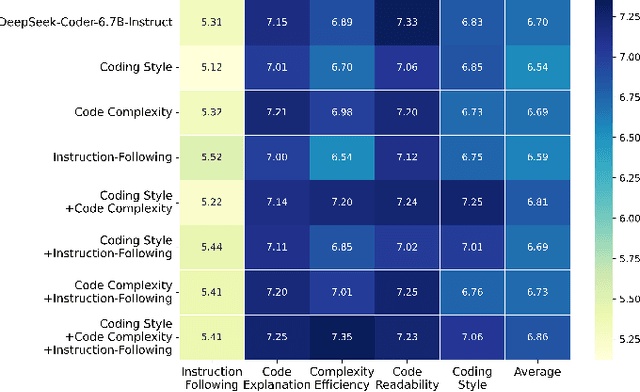
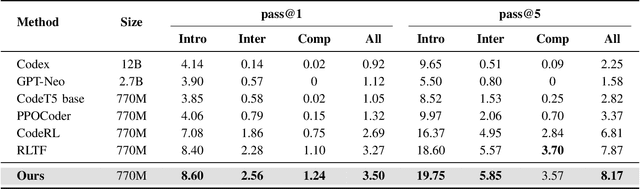
Recently, large language models (LLMs) have achieved significant progress in automated code generation. Despite their strong instruction-following capabilities, these models frequently struggled to align with user intent in coding scenarios. In particular, they were hampered by datasets that lacked diversity and failed to address specialized tasks or edge cases. Furthermore, challenges in supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) led to failures in generating precise, human-intent-aligned code. To tackle these challenges and improve the code generation performance for automated programming systems, we propose Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization (i.e., FALCON). FALCON is structured into two hierarchical levels. From the global level, long-term memory improves code quality by retaining and applying learned knowledge. At the local level, short-term memory allows for the incorporation of immediate feedback from compilers and AI systems. Additionally, we introduce meta-reinforcement learning with feedback rewards to solve the global-local bi-level optimization problem and enhance the model's adaptability across diverse code generation tasks. Extensive experiments demonstrate that our technique achieves state-of-the-art performance, leading other reinforcement learning methods by more than 4.5 percentage points on the MBPP benchmark and 6.1 percentage points on the Humaneval benchmark. The open-sourced code is publicly available at https://github.com/titurte/FALCON.
Role-RL: Online Long-Context Processing with Role Reinforcement Learning for Distinct LLMs in Their Optimal Roles
Sep 26, 2024



Large language models (LLMs) with long-context processing are still challenging because of their implementation complexity, training efficiency and data sparsity. To address this issue, a new paradigm named Online Long-context Processing (OLP) is proposed when we process a document of unlimited length, which typically occurs in the information reception and organization of diverse streaming media such as automated news reporting, live e-commerce, and viral short videos. Moreover, a dilemma was often encountered when we tried to select the most suitable LLM from a large number of LLMs amidst explosive growth aiming for outstanding performance, affordable prices, and short response delays. In view of this, we also develop Role Reinforcement Learning (Role-RL) to automatically deploy different LLMs in their respective roles within the OLP pipeline according to their actual performance. Extensive experiments are conducted on our OLP-MINI dataset and it is found that OLP with Role-RL framework achieves OLP benchmark with an average recall rate of 93.2% and the LLM cost saved by 79.4%. The code and dataset are publicly available at: https://anonymous.4open.science/r/Role-RL.