 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-RL: Online Long-Context Processing with Role Reinforcement Learning for Distinct LLMs in Their Optimal Roles
Sep 26, 2024



Large language models (LLMs) with long-context processing are still challenging because of their implementation complexity, training efficiency and data sparsity. To address this issue, a new paradigm named Online Long-context Processing (OLP) is proposed when we process a document of unlimited length, which typically occurs in the information reception and organization of diverse streaming media such as automated news reporting, live e-commerce, and viral short videos. Moreover, a dilemma was often encountered when we tried to select the most suitable LLM from a large number of LLMs amidst explosive growth aiming for outstanding performance, affordable prices, and short response delays. In view of this, we also develop Role Reinforcement Learning (Role-RL) to automatically deploy different LLMs in their respective roles within the OLP pipeline according to their actual performance. Extensive experiments are conducted on our OLP-MINI dataset and it is found that OLP with Role-RL framework achieves OLP benchmark with an average recall rate of 93.2% and the LLM cost saved by 79.4%. The code and dataset are publicly available at: https://anonymous.4open.science/r/Role-RL.
Hierarchical Modeling of Spatial Cues via Spherical Harmonics for Multi-Channel Speech Enhancement
Sep 19, 2023



Multi-channel speech enhancement utilizes spatial information from multiple microphones to extract the target speech. However, most existing methods do not explicitly model spatial cues, instead relying on implicit learning from multi-channel spectra. To better leverage spatial information, we propose explicitly incorporating spatial modeling by applying spherical harmonic transforms (SHT) to the multi-channel input. In detail, a hierarchical framework is introduced whereby lower order harmonics capturing broader spatial patterns are estimated first, then combined with higher orders to recursively predict finer spatial details. Experiments on TIMIT demonstrate the proposed method can effectively recover target spatial patterns and achieve improved performance over baseline models, using fewer parameters and computations. Explicitly modeling spatial information hierarchically enables more effective multi-channel speech enhancement.
Efficient Multi-Channel Speech Enhancement with Spherical Harmonics Injection for Directional Encoding
Sep 19, 2023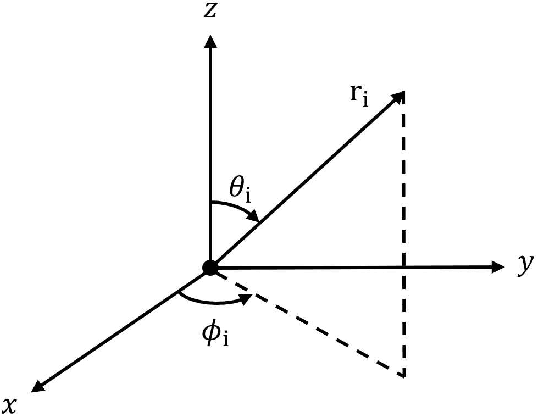

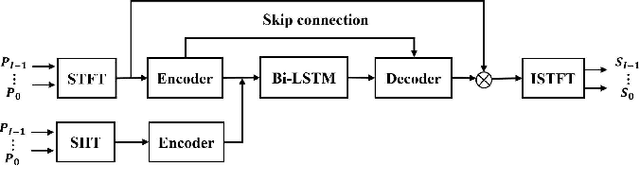

Multi-channel speech enhancement extracts speech using multiple microphones that capture spatial cues. Effectively utilizing directional information is key for multi-channel enhancement. Deep learning shows great potential on multi-channel speech enhancement and often takes short-time Fourier Transform (STFT) as inputs directly. To fully leverage the spatial information, we introduce a method using spherical harmonics transform (SHT) coefficients as auxiliary model inputs. These coefficients concisely represent spatial distributions. Specifically, our model has two encoders, one for the STFT and another for the SHT. By fusing both encoders in the decoder to estimate the enhanced STFT, we effectively incorporate spatial context. Evaluations on TIMIT under varying noise and reverberation show our model outperforms established benchmarks. Remarkably, this is achieved with fewer computations and parameters. By leveraging spherical harmonics to incorporate directional cues, our model efficiently improves the performance of the multi-channel speech enhancement.
PDPCRN: Parallel Dual-Path CRN with Bi-directional Inter-Branch Interactions for Multi-Channel Speech Enhancement
Sep 19, 2023



Multi-channel speech enhancement seeks to utilize spatial information to distinguish target speech from interfering signals. While deep learning approaches like the dual-path convolutional recurrent network (DPCRN) have made strides, challenges persist in effectively modeling inter-channel correlations and amalgamating multi-level information. In response, we introduce the Parallel Dual-Path Convolutional Recurrent Network (PDPCRN). This acoustic modeling architecture has two key innovations. First, a parallel design with separate branches extracts complementary features. Second, bi-directional modules enable cross-branch communication. Together, these facilitate diverse representation fusion and enhanced modeling. Experimental validation on TIMIT datasets underscores the prowess of PDPCRN. Notably, against baseline models like the standard DPCRN, PDPCRN not only outperforms in PESQ and STOI metrics but also boasts a leaner computational footprint with reduced parameters.
A Novel Semi-supervised Meta Learning Method for Subject-transfer Brain-computer Interface
Sep 07, 2022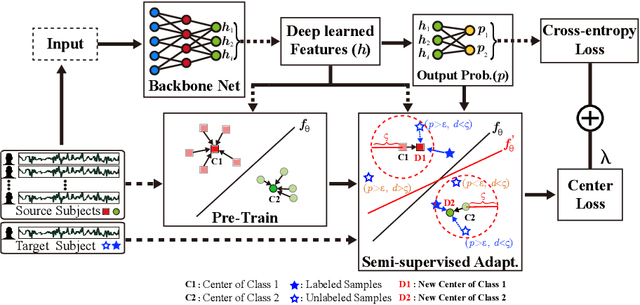
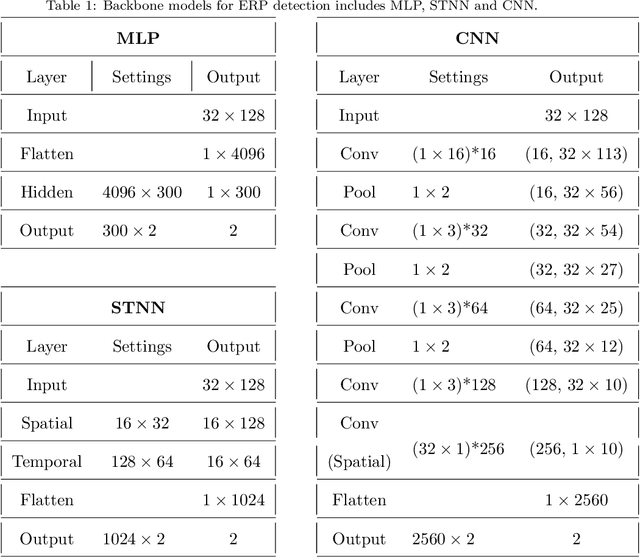
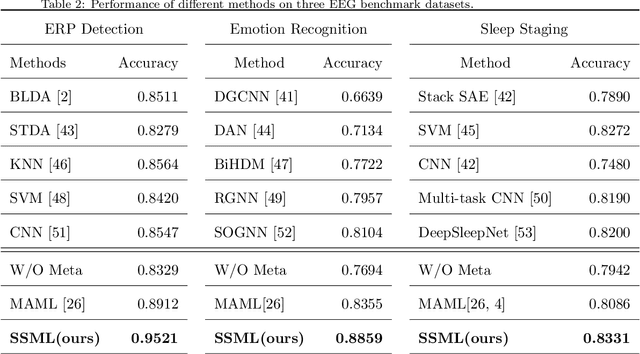
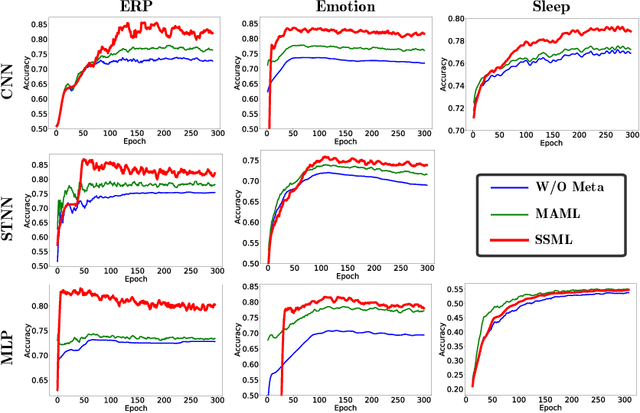
Brain-computer interface (BCI) provides a direct communication pathway between human brain and external devices. Before a new subject could use BCI, a calibration procedure is usually required. Because the inter- and intra-subject variances are so large that the models trained by the existing subjects perform poorly on new subjects. Therefore, effective subject-transfer and calibration method is essential. In this paper, we propose a semi-supervised meta learning (SSML) method for subject-transfer learning in BCIs. The proposed SSML learns a meta model with the existing subjects first, then fine-tunes the model in a semi-supervised learning manner, i.e. using few labeled and many unlabeled samples of target subject for calibration. It is significant for BCI applications where the labeled data are scarce or expensive while unlabeled data are readily available. To verify the SSML method, three different BCI paradigms are tested: 1) event-related potential detection; 2) emotion recognition; and 3) sleep staging. The SSML achieved significant improvements of over 15% on the first two paradigms and 4.9% on the third. The experimental results demonstrated the effectiveness and potential of the SSML method in BCI applications.