 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARiSE: Auto-Regressive Multi-Channel Speech Enhancement
May 28, 2025We propose ARiSE, an auto-regressive algorithm for multi-channel speech enhancement. ARiSE improves existing deep neural network (DNN) based frame-online multi-channel speech enhancement models by introducing auto-regressive connections, where the estimated target speech at previous frames is leveraged as extra input features to help the DNN estimate the target speech at the current frame. The extra input features can be derived from (a) the estimated target speech in previous frames; and (b) a beamformed mixture with the beamformer computed based on the previous estimated target speech. On the other hand, naively training the DNN in an auto-regressive manner is very slow. To deal with this, we propose a parallel training mechanism to speed up the training. Evaluation results in noisy-reverberant conditions show the effectiveness and potential of the proposed algorithms.
Listen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025



We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.
Efficient Multi-Channel Speech Enhancement with Spherical Harmonics Injection for Directional Encoding
Sep 19, 2023

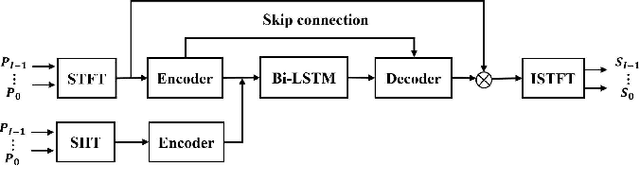

Multi-channel speech enhancement extracts speech using multiple microphones that capture spatial cues. Effectively utilizing directional information is key for multi-channel enhancement. Deep learning shows great potential on multi-channel speech enhancement and often takes short-time Fourier Transform (STFT) as inputs directly. To fully leverage the spatial information, we introduce a method using spherical harmonics transform (SHT) coefficients as auxiliary model inputs. These coefficients concisely represent spatial distributions. Specifically, our model has two encoders, one for the STFT and another for the SHT. By fusing both encoders in the decoder to estimate the enhanced STFT, we effectively incorporate spatial context. Evaluations on TIMIT under varying noise and reverberation show our model outperforms established benchmarks. Remarkably, this is achieved with fewer computations and parameters. By leveraging spherical harmonics to incorporate directional cues, our model efficiently improves the performance of the multi-channel speech enhancement.
ExARN: self-attending RNN for target speaker extraction
Dec 02, 2022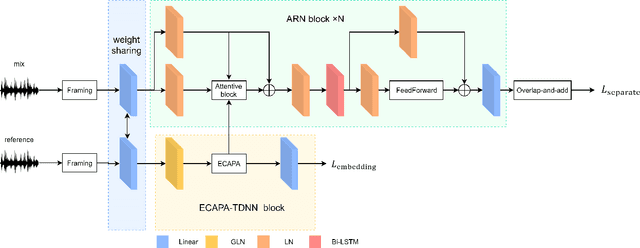
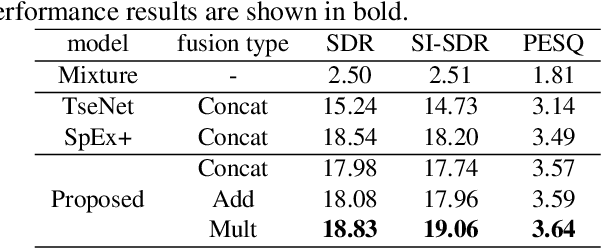
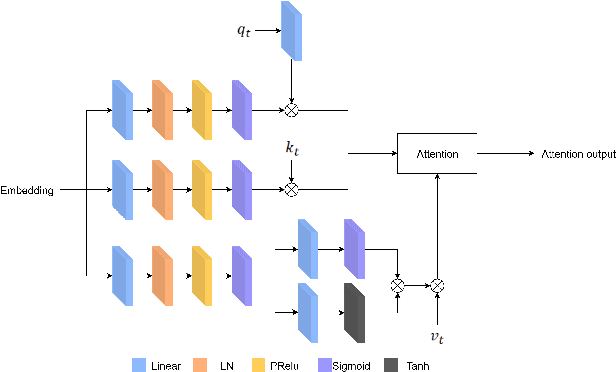
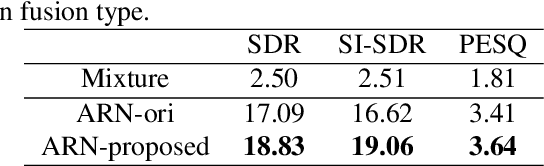
Target speaker extraction is to extract the target speaker, specified by enrollment utterance, in an environment with other competing speakers. Therefore, the task needs to solve two problems, speaker identification and separation, at the same time. In this paper, we combine self-attention and Recurrent Neural Networks (RNN). Further, we exploit various ways to combining different auxiliary information with mixed representations. Experimental results show that our proposed model achieves excellent performance on the task of target speaker extraction.