 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025



We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.
Self-Comparison for Dataset-Level Membership Inference in Large (Vision-)Language Models
Oct 16, 2024



Large Language Models (LLMs) and Vision-Language Models (VLMs) have made significant advancements in a wide range of natural language processing and vision-language tasks. Access to large web-scale datasets has been a key factor in their success. However, concerns have been raised about the unauthorized use of copyrighted materials and potential copyright infringement. Existing methods, such as sample-level Membership Inference Attacks (MIA) and distribution-based dataset inference, distinguish member data (data used for training) and non-member data by leveraging the common observation that models tend to memorize and show greater confidence in member data. Nevertheless, these methods face challenges when applied to LLMs and VLMs, such as the requirement for ground-truth member data or non-member data that shares the same distribution as the test data. In this paper, we propose a novel dataset-level membership inference method based on Self-Comparison. We find that a member prefix followed by a non-member suffix (paraphrased from a member suffix) can further trigger the model's memorization on training data. Instead of directly comparing member and non-member data, we introduce paraphrasing to the second half of the sequence and evaluate how the likelihood changes before and after paraphrasing. Unlike prior approaches, our method does not require access to ground-truth member data or non-member data in identical distribution, making it more practical. Extensive experiments demonstrate that our proposed method outperforms traditional MIA and dataset inference techniques across various datasets and models, including including public models, fine-tuned models, and API-based commercial models.
Six-CD: Benchmarking Concept Removals for Benign Text-to-image Diffusion Models
Jun 21, 2024
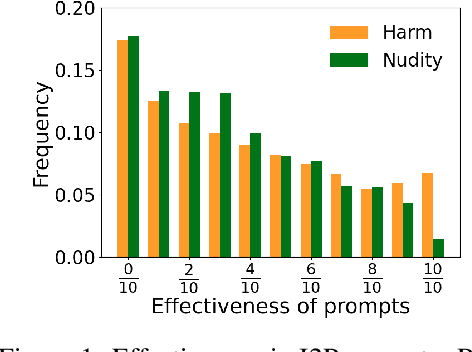
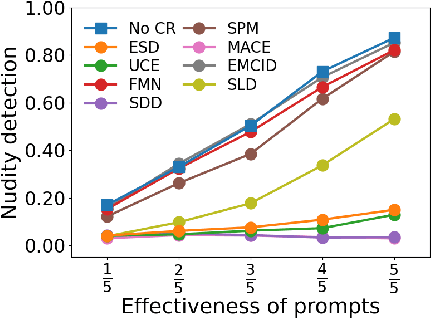

Text-to-image (T2I) diffusion models have shown exceptional capabilities in generating images that closely correspond to textual prompts. However, the advancement of T2I diffusion models presents significant risks, as the models could be exploited for malicious purposes, such as generating images with violence or nudity, or creating unauthorized portraits of public figures in inappropriate contexts. To mitigate these risks, concept removal methods have been proposed. These methods aim to modify diffusion models to prevent the generation of malicious and unwanted concepts. Despite these efforts, existing research faces several challenges: (1) a lack of consistent comparisons on a comprehensive dataset, (2) ineffective prompts in harmful and nudity concepts, (3) overlooked evaluation of the ability to generate the benign part within prompts containing malicious concepts. To address these gaps, we propose to benchmark the concept removal methods by introducing a new dataset, Six-CD, along with a novel evaluation metric. In this benchmark, we conduct a thorough evaluation of concept removals, with the experimental observations and discussions offering valuable insights in the field.