 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Adapting to Evolving Adversaries with Regularized Continual Robust Training
Feb 06, 2025



Robust training methods typically defend against specific attack types, such as Lp attacks with fixed budgets, and rarely account for the fact that defenders may encounter new attacks over time. A natural solution is to adapt the defended model to new adversaries as they arise via fine-tuning, a method which we call continual robust training (CRT). However, when implemented naively, fine-tuning on new attacks degrades robustness on previous attacks. This raises the question: how can we improve the initial training and fine-tuning of the model to simultaneously achieve robustness against previous and new attacks? We present theoretical results which show that the gap in a model's robustness against different attacks is bounded by how far each attack perturbs a sample in the model's logit space, suggesting that regularizing with respect to this logit space distance can help maintain robustness against previous attacks. Extensive experiments on 3 datasets (CIFAR-10, CIFAR-100, and ImageNette) and over 100 attack combinations demonstrate that the proposed regularization improves robust accuracy with little overhead in training time. Our findings and open-source code lay the groundwork for the deployment of models robust to evolving attacks.
Masked Differential Privacy
Oct 22, 2024



Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding $\epsilon<1$ regime.
Self-Comparison for Dataset-Level Membership Inference in Large (Vision-)Language Models
Oct 16, 2024



Large Language Models (LLMs) and Vision-Language Models (VLMs) have made significant advancements in a wide range of natural language processing and vision-language tasks. Access to large web-scale datasets has been a key factor in their success. However, concerns have been raised about the unauthorized use of copyrighted materials and potential copyright infringement. Existing methods, such as sample-level Membership Inference Attacks (MIA) and distribution-based dataset inference, distinguish member data (data used for training) and non-member data by leveraging the common observation that models tend to memorize and show greater confidence in member data. Nevertheless, these methods face challenges when applied to LLMs and VLMs, such as the requirement for ground-truth member data or non-member data that shares the same distribution as the test data. In this paper, we propose a novel dataset-level membership inference method based on Self-Comparison. We find that a member prefix followed by a non-member suffix (paraphrased from a member suffix) can further trigger the model's memorization on training data. Instead of directly comparing member and non-member data, we introduce paraphrasing to the second half of the sequence and evaluate how the likelihood changes before and after paraphrasing. Unlike prior approaches, our method does not require access to ground-truth member data or non-member data in identical distribution, making it more practical. Extensive experiments demonstrate that our proposed method outperforms traditional MIA and dataset inference techniques across various datasets and models, including including public models, fine-tuned models, and API-based commercial models.
Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Jul 22, 2024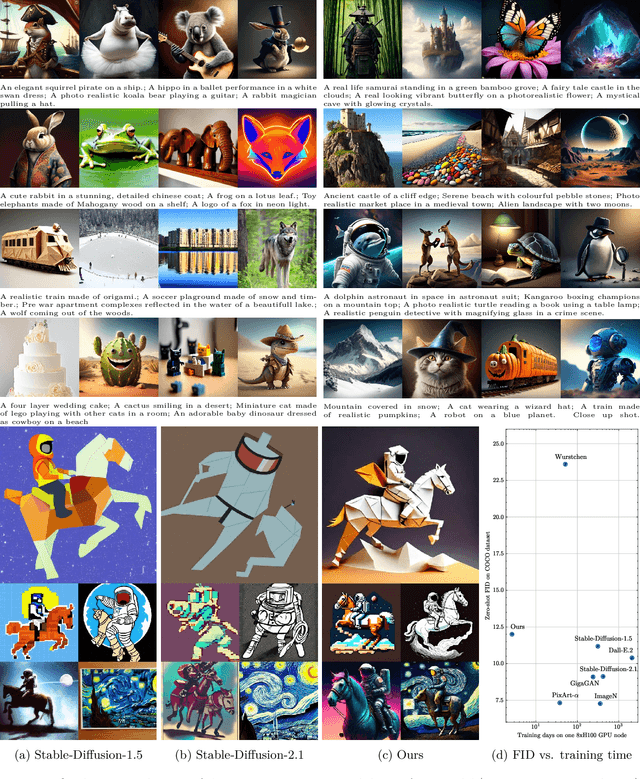
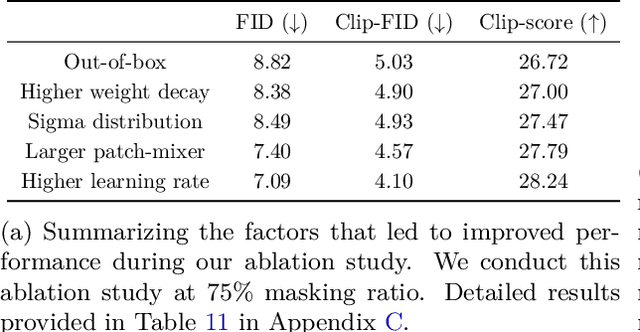
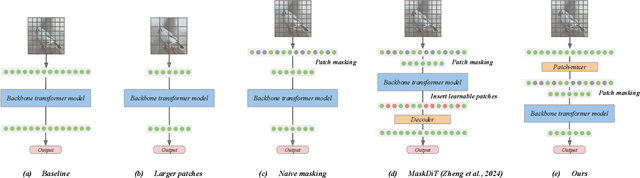

As scaling laws in generative AI push performance, they also simultaneously concentrate the development of these models among actors with large computational resources. With a focus on text-to-image (T2I) generative models, we aim to address this bottleneck by demonstrating very low-cost training of large-scale T2I diffusion transformer models. As the computational cost of transformers increases with the number of patches in each image, we propose to randomly mask up to 75% of the image patches during training. We propose a deferred masking strategy that preprocesses all patches using a patch-mixer before masking, thus significantly reducing the performance degradation with masking, making it superior to model downscaling in reducing computational cost. We also incorporate the latest improvements in transformer architecture, such as the use of mixture-of-experts layers, to improve performance and further identify the critical benefit of using synthetic images in micro-budget training. Finally, using only 37M publicly available real and synthetic images, we train a 1.16 billion parameter sparse transformer with only \$1,890 economical cost and achieve a 12.7 FID in zero-shot generation on the COCO dataset. Notably, our model achieves competitive FID and high-quality generations while incurring 118$\times$ lower cost than stable diffusion models and 14$\times$ lower cost than the current state-of-the-art approach that costs \$28,400. We aim to release our end-to-end training pipeline to further democratize the training of large-scale diffusion models on micro-budgets.
Evaluating and Mitigating IP Infringement in Visual Generative AI
Jun 07, 2024



The popularity of visual generative AI models like DALL-E 3, Stable Diffusion XL, Stable Video Diffusion, and Sora has been increasing. Through extensive evaluation, we discovered that the state-of-the-art visual generative models can generate content that bears a striking resemblance to characters protected by intellectual property rights held by major entertainment companies (such as Sony, Marvel, and Nintendo), which raises potential legal concerns. This happens when the input prompt contains the character's name or even just descriptive details about their characteristics. To mitigate such IP infringement problems, we also propose a defense method against it. In detail, we develop a revised generation paradigm that can identify potentially infringing generated content and prevent IP infringement by utilizing guidance techniques during the diffusion process. It has the capability to recognize generated content that may be infringing on intellectual property rights, and mitigate such infringement by employing guidance methods throughout the diffusion process without retrain or fine-tune the pretrained models. Experiments on well-known character IPs like Spider-Man, Iron Man, and Superman demonstrate the effectiveness of the proposed defense method. Our data and code can be found at https://github.com/ZhentingWang/GAI_IP_Infringement.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
How to Trace Latent Generative Model Generated Images without Artificial Watermark?
May 22, 2024Latent generative models (e.g., Stable Diffusion) have become more and more popular, but concerns have arisen regarding potential misuse related to images generated by these models. It is, therefore, necessary to analyze the origin of images by inferring if a particular image was generated by a specific latent generative model. Most existing methods (e.g., image watermark and model fingerprinting) require extra steps during training or generation. These requirements restrict their usage on the generated images without such extra operations, and the extra required operations might compromise the quality of the generated images. In this work, we ask whether it is possible to effectively and efficiently trace the images generated by a specific latent generative model without the aforementioned requirements. To study this problem, we design a latent inversion based method called LatentTracer to trace the generated images of the inspected model by checking if the examined images can be well-reconstructed with an inverted latent input. We leverage gradient based latent inversion and identify a encoder-based initialization critical to the success of our approach. Our experiments on the state-of-the-art latent generative models, such as Stable Diffusion, show that our method can distinguish the images generated by the inspected model and other images with a high accuracy and efficiency. Our findings suggest the intriguing possibility that today's latent generative generated images are naturally watermarked by the decoder used in the source models. Code: https://github.com/ZhentingWang/LatentTracer.
Finding needles in a haystack: A Black-Box Approach to Invisible Watermark Detection
Mar 30, 2024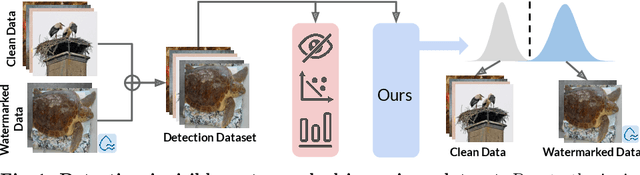


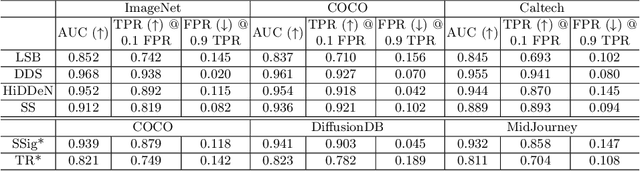
In this paper, we propose WaterMark Detection (WMD), the first invisible watermark detection method under a black-box and annotation-free setting. WMD is capable of detecting arbitrary watermarks within a given reference dataset using a clean non-watermarked dataset as a reference, without relying on specific decoding methods or prior knowledge of the watermarking techniques. We develop WMD using foundations of offset learning, where a clean non-watermarked dataset enables us to isolate the influence of only watermarked samples in the reference dataset. Our comprehensive evaluations demonstrate the effectiveness of WMD, significantly outperforming naive detection methods, which only yield AUC scores around 0.5. In contrast, WMD consistently achieves impressive detection AUC scores, surpassing 0.9 in most single-watermark datasets and exceeding 0.7 in more challenging multi-watermark scenarios across diverse datasets and watermarking methods. As invisible watermarks become increasingly prevalent, while specific decoding techniques remain undisclosed, our approach provides a versatile solution and establishes a path toward increasing accountability, transparency, and trust in our digital visual content.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024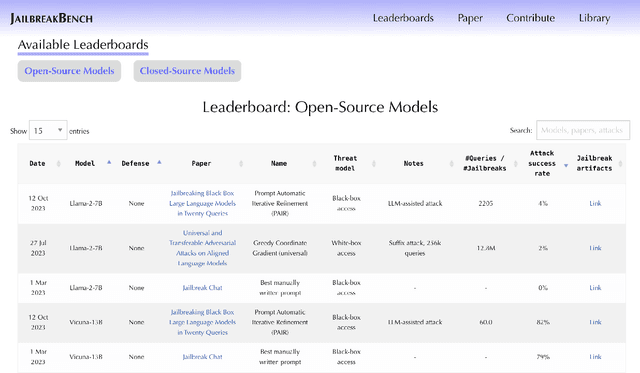


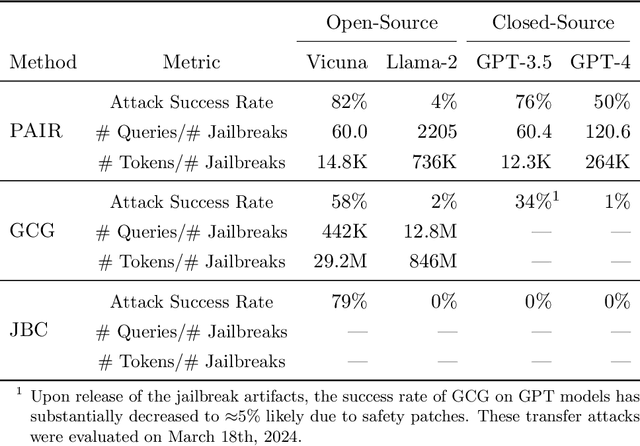
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.