 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the ID-OOD Tradeoff in Open-Set Test-Time Adaptation
Apr 02, 2026Open-set test-time adaptation (OSTTA) addresses the challenge of adapting models to new environments where out-of-distribution (OOD) samples coexist with in-distribution (ID) samples affected by distribution shifts. In such settings, covariate shift-for example, changes in weather conditions such as snow-can alter ID samples, reducing model reliability. Consequently, models must not only correctly classify covariate-shifted ID (csID) samples but also effectively reject covariate-shifted OOD (csOOD) samples. Entropy minimization is a common strategy in test-time adaptation to maintain ID performance under distribution shifts, while entropy maximization is widely applied to enhance OOD detection. Several studies have sought to combine these objectives to tackle the challenges of OSTTA. However, the intrinsic conflict between entropy minimization and maximization inevitably leads to a trade-off between csID classification and csOOD detection. In this paper, we first analyze the limitations of entropy maximization in OSTTA and then introduce an angular loss to regulate feature norm magnitudes, along with a feature-norm loss to suppress csOOD logits, thereby improving OOD detection. These objectives form ROSETTA, a $\underline{r}$obust $\underline{o}$pen-$\underline{se}$t $\underline{t}$est-$\underline{t}$ime $\underline{a}$daptation. Our method achieves strong OOD detection while maintaining high ID classification performance on CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and ImageNet-C. Furthermore, experiments on the Cityscapes validate the method's effectiveness in real-world semantic segmentation, and results on the HAC dataset demonstrate its applicability across different open-set TTA setups.
AirSimAG: A High-Fidelity Simulation Platform for Air-Ground Collaborative Robotics
Mar 24, 2026As spatial intelligence continues to evolve, heterogeneous multi-agent systems-particularly the collaboration between Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs), have demonstrated strong potential in complex applications such as search and rescue, urban surveillance, and environmental monitoring. However, existing simulation platforms are primarily designed for single-agent dynamics and lack dedicated frameworks for interactive air-ground collaborative simulation. In this paper, we present AirsimAG, a high-fidelity air-ground collaborative simulation platform built upon an extensively customized AirSim framework. The platform enables synchronized multi-agent simulation and supports heterogeneous sensing and control interfaces for UAV-UGV systems. To demonstrate its capabilities, we design a set of representative air-ground collaborative tasks, including mapping, planning, tracking, formation, and exploration. We further provide quantitative analyses based on these tasks to illustrate the platform effectiveness in supporting multi-agent coordination and cross-modal data consistency. The AirsimAG simulation platform is publicly available at https://github.com/BIULab-BUAA/AirSimAG.
Bridging the Know-Act Gap via Task-Level Autoregressive Reasoning
Mar 23, 2026LLMs often generate seemingly valid answers to flawed or ill-posed inputs. This is not due to missing knowledge: under discriminative prompting, the same models can mostly identify such issues, yet fail to reflect this in standard generative responses. This reveals a fundamental know-act gap between discriminative recognition and generative behavior. Prior work largely characterizes this issue in narrow settings, such as math word problems or question answering, with limited focus on how to integrate these two modes. In this work, we present a comprehensive analysis using FaultyScience, a newly constructed large-scale, cross-disciplinary benchmark of faulty scientific questions. We show that the gap is pervasive and stems from token-level autoregression, which entangles task selection (validate vs. answer) with content generation, preventing discriminative knowledge from being utilized. To address this, we propose DeIllusionLLM, a task-level autoregressive framework that explicitly models this decision. Through self-distillation, the model unifies discriminative judgment and generative reasoning within a single backbone. Empirically, DeIllusionLLM substantially reduces answer-despite-error failures under natural prompting while maintaining general reasoning performance, demonstrating that self-distillation is an effective and scalable solution for bridging the discriminative-generative know-act gap
MI-DPG: Decomposable Parameter Generation Network Based on Mutual Information for Multi-Scenario Recommendation
Mar 22, 2026Conversion rate (CVR) prediction models play a vital role in recommendation and advertising systems. Recent research on multi-scenario recommendation shows that learning a unified model to serve multiple scenarios is effective for improving overall performance. However, it remains challenging to improve model prediction performance across scenarios at low model parameter cost, and current solutions are hard to robustly model multi-scenario diversity. In this paper, we propose MI-DPG for the multi-scenario CVR prediction, which learns scenario-conditioned dynamic model parameters for each scenario in a more efficient and effective manner. Specifically, we introduce an auxiliary network to generate scenario-conditioned dynamic weighting matrices, which are obtained by combining decomposed scenario-specific and scenario-shared low-rank matrices with parameter efficiency. For each scene, weighting the backbone model parameters by the weighting matrix helps to specialize the model parameters for different scenarios. It can not only modulate the complete parameter space of the backbone model but also improve the model effectiveness. Furthermore, we design a mutual information regularization to enhance the diversity of model parameters across different scenarios by maximizing the mutual information between the scenario-aware input and the scene-conditioned dynamic weighting matrix. Experiments from three real-world datasets show that MI-DPG significantly outperforms previous multi-scenario recommendation models.
* Accepted by CIKM 2023
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning
Mar 02, 2026Large Vision-Language Models (LVLMs) often omit or misrepresent critical visual content in generated image captions. Minimizing such information loss will force LVLMs to focus on image details to generate precise descriptions. However, measuring information loss during modality conversion is inherently challenging due to the modal gap between visual content and text output. In this paper, we argue that the quality of an image caption is positively correlated with the similarity between images retrieved via text search using that caption. Based on this insight, we further propose Cross-modal Identity Mapping (CIM), a reinforcement learning framework that enhances image captioning without requiring additional annotations. Specifically, the method quantitatively evaluates the information loss from two perspectives: Gallery Representation Consistency and Query-gallery Image Relevance. Supervised under these metrics, LVLM minimizes information loss and aims to achieve identity mapping from images to captions. The experimental results demonstrate the superior performance of our method in image captioning, even when compared with Supervised Fine-Tuning. Particularly, on the COCO-LN500 benchmark, CIM achieves a 20% improvement in relation reasoning on Qwen2.5-VL-7B.The code will be released when the paper is accepted.
RA-Nav: A Risk-Aware Navigation System Based on Semantic Segmentation for Aerial Robots in Unpredictable Environments
Feb 19, 2026Existing aerial robot navigation systems typically plan paths around static and dynamic obstacles, but fail to adapt when a static obstacle suddenly moves. Integrating environmental semantic awareness enables estimation of potential risks posed by suddenly moving obstacles. In this paper, we propose RA- Nav, a risk-aware navigation framework based on semantic segmentation. A lightweight multi-scale semantic segmentation network identifies obstacle categories in real time. These obstacles are further classified into three types: stationary, temporarily static, and dynamic. For each type, corresponding risk estimation functions are designed to enable real-time risk prediction, based on which a complete local risk map is constructed. Based on this map, the risk-informed path search algorithm is designed to guarantee planning that balances path efficiency and safety. Trajectory optimization is then applied to generate trajectories that are safe, smooth, and dynamically feasible. Comparative simulations demonstrate that RA-Nav achieves higher success rates than baselines in sudden obstacle state transition scenarios. Its effectiveness is further validated in simulations using real- world data.
QuRL: Efficient Reinforcement Learning with Quantized Rollout
Feb 15, 2026Reinforcement learning with verifiable rewards (RLVR) has become a trending paradigm for training reasoning large language models (LLMs). However, due to the autoregressive decoding nature of LLMs, the rollout process becomes the efficiency bottleneck of RL training, consisting of up to 70\% of the total training time. In this work, we propose Quantized Reinforcement Learning (QuRL) that uses a quantized actor for accelerating the rollout. We address two challenges in QuRL. First, we propose Adaptive Clipping Range (ACR) that dynamically adjusts the clipping ratio based on the policy ratio between the full-precision actor and the quantized actor, which is essential for mitigating long-term training collapse. Second, we identify the weight update problem, where weight changes between RL steps are extremely small, making it difficult for the quantization operation to capture them effectively. We mitigate this problem through the invariant scaling technique that reduces quantization noise and increases weight update. We evaluate our method with INT8 and FP8 quantization experiments on DeepScaleR and DAPO, and achieve 20% to 80% faster rollout during training.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025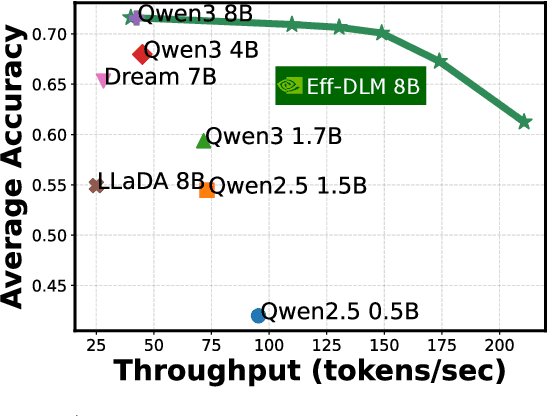
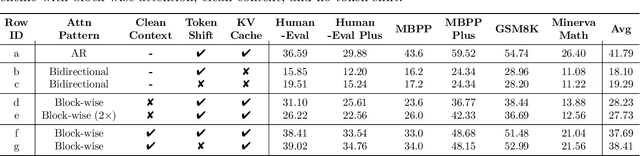
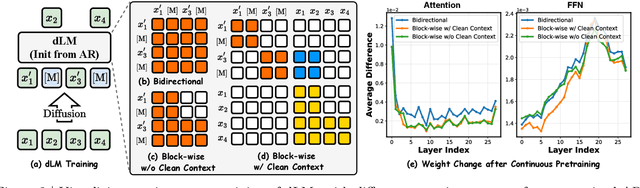
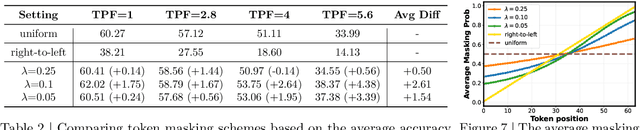
Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
Untethered thin dielectric elastomer actuated soft robot
Dec 12, 2025Thin dielectric elastomer actuator (DEA) features a unique in-plane configuration, enabling low-profile designs capable of accessing millimetre-scale narrow spaces. However, most existing DEA-powered soft robots require high voltages and wired power connections, limiting their ability to operate in confined environments. This study presents an untethered thin soft robot (UTS-Robot) powered by thin dielectric elastomer actuators (TS-DEA). The robot measures 38 mm in length, 6 mm in height, and weighs just 2.34 grams, integrating flexible onboard electronics to achieve fully untethered actuation. The TS-DEA, operating at resonant frequencies of 86 Hz under a low driving voltage of 220 V, adopts a dual-actuation sandwiched structure, comprising four dielectric elastomer layers bonded to a compressible tensioning mechanism at its core. This design enables high power density actuation and locomotion via three directional friction pads. The low-voltage actuation is achieved by fabricating each elastomer layer via spin coating to an initial thickness of 50 um, followed by biaxial stretching to 8 um. A comprehensive design and modelling framework has been developed to optimise TS-DEA performance. Experimental evaluations demonstrate that the bare TS-DEA achieves a locomotion speed of 12.36 mm/s at resonance, the untethered configuration achieves a locomotion speed of 0.5 mm/s, making it highly suitable for navigating confined and complex environments.
OEMA: Ontology-Enhanced Multi-Agent Collaboration Framework for Zero-Shot Clinical Named Entity Recognition
Nov 19, 2025Clinical named entity recognition (NER) is crucial for extracting information from electronic health records (EHRs), but supervised models like CRF and BioClinicalBERT require costly annotated data. While zero-shot NER with large language models (LLMs) reduces this dependency, it struggles with example selection granularity and integrating prompts with self-improvement. To address this, we propose OEMA, a zero-shot clinical NER framework using multi-agent collaboration. OEMA's three components are: a self-annotator generating examples, a discriminator filtering them via SNOMED CT, and a predictor using entity descriptions for accurate inference. On MTSamples and VAERS datasets, OEMA achieves state-of-the-art exact-match performance. Under related-match, it matches supervised BioClinicalBERT and surpasses CRF. OEMA addresses key zero-shot NER challenges through ontology-guided reasoning and multi-agent collaboration, achieving near-supervised performance and showing promise for clinical NLP applications.