 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSteer: Quantifying and Refining the Steerability of Multitask Robot Policies
Mar 18, 2026Despite strong multi-task pretraining, existing policies often exhibit poor task steerability. For example, a robot may fail to respond to a new instruction ``put the bowl in the sink" when moving towards the oven, executing ``close the oven", even though it can complete both tasks when executed separately. We propose ReSteer, a framework to quantify and improve task steerability in multitask robot policies. We conduct an exhaustive evaluation of state-of-the-art policies, revealing a common lack of steerability. We find that steerability is associated with limited overlap among training task trajectory distributions, and introduce a proxy metric to measure this overlap from policy behavior. Building on this insight, ReSteer improves steerability via three components: (i) a steerability estimator that identifies low-steerability states without full-rollout evaluation, (ii) a steerable data generator that synthesizes motion segments from these states, and (iii) a self-refinement pipeline that improves policy steerability using the generated data. In simulation on LIBERO, ReSteer improves steerability by 11\% over 18k rollouts. In real-world experiments, we show that improved steerability is critical for interactive use, enabling users to instruct robots to perform any task at any time. We hope this work motivates further study on quantifying steerability and data collection strategies for large robot policies.
EffGen: Enabling Small Language Models as Capable Autonomous Agents
Jan 31, 2026Most existing language model agentic systems today are built and optimized for large language models (e.g., GPT, Claude, Gemini) via API calls. While powerful, this approach faces several limitations including high token costs and privacy concerns for sensitive applications. We introduce effGen, an open-source agentic framework optimized for small language models (SLMs) that enables effective, efficient, and secure local deployment (pip install effgen). effGen makes four major contributions: (1) Enhanced tool-calling with prompt optimization that compresses contexts by 70-80% while preserving task semantics, (2) Intelligent task decomposition that breaks complex queries into parallel or sequential subtasks based on dependencies, (3) Complexity-based routing using five factors to make smart pre-execution decisions, and (4) Unified memory system combining short-term, long-term, and vector-based storage. Additionally, effGen unifies multiple agent protocols (MCP, A2A, ACP) for cross-protocol communication. Results on 13 benchmarks show effGen outperforms LangChain, AutoGen, and Smolagents with higher success rates, faster execution, and lower memory. Our results reveal that prompt optimization and complexity routing have complementary scaling behavior: optimization benefits SLMs more (11.2% gain at 1.5B vs 2.4% at 32B), while routing benefits large models more (3.6% at 1.5B vs 7.9% at 32B), providing consistent gains across all scales when combined. effGen (https://effgen.org/) is released under the MIT License, ensuring broad accessibility for research and commercial use. Our framework code is publicly available at https://github.com/ctrl-gaurav/effGen.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025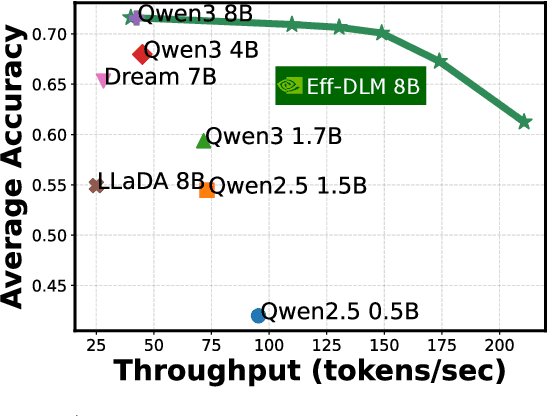
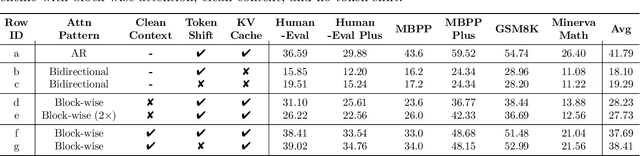
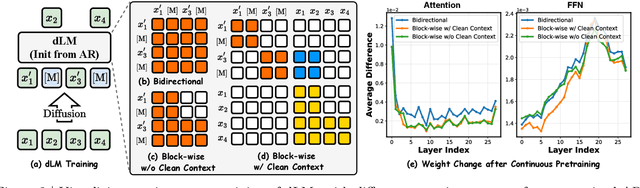
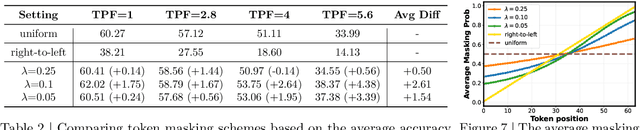
Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
FedHFT: Efficient Federated Finetuning with Heterogeneous Edge Clients
Oct 15, 2025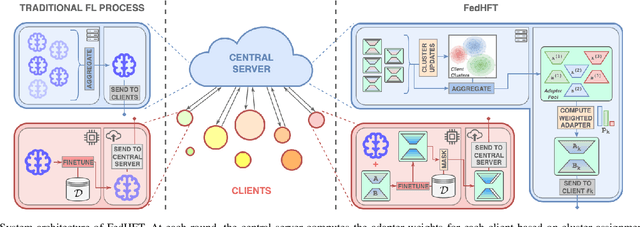
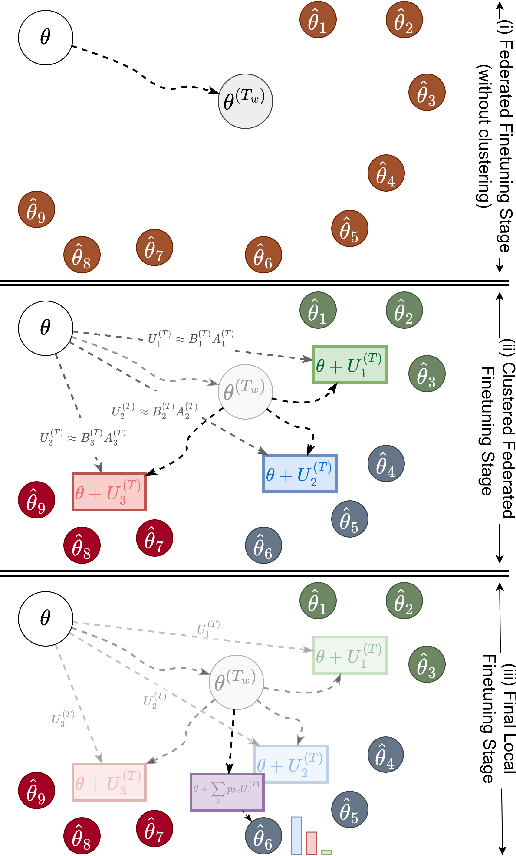
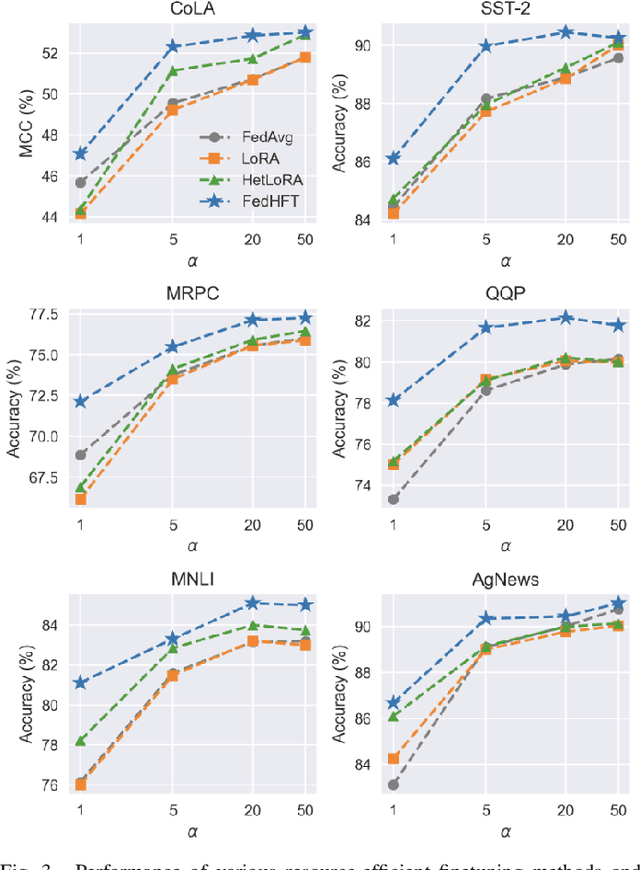
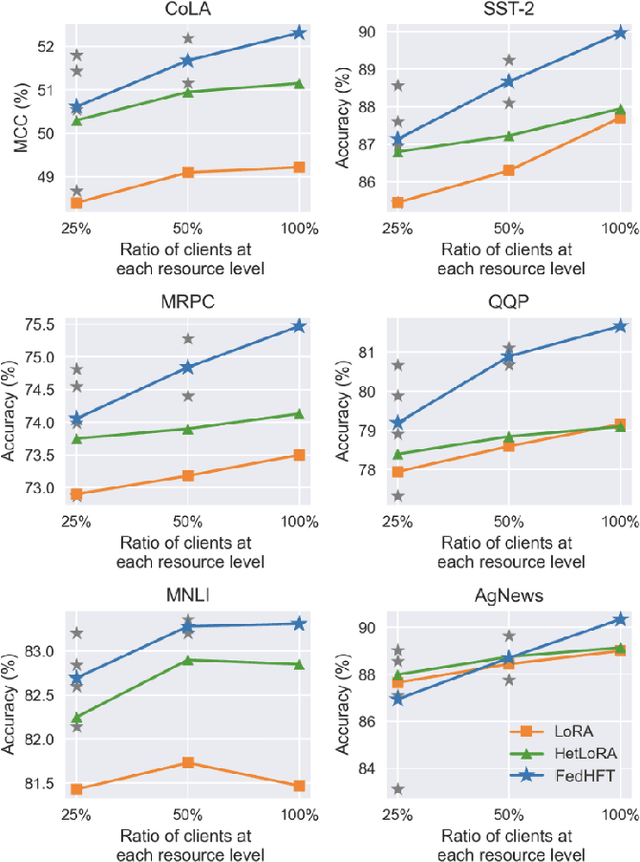
Fine-tuning pre-trained large language models (LLMs) has become a common practice for personalized natural language understanding (NLU) applications on downstream tasks and domain-specific datasets. However, there are two main challenges: (i) limited and/or heterogeneous data for fine-tuning due to proprietary data confidentiality or privacy requirements, and (ii) varying computation resources available across participating clients such as edge devices. This paper presents FedHFT - an efficient and personalized federated fine-tuning framework to address both challenges. First, we introduce a mixture of masked adapters to handle resource heterogeneity across participating clients, enabling high-performance collaborative fine-tuning of pre-trained language model(s) across multiple clients in a distributed setting, while keeping proprietary data local. Second, we introduce a bi-level optimization approach to handle non-iid data distribution based on masked personalization and client clustering. Extensive experiments demonstrate significant performance and efficiency improvements over various natural language understanding tasks under data and resource heterogeneity compared to representative heterogeneous federated learning methods.
LongMamba: Enhancing Mamba's Long Context Capabilities via Training-Free Receptive Field Enlargement
Apr 22, 2025State space models (SSMs) have emerged as an efficient alternative to Transformer models for language modeling, offering linear computational complexity and constant memory usage as context length increases. However, despite their efficiency in handling long contexts, recent studies have shown that SSMs, such as Mamba models, generally underperform compared to Transformers in long-context understanding tasks. To address this significant shortfall and achieve both efficient and accurate long-context understanding, we propose LongMamba, a training-free technique that significantly enhances the long-context capabilities of Mamba models. LongMamba builds on our discovery that the hidden channels in Mamba can be categorized into local and global channels based on their receptive field lengths, with global channels primarily responsible for long-context capability. These global channels can become the key bottleneck as the input context lengthens. Specifically, when input lengths largely exceed the training sequence length, global channels exhibit limitations in adaptively extend their receptive fields, leading to Mamba's poor long-context performance. The key idea of LongMamba is to mitigate the hidden state memory decay in these global channels by preventing the accumulation of unimportant tokens in their memory. This is achieved by first identifying critical tokens in the global channels and then applying token filtering to accumulate only those critical tokens. Through extensive benchmarking across synthetic and real-world long-context scenarios, LongMamba sets a new standard for Mamba's long-context performance, significantly extending its operational range without requiring additional training. Our code is available at https://github.com/GATECH-EIC/LongMamba.
Scaling Laws of Graph Neural Networks for Atomistic Materials Modeling
Apr 10, 2025Atomistic materials modeling is a critical task with wide-ranging applications, from drug discovery to materials science, where accurate predictions of the target material property can lead to significant advancements in scientific discovery. Graph Neural Networks (GNNs) represent the state-of-the-art approach for modeling atomistic material data thanks to their capacity to capture complex relational structures. While machine learning performance has historically improved with larger models and datasets, GNNs for atomistic materials modeling remain relatively small compared to large language models (LLMs), which leverage billions of parameters and terabyte-scale datasets to achieve remarkable performance in their respective domains. To address this gap, we explore the scaling limits of GNNs for atomistic materials modeling by developing a foundational model with billions of parameters, trained on extensive datasets in terabyte-scale. Our approach incorporates techniques from LLM libraries to efficiently manage large-scale data and models, enabling both effective training and deployment of these large-scale GNN models. This work addresses three fundamental questions in scaling GNNs: the potential for scaling GNN model architectures, the effect of dataset size on model accuracy, and the applicability of LLM-inspired techniques to GNN architectures. Specifically, the outcomes of this study include (1) insights into the scaling laws for GNNs, highlighting the relationship between model size, dataset volume, and accuracy, (2) a foundational GNN model optimized for atomistic materials modeling, and (3) a GNN codebase enhanced with advanced LLM-based training techniques. Our findings lay the groundwork for large-scale GNNs with billions of parameters and terabyte-scale datasets, establishing a scalable pathway for future advancements in atomistic materials modeling.
Uni-Render: A Unified Accelerator for Real-Time Rendering Across Diverse Neural Renderers
Mar 31, 2025Recent advancements in neural rendering technologies and their supporting devices have paved the way for immersive 3D experiences, significantly transforming human interaction with intelligent devices across diverse applications. However, achieving the desired real-time rendering speeds for immersive interactions is still hindered by (1) the lack of a universal algorithmic solution for different application scenarios and (2) the dedication of existing devices or accelerators to merely specific rendering pipelines. To overcome this challenge, we have developed a unified neural rendering accelerator that caters to a wide array of typical neural rendering pipelines, enabling real-time and on-device rendering across different applications while maintaining both efficiency and compatibility. Our accelerator design is based on the insight that, although neural rendering pipelines vary and their algorithm designs are continually evolving, they typically share common operators, predominantly executing similar workloads. Building on this insight, we propose a reconfigurable hardware architecture that can dynamically adjust dataflow to align with specific rendering metric requirements for diverse applications, effectively supporting both typical and the latest hybrid rendering pipelines. Benchmarking experiments and ablation studies on both synthetic and real-world scenes demonstrate the effectiveness of the proposed accelerator. The proposed unified accelerator stands out as the first solution capable of achieving real-time neural rendering across varied representative pipelines on edge devices, potentially paving the way for the next generation of neural graphics applications.
GauRast: Enhancing GPU Triangle Rasterizers to Accelerate 3D Gaussian Splatting
Mar 20, 20253D intelligence leverages rich 3D features and stands as a promising frontier in AI, with 3D rendering fundamental to many downstream applications. 3D Gaussian Splatting (3DGS), an emerging high-quality 3D rendering method, requires significant computation, making real-time execution on existing GPU-equipped edge devices infeasible. Previous efforts to accelerate 3DGS rely on dedicated accelerators that require substantial integration overhead and hardware costs. This work proposes an acceleration strategy that leverages the similarities between the 3DGS pipeline and the highly optimized conventional graphics pipeline in modern GPUs. Instead of developing a dedicated accelerator, we enhance existing GPU rasterizer hardware to efficiently support 3DGS operations. Our results demonstrate a 23$\times$ increase in processing speed and a 24$\times$ reduction in energy consumption, with improvements yielding 6$\times$ faster end-to-end runtime for the original 3DGS algorithm and 4$\times$ for the latest efficiency-improved pipeline, achieving 24 FPS and 46 FPS respectively. These enhancements incur only a minimal area overhead of 0.2\% relative to the entire SoC chip area, underscoring the practicality and efficiency of our approach for enabling 3DGS rendering on resource-constrained platforms.
MixGCN: Scalable GCN Training by Mixture of Parallelism and Mixture of Accelerators
Jan 06, 2025



Graph convolutional networks (GCNs) have demonstrated superiority in graph-based learning tasks. However, training GCNs on full graphs is particularly challenging, due to the following two challenges: (1) the associated feature tensors can easily explode the memory and block the communication bandwidth of modern accelerators, and (2) the computation workflow in training GCNs alternates between sparse and dense matrix operations, complicating the efficient utilization of computational resources. Existing solutions for scalable distributed full-graph GCN training mostly adopt partition parallelism, which is unsatisfactory as they only partially address the first challenge while incurring scaled-out communication volume. To this end, we propose MixGCN aiming to simultaneously address both the aforementioned challenges towards GCN training. To tackle the first challenge, MixGCN integrates mixture of parallelism. Both theoretical and empirical analysis verify its constant communication volumes and enhanced balanced workload; For handling the second challenge, we consider mixture of accelerators (i.e., sparse and dense accelerators) with a dedicated accelerator for GCN training and a fine-grain pipeline. Extensive experiments show that MixGCN achieves boosted training efficiency and scalability.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024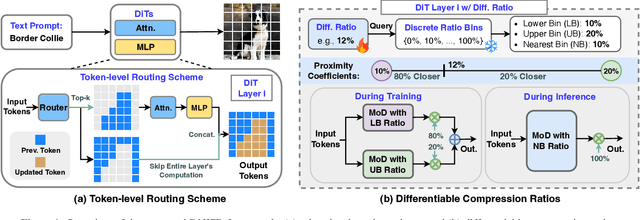



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.