 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifeSide: Benchmarking Agents as Lifelong Digital Companions
Jun 03, 2026Lifelong digital companions must integrate cross-session cues, continually update their understanding of users, and adapt to shifting privacy boundaries. Existing evaluations fail to capture this, testing memory recall and short-term empathy in isolation. To bridge this gap, we introduce \benchmark, a benchmark centered on multi-session \textit{Memory-Emotion-Environment} loops. By modeling users as persistent worlds with layered profiles and event trajectories, \benchmark uses multi-agent simulation to project environmental dynamics into dialogue, preserving the critical gap between latent thoughts and observable expressions. Evaluating 2,000 personas and 111K tasks across memory tracking, user understanding, privacy control, and emotional companionship, our experiment results reveal a stark reality: even models that saturate current memory benchmarks fail to sustain accurate user understanding and true companionship over long horizons.
Controllable Value Alignment in Large Language Models through Neuron-Level Editing
Feb 07, 2026Aligning large language models (LLMs) with human values has become increasingly important as their influence on human behavior and decision-making expands. However, existing steering-based alignment methods suffer from limited controllability: steering a target value often unintentionally activates other, non-target values. To characterize this limitation, we introduce value leakage, a diagnostic notion that captures the unintended activation of non-target values during value steering, along with a normalized leakage metric grounded in Schwartz's value theory. In light of this analysis, we propose NeVA, a neuron-level editing framework for controllable value alignment in LLMs. NeVA identifies sparse, value-relevant neurons and performs inference-time activation editing, enabling fine-grained control without parameter updates or retraining. Experiments show that NeVA achieves stronger target value alignment while incurring smaller performance degradation on general capability. Moreover, NeVA significantly reduces the average leakage, with residual effects largely confined to semantically related value classes. Overall, NeVA offers a more controllable and interpretable mechanism for value alignment.
Hi-Reco: High-Fidelity Real-Time Conversational Digital Humans
Nov 16, 2025High-fidelity digital humans are increasingly used in interactive applications, yet achieving both visual realism and real-time responsiveness remains a major challenge. We present a high-fidelity, real-time conversational digital human system that seamlessly combines a visually realistic 3D avatar, persona-driven expressive speech synthesis, and knowledge-grounded dialogue generation. To support natural and timely interaction, we introduce an asynchronous execution pipeline that coordinates multi-modal components with minimal latency. The system supports advanced features such as wake word detection, emotionally expressive prosody, and highly accurate, context-aware response generation. It leverages novel retrieval-augmented methods, including history augmentation to maintain conversational flow and intent-based routing for efficient knowledge access. Together, these components form an integrated system that enables responsive and believable digital humans, suitable for immersive applications in communication, education, and entertainment.
LSFDNet: A Single-Stage Fusion and Detection Network for Ships Using SWIR and LWIR
Jul 28, 2025
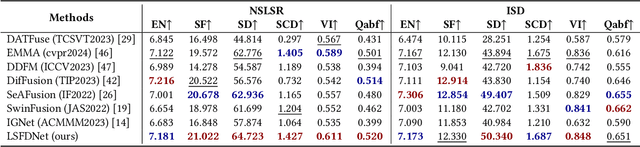

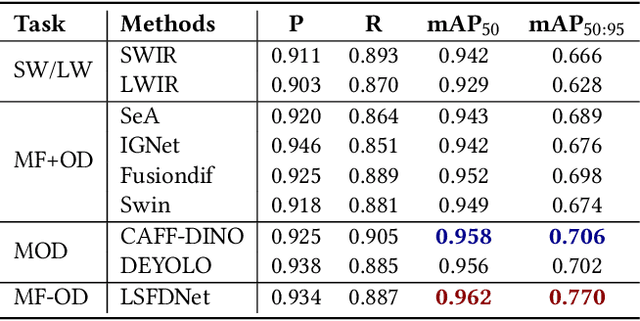
Traditional ship detection methods primarily rely on single-modal approaches, such as visible or infrared images, which limit their application in complex scenarios involving varying lighting conditions and heavy fog. To address this issue, we explore the advantages of short-wave infrared (SWIR) and long-wave infrared (LWIR) in ship detection and propose a novel single-stage image fusion detection algorithm called LSFDNet. This algorithm leverages feature interaction between the image fusion and object detection subtask networks, achieving remarkable detection performance and generating visually impressive fused images. To further improve the saliency of objects in the fused images and improve the performance of the downstream detection task, we introduce the Multi-Level Cross-Fusion (MLCF) module. This module combines object-sensitive fused features from the detection task and aggregates features across multiple modalities, scales, and tasks to obtain more semantically rich fused features. Moreover, we utilize the position prior from the detection task in the Object Enhancement (OE) loss function, further increasing the retention of object semantics in the fused images. The detection task also utilizes preliminary fused features from the fusion task to complement SWIR and LWIR features, thereby enhancing detection performance. Additionally, we have established a Nearshore Ship Long-Short Wave Registration (NSLSR) dataset to train effective SWIR and LWIR image fusion and detection networks, bridging a gap in this field. We validated the superiority of our proposed single-stage fusion detection algorithm on two datasets. The source code and dataset are available at https://github.com/Yanyin-Guo/LSFDNet
HDiffTG: A Lightweight Hybrid Diffusion-Transformer-GCN Architecture for 3D Human Pose Estimation
May 07, 2025We propose HDiffTG, a novel 3D Human Pose Estimation (3DHPE) method that integrates Transformer, Graph Convolutional Network (GCN), and diffusion model into a unified framework. HDiffTG leverages the strengths of these techniques to significantly improve pose estimation accuracy and robustness while maintaining a lightweight design. The Transformer captures global spatiotemporal dependencies, the GCN models local skeletal structures, and the diffusion model provides step-by-step optimization for fine-tuning, achieving a complementary balance between global and local features. This integration enhances the model's ability to handle pose estimation under occlusions and in complex scenarios. Furthermore, we introduce lightweight optimizations to the integrated model and refine the objective function design to reduce computational overhead without compromising performance. Evaluation results on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HDiffTG achieves state-of-the-art (SOTA) performance on the MPI-INF-3DHP dataset while excelling in both accuracy and computational efficiency. Additionally, the model exhibits exceptional robustness in noisy and occluded environments. Source codes and models are available at https://github.com/CirceJie/HDiffTG
TS-Diff: Two-Stage Diffusion Model for Low-Light RAW Image Enhancement
May 07, 2025This paper presents a novel Two-Stage Diffusion Model (TS-Diff) for enhancing extremely low-light RAW images. In the pre-training stage, TS-Diff synthesizes noisy images by constructing multiple virtual cameras based on a noise space. Camera Feature Integration (CFI) modules are then designed to enable the model to learn generalizable features across diverse virtual cameras. During the aligning stage, CFIs are averaged to create a target-specific CFI$^T$, which is fine-tuned using a small amount of real RAW data to adapt to the noise characteristics of specific cameras. A structural reparameterization technique further simplifies CFI$^T$ for efficient deployment. To address color shifts during the diffusion process, a color corrector is introduced to ensure color consistency by dynamically adjusting global color distributions. Additionally, a novel dataset, QID, is constructed, featuring quantifiable illumination levels and a wide dynamic range, providing a comprehensive benchmark for training and evaluation under extreme low-light conditions. Experimental results demonstrate that TS-Diff achieves state-of-the-art performance on multiple datasets, including QID, SID, and ELD, excelling in denoising, generalization, and color consistency across various cameras and illumination levels. These findings highlight the robustness and versatility of TS-Diff, making it a practical solution for low-light imaging applications. Source codes and models are available at https://github.com/CircccleK/TS-Diff
AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment
Nov 15, 2024Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.
SCPNet: Unsupervised Cross-modal Homography Estimation via Intra-modal Self-supervised Learning
Jul 11, 2024



We propose a novel unsupervised cross-modal homography estimation framework based on intra-modal Self-supervised learning, Correlation, and consistent feature map Projection, namely SCPNet. The concept of intra-modal self-supervised learning is first presented to facilitate the unsupervised cross-modal homography estimation. The correlation-based homography estimation network and the consistent feature map projection are combined to form the learnable architecture of SCPNet, boosting the unsupervised learning framework. SCPNet is the first to achieve effective unsupervised homography estimation on the satellite-map image pair cross-modal dataset, GoogleMap, under [-32,+32] offset on a 128x128 image, leading the supervised approach MHN by 14.0% of mean average corner error (MACE). We further conduct extensive experiments on several cross-modal/spectral and manually-made inconsistent datasets, on which SCPNet achieves the state-of-the-art (SOTA) performance among unsupervised approaches, and owns 49.0%, 25.2%, 36.4%, and 10.7% lower MACEs than the supervised approach MHN. Source code is available at https://github.com/RM-Zhang/SCPNet.
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024



Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
BVMatch: Lidar-based Place Recognition Using Bird's-eye View Images
Sep 01, 2021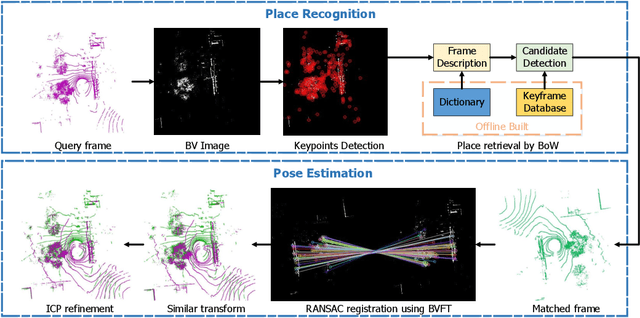

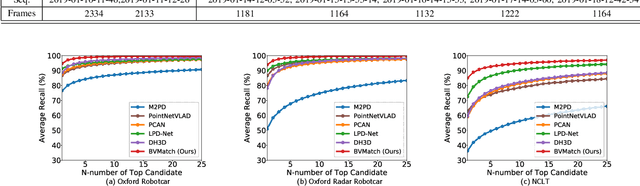
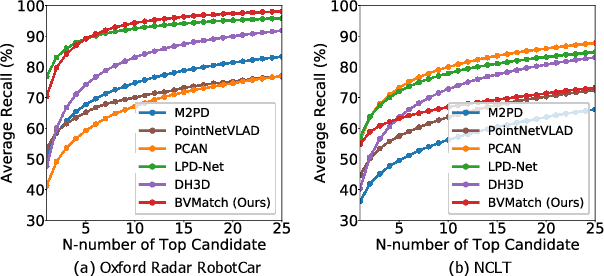
Recognizing places using Lidar in large-scale environments is challenging due to the sparse nature of point cloud data. In this paper we present BVMatch, a Lidar-based frame-to-frame place recognition framework, that is capable of estimating 2D relative poses. Based on the assumption that the ground area can be approximated as a plane, we uniformly discretize the ground area into grids and project 3D Lidar scans to bird's-eye view (BV) images. We further use a bank of Log-Gabor filters to build a maximum index map (MIM) that encodes the orientation information of the structures in the images. We analyze the orientation characteristics of MIM theoretically and introduce a novel descriptor called bird's-eye view feature transform (BVFT). The proposed BVFT is insensitive to rotation and intensity variations of BV images. Leveraging the BVFT descriptors, we unify the Lidar place recognition and pose estimation tasks into the BVMatch framework. The experiments conducted on three large-scale datasets show that BVMatch outperforms the state-of-the-art methods in terms of both recall rate of place recognition and pose estimation accuracy.