 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Group Sampling Based Online Action Recognition Using Kinetic Skeleton Features
Paper and Code
Nov 03, 2020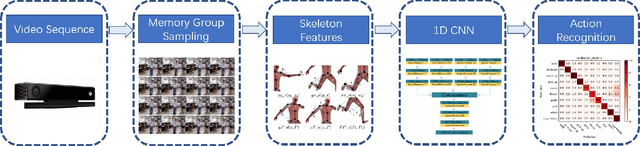
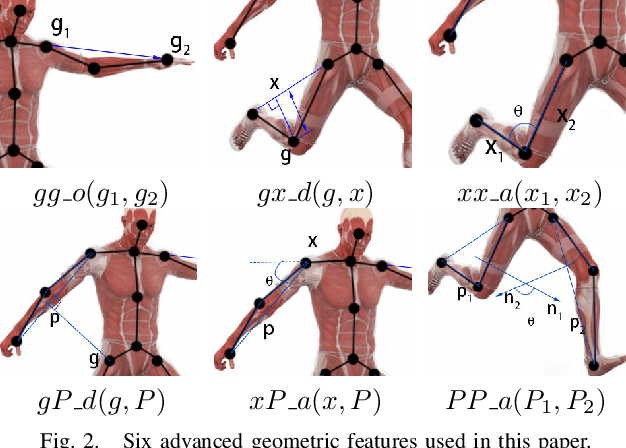
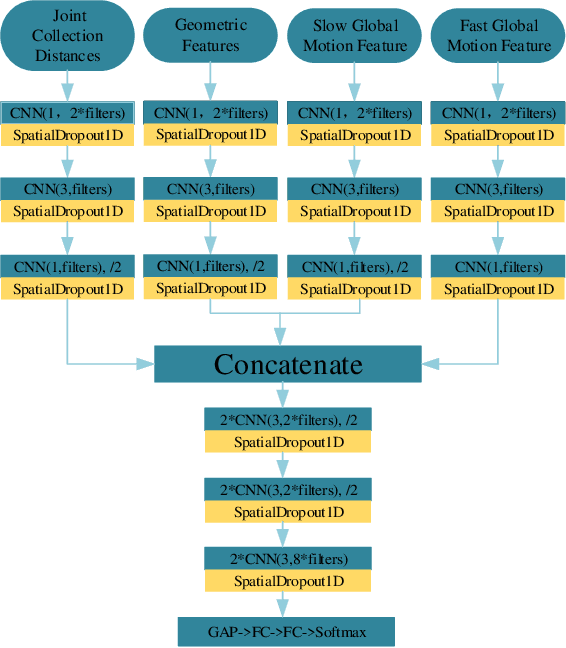
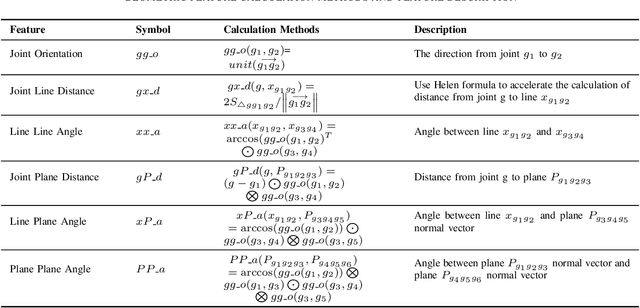
Online action recognition is an important task for human centered intelligent services, which is still difficult to achieve due to the varieties and uncertainties of spatial and temporal scales of human actions. In this paper, we propose two core ideas to handle the online action recognition problem. First, we combine the spatial and temporal skeleton features to depict the actions, which include not only the geometrical features, but also multi-scale motion features, such that both the spatial and temporal information of the action are covered. Second, we propose a memory group sampling method to combine the previous action frames and current action frames, which is based on the truth that the neighbouring frames are largely redundant, and the sampling mechanism ensures that the long-term contextual information is also considered. Finally, an improved 1D CNN network is employed for training and testing using the features from sampled frames. The comparison results to the state of the art methods using the public datasets show that the proposed method is fast and efficient, and has competitive performance