 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusTrack: One-Stage Focus-and-Suppress Framework for 3D Point Cloud Object Tracking
Feb 27, 2026In 3D point cloud object tracking, the motion-centric methods have emerged as a promising avenue due to its superior performance in modeling inter-frame motion. However, existing two-stage motion-based approaches suffer from fundamental limitations: (1) error accumulation due to decoupled optimization caused by explicit foreground segmentation prior to motion estimation, and (2) computational bottlenecks from sequential processing. To address these challenges, we propose FocusTrack, a novel one-stage paradigms tracking framework that unifies motion-semantics co-modeling through two core innovations: Inter-frame Motion Modeling (IMM) and Focus-and-Suppress Attention. The IMM module employs a temp-oral-difference siamese encoder to capture global motion patterns between adjacent frames. The Focus-and-Suppress attention that enhance the foreground semantics via motion-salient feature gating and suppress the background noise based on the temporal-aware motion context from IMM without explicit segmentation. Based on above two designs, FocusTrack enables end-to-end training with compact one-stage pipeline. Extensive experiments on prominent 3D tracking benchmarks, such as KITTI, nuScenes, and Waymo, demonstrate that the FocusTrack achieves new SOTA performance while running at a high speed with 105 FPS.
CompTrack: Information Bottleneck-Guided Low-Rank Dynamic Token Compression for Point Cloud Tracking
Nov 19, 20253D single object tracking (SOT) in LiDAR point clouds is a critical task in computer vision and autonomous driving. Despite great success having been achieved, the inherent sparsity of point clouds introduces a dual-redundancy challenge that limits existing trackers: (1) vast spatial redundancy from background noise impairs accuracy, and (2) informational redundancy within the foreground hinders efficiency. To tackle these issues, we propose CompTrack, a novel end-to-end framework that systematically eliminates both forms of redundancy in point clouds. First, CompTrack incorporates a Spatial Foreground Predictor (SFP) module to filter out irrelevant background noise based on information entropy, addressing spatial redundancy. Subsequently, its core is an Information Bottleneck-guided Dynamic Token Compression (IB-DTC) module that eliminates the informational redundancy within the foreground. Theoretically grounded in low-rank approximation, this module leverages an online SVD analysis to adaptively compress the redundant foreground into a compact and highly informative set of proxy tokens. Extensive experiments on KITTI, nuScenes and Waymo datasets demonstrate that CompTrack achieves top-performing tracking performance with superior efficiency, running at a real-time 90 FPS on a single RTX 3090 GPU.
Multi-object Tracking by Detection and Query: an efficient end-to-end manner
Nov 09, 2024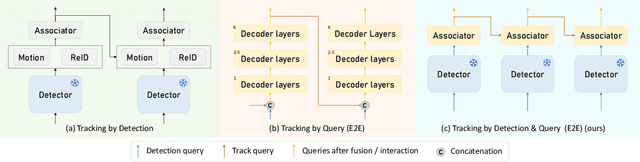
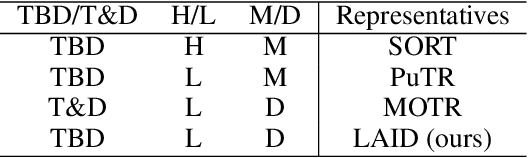
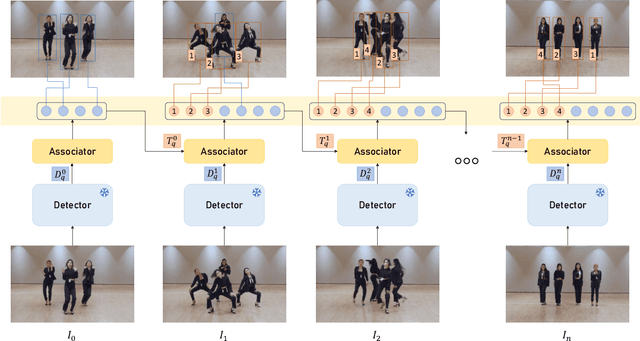
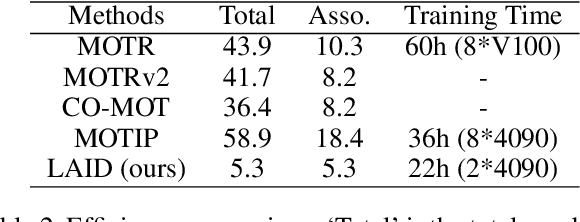
Multi-object tracking is advancing through two dominant paradigms: traditional tracking by detection and newly emerging tracking by query. In this work, we fuse them together and propose the tracking-by-detection-and-query paradigm, which is achieved by a Learnable Associator. Specifically, the basic information interaction module and the content-position alignment module are proposed for thorough information Interaction among object queries. Tracking results are directly Decoded from these queries. Hence, we name the method as LAID. Compared to tracking-by-query models, LAID achieves competitive tracking accuracy with notably higher training efficiency. With regard to tracking-by-detection methods, experimental results on DanceTrack show that LAID significantly surpasses the state-of-the-art heuristic method by 3.9% on HOTA metric and 6.1% on IDF1 metric. On SportsMOT, LAID also achieves the best score on HOTA metric. By holding low training cost, strong tracking capabilities, and an elegant end-to-end approach all at once, LAID presents a forward-looking direction for the field.
Training-free Long Video Generation with Chain of Diffusion Model Experts
Aug 27, 2024Video generation models hold substantial potential in areas such as filmmaking. However, current video diffusion models need high computational costs and produce suboptimal results due to high complexity of video generation task. In this paper, we propose \textbf{ConFiner}, an efficient high-quality video generation framework that decouples video generation into easier subtasks: structure \textbf{con}trol and spatial-temporal re\textbf{fine}ment. It can generate high-quality videos with chain of off-the-shelf diffusion model experts, each expert responsible for a decoupled subtask. During the refinement, we introduce coordinated denoising, which can merge multiple diffusion experts' capabilities into a single sampling. Furthermore, we design ConFiner-Long framework, which can generate long coherent video with three constraint strategies on ConFiner. Experimental results indicate that with only 10\% of the inference cost, our ConFiner surpasses representative models like Lavie and Modelscope across all objective and subjective metrics. And ConFiner-Long can generate high-quality and coherent videos with up to 600 frames.
MAMCA -- Optimal on Accuracy and Efficiency for Automatic Modulation Classification with Extended Signal Length
May 18, 2024With the rapid growth of the Internet of Things ecosystem, Automatic Modulation Classification (AMC) has become increasingly paramount. However, extended signal lengths offer a bounty of information, yet impede the model's adaptability, introduce more noise interference, extend the training and inference time, and increase storage overhead. To bridge the gap between these requisites, we propose a novel AMC framework, designated as the Mamba-based Automatic Modulation ClassificAtion (MAMCA). Our method adeptly addresses the accuracy and efficiency requirements for long-sequence AMC. Specifically, we introduce the Selective State Space Model as the backbone, enhancing the model efficiency by reducing the dimensions of the state matrices and diminishing the frequency of information exchange across GPU memories. We design a denoising-capable unit to elevate the network's performance under low signal-to-noise radio. Rigorous experimental evaluations on the publicly available dataset RML2016.10, along with our synthetic dataset within multiple quadrature amplitude modulations and lengths, affirm that MAMCA delivers superior recognition accuracy while necessitating minimal computational time and memory occupancy. Codes are available on https://github.com/ZhangYezhuo/MAMCA.
Attributes Grouping and Mining Hashing for Fine-Grained Image Retrieval
Nov 10, 2023In recent years, hashing methods have been popular in the large-scale media search for low storage and strong representation capabilities. To describe objects with similar overall appearance but subtle differences, more and more studies focus on hashing-based fine-grained image retrieval. Existing hashing networks usually generate both local and global features through attention guidance on the same deep activation tensor, which limits the diversity of feature representations. To handle this limitation, we substitute convolutional descriptors for attention-guided features and propose an Attributes Grouping and Mining Hashing (AGMH), which groups and embeds the category-specific visual attributes in multiple descriptors to generate a comprehensive feature representation for efficient fine-grained image retrieval. Specifically, an Attention Dispersion Loss (ADL) is designed to force the descriptors to attend to various local regions and capture diverse subtle details. Moreover, we propose a Stepwise Interactive External Attention (SIEA) to mine critical attributes in each descriptor and construct correlations between fine-grained attributes and objects. The attention mechanism is dedicated to learning discrete attributes, which will not cost additional computations in hash codes generation. Finally, the compact binary codes are learned by preserving pairwise similarities. Experimental results demonstrate that AGMH consistently yields the best performance against state-of-the-art methods on fine-grained benchmark datasets.
Detecting Any Human-Object Interaction Relationship: Universal HOI Detector with Spatial Prompt Learning on Foundation Models
Nov 07, 2023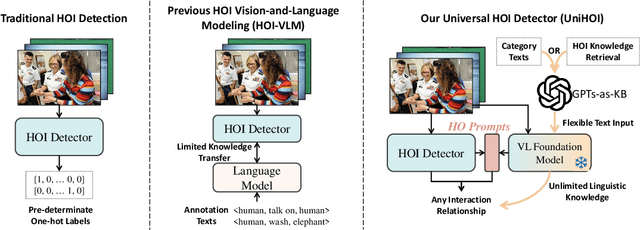
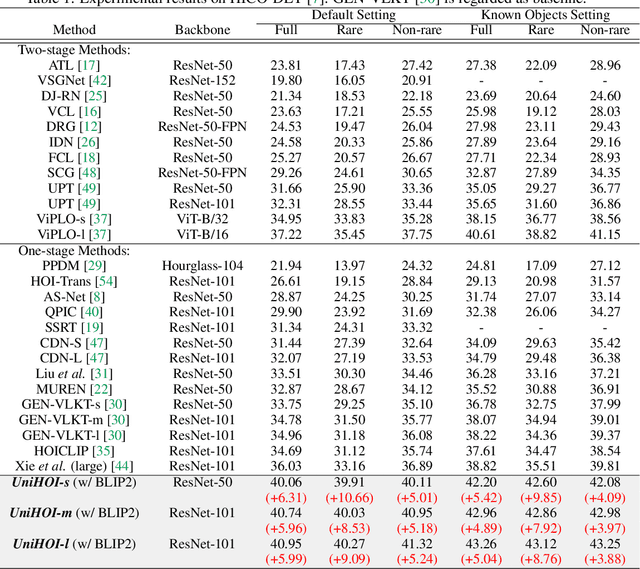
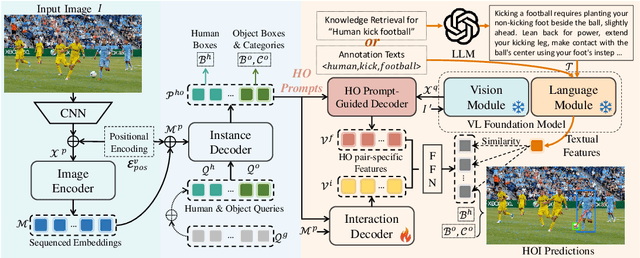
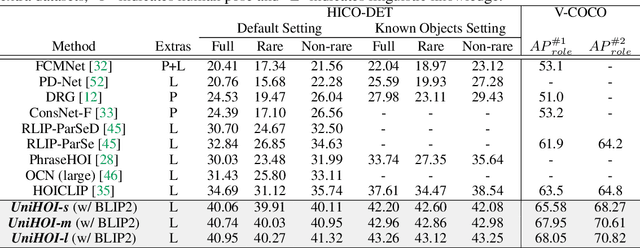
Human-object interaction (HOI) detection aims to comprehend the intricate relationships between humans and objects, predicting $<human, action, object>$ triplets, and serving as the foundation for numerous computer vision tasks. The complexity and diversity of human-object interactions in the real world, however, pose significant challenges for both annotation and recognition, particularly in recognizing interactions within an open world context. This study explores the universal interaction recognition in an open-world setting through the use of Vision-Language (VL) foundation models and large language models (LLMs). The proposed method is dubbed as \emph{\textbf{UniHOI}}. We conduct a deep analysis of the three hierarchical features inherent in visual HOI detectors and propose a method for high-level relation extraction aimed at VL foundation models, which we call HO prompt-based learning. Our design includes an HO Prompt-guided Decoder (HOPD), facilitates the association of high-level relation representations in the foundation model with various HO pairs within the image. Furthermore, we utilize a LLM (\emph{i.e.} GPT) for interaction interpretation, generating a richer linguistic understanding for complex HOIs. For open-category interaction recognition, our method supports either of two input types: interaction phrase or interpretive sentence. Our efficient architecture design and learning methods effectively unleash the potential of the VL foundation models and LLMs, allowing UniHOI to surpass all existing methods with a substantial margin, under both supervised and zero-shot settings. The code and pre-trained weights are available at: \url{https://github.com/Caoyichao/UniHOI}.
Re-mine, Learn and Reason: Exploring the Cross-modal Semantic Correlations for Language-guided HOI detection
Jul 25, 2023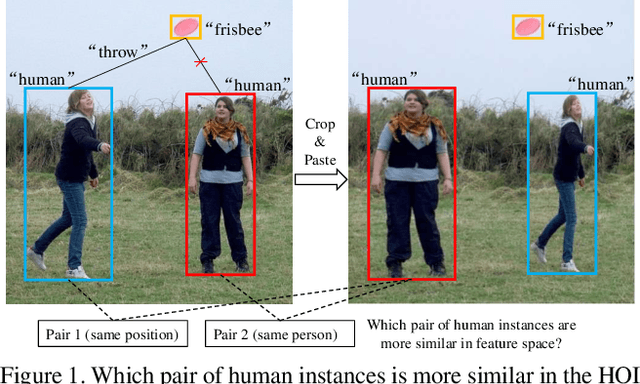

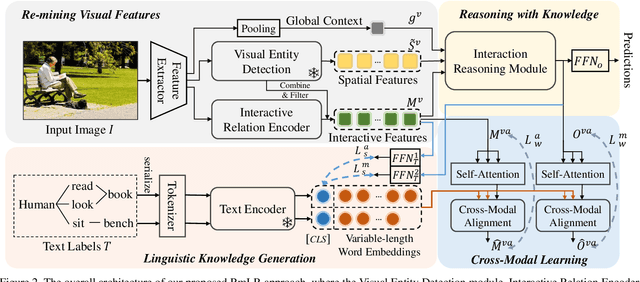

Human-Object Interaction (HOI) detection is a challenging computer vision task that requires visual models to address the complex interactive relationship between humans and objects and predict HOI triplets. Despite the challenges posed by the numerous interaction combinations, they also offer opportunities for multimodal learning of visual texts. In this paper, we present a systematic and unified framework (RmLR) that enhances HOI detection by incorporating structured text knowledge. Firstly, we qualitatively and quantitatively analyze the loss of interaction information in the two-stage HOI detector and propose a re-mining strategy to generate more comprehensive visual representation.Secondly, we design more fine-grained sentence- and word-level alignment and knowledge transfer strategies to effectively address the many-to-many matching problem between multiple interactions and multiple texts.These strategies alleviate the matching confusion problem that arises when multiple interactions occur simultaneously, thereby improving the effectiveness of the alignment process. Finally, HOI reasoning by visual features augmented with textual knowledge substantially improves the understanding of interactions. Experimental results illustrate the effectiveness of our approach, where state-of-the-art performance is achieved on public benchmarks. We further analyze the effects of different components of our approach to provide insights into its efficacy.
Contrastive Embedding Distribution Refinement and Entropy-Aware Attention for 3D Point Cloud Classification
Jan 27, 2022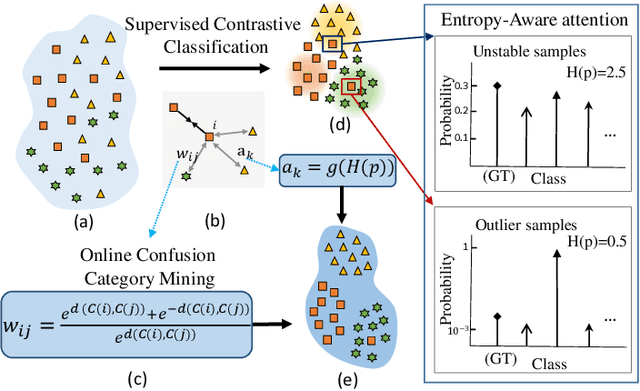
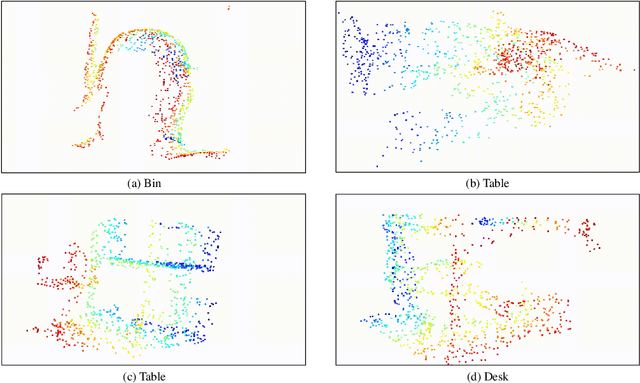
Learning a powerful representation from point clouds is a fundamental and challenging problem in the field of computer vision. Different from images where RGB pixels are stored in the regular grid, for point clouds, the underlying semantic and structural information of point clouds is the spatial layout of the points. Moreover, the properties of challenging in-context and background noise pose more challenges to point cloud analysis. One assumption is that the poor performance of the classification model can be attributed to the indistinguishable embedding feature that impedes the search for the optimal classifier. This work offers a new strategy for learning powerful representations via a contrastive learning approach that can be embedded into any point cloud classification network. First, we propose a supervised contrastive classification method to implement embedding feature distribution refinement by improving the intra-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class compactness and inter-class separability. Second, to solve the confusion problem caused by small inter-class variations between some similar-looking categories, we propose a confusion-prone class mining strategy to alleviate the confusion effect. Finally, considering that outliers of the sample clusters in the embedding space may cause performance degradation, we design an entropy-aware attention module with information entropy theory to identify the outlier cases and the unstable samples by measuring the uncertainty of predicted probability. The results of extensive experiments demonstrate that our method outperforms the state-of-the-art approaches by achieving 82.9% accuracy on the real-world ScanObjectNN dataset and substantial performance gains up to 2.9% in DCGNN, 3.1% in PointNet++, and 2.4% in GBNet.
A SOM-based Gradient-Free Deep Learning Method with Convergence Analysis
Jan 12, 2021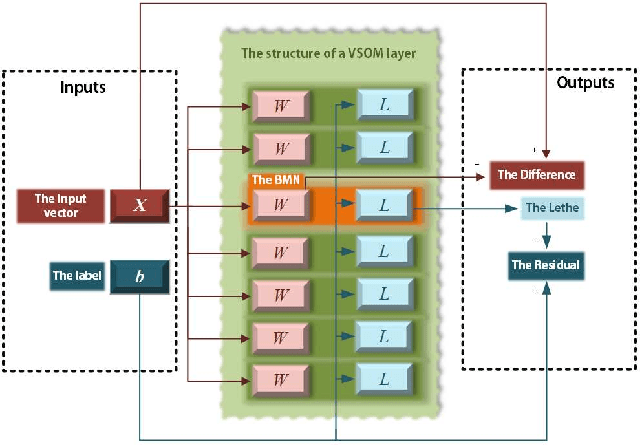
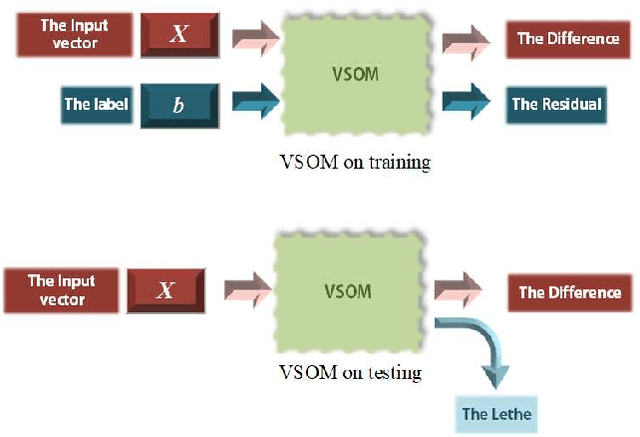
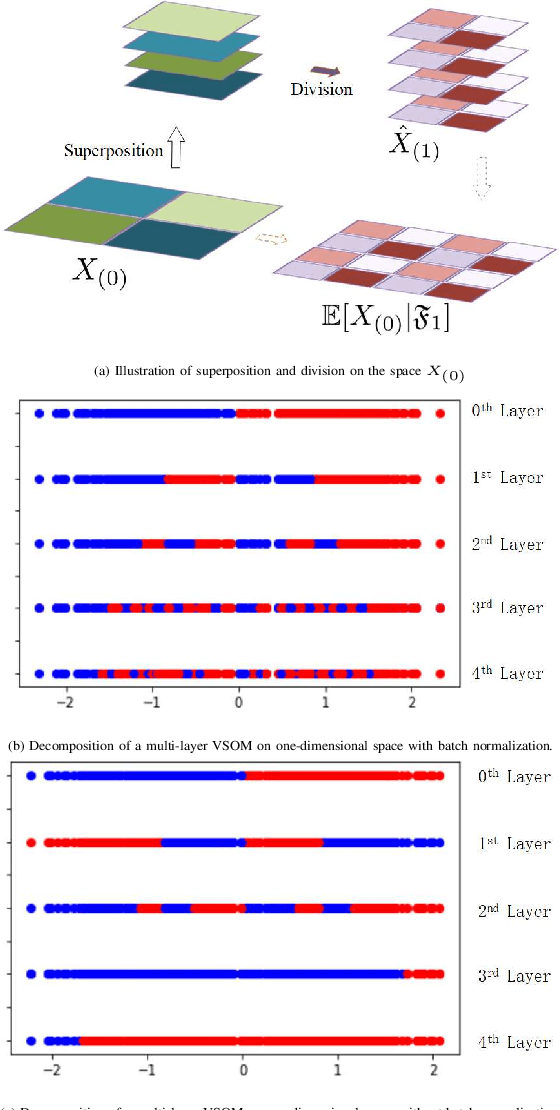
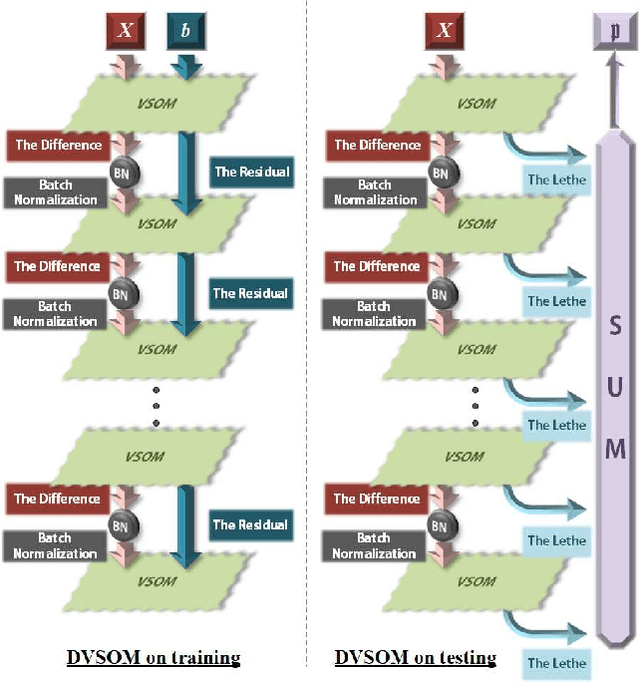
As gradient descent method in deep learning causes a series of questions, this paper proposes a novel gradient-free deep learning structure. By adding a new module into traditional Self-Organizing Map and introducing residual into the map, a Deep Valued Self-Organizing Map network is constructed. And analysis about the convergence performance of such a deep Valued Self-Organizing Map network is proved in this paper, which gives an inequality about the designed parameters with the dimension of inputs and the loss of prediction.