 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphSNN: Adaptive Graph Diffusion and Structural Plasticity for Spiking Neural Networks
Mar 15, 2026Spiking Neural Networks (SNNs) currently face a critical bottleneck: while individual neurons exhibit dynamic biological properties, their macro-scopic architectures remain confined within conventional connectivity patterns that are static and hierarchical. This discrepancy between neuron-level dynamics and network-level fixed connectivity eliminates critical brain-like lateral interactions, limiting adaptability in changing environments. To address this, we propose MorphSNN, a backbone framework inspired by biological non-synaptic diffusion and structural plasticity. Specifically, we introduce a Graph Diffusion (GD)mechanism to facilitate efficient undirected signal propagation, complementing the feedforward hierarchy. Furthermore, it incorporates a Spatio-Temporal Structural Plasticity (STSP) mechanism, endowing the network with the capability for instance-specific, dynamic topological reorganization, thereby overcoming the limitations of fixed topologies. Experiments demonstrate that MorphSNN achieves state-of-the-art accuracy on static and neuromorphic datasets; for instance, it reaches 83.35% accuracy on N-Caltech101 with only 5 timesteps. More importantly, its self-evolving topology functions as an intrinsic distribution fingerprint, enabling superior Out-of- Distribution (OOD) detection without auxiliary training. The code is available at anonymous.4open.science/r/MorphSNN-B0BC.
Towards General Agentic Intelligence via Environment Scaling
Sep 16, 2025Advanced agentic intelligence is a prerequisite for deploying Large Language Models in practical, real-world applications. Diverse real-world APIs demand precise, robust function-calling intelligence, which needs agents to develop these capabilities through interaction in varied environments. The breadth of function-calling competence is closely tied to the diversity of environments in which agents are trained. In this work, we scale up environments as a step towards advancing general agentic intelligence. This gives rise to two central challenges: (i) how to scale environments in a principled manner, and (ii) how to effectively train agentic capabilities from experiences derived through interactions with these environments. To address these, we design a scalable framework that automatically constructs heterogeneous environments that are fully simulated, systematically broadening the space of function-calling scenarios. We further adapt a two-phase agent fine-tuning strategy: first endowing agents with fundamental agentic capabilities, then specializing them for domain-specific contexts. Extensive experiments on agentic benchmarks, tau-bench, tau2-Bench, and ACEBench, demonstrate that our trained model, AgentScaler, significantly enhances the function-calling capability of models.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
Factorized Disentangled Representation Learning for Interpretable Radio Frequency Fingerprint
Aug 18, 2025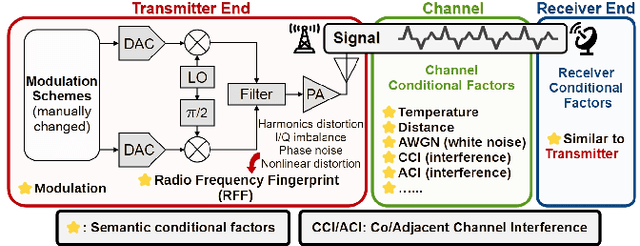
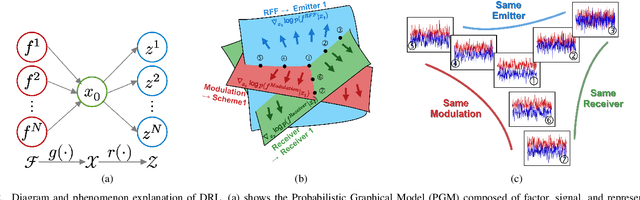
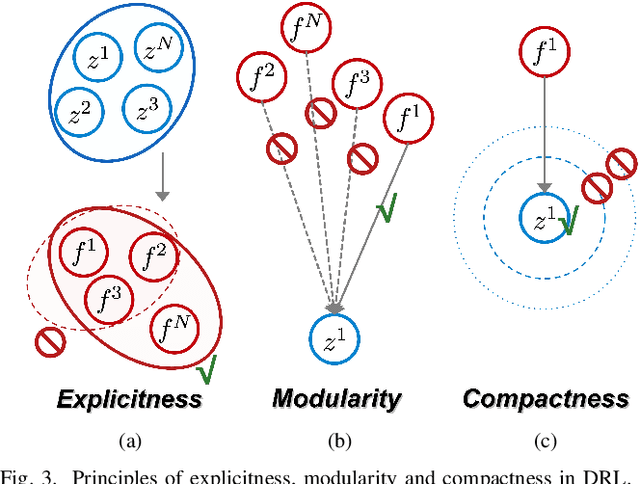
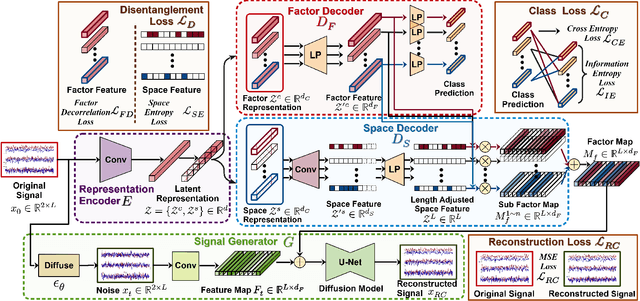
In response to the rapid growth of Internet of Things (IoT) devices and rising security risks, Radio Frequency Fingerprint (RFF) has become key for device identification and authentication. However, various changing factors - beyond the RFF itself - can be entangled from signal transmission to reception, reducing the effectiveness of RFF Identification (RFFI). Existing RFFI methods mainly rely on domain adaptation techniques, which often lack explicit factor representations, resulting in less robustness and limited controllability for downstream tasks. To tackle this problem, we propose a novel Disentangled Representation Learning (DRL) framework that learns explicit and independent representations of multiple factors, including the RFF. Our framework introduces modules for disentanglement, guided by the principles of explicitness, modularity, and compactness. We design two dedicated modules for factor classification and signal reconstruction, each with tailored loss functions that encourage effective disentanglement and enhance support for downstream tasks. Thus, the framework can extract a set of interpretable vectors that explicitly represent corresponding factors. We evaluate our approach on two public benchmark datasets and a self-collected dataset. Our method achieves impressive performance on multiple DRL metrics. We also analyze the effectiveness of our method on downstream RFFI task and conditional signal generation task. All modules of the framework contribute to improved classification accuracy, and enable precise control over conditional generated signals. These results highlight the potential of our DRL framework for interpretable and explicit RFFs.
Global Spatio-Temporal Fusion-based Traffic Prediction Algorithm with Anomaly Aware
Dec 19, 2024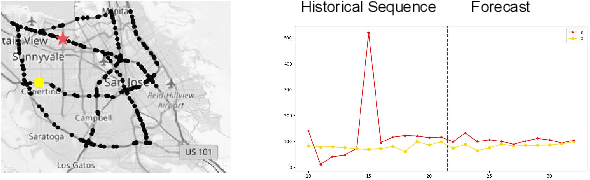
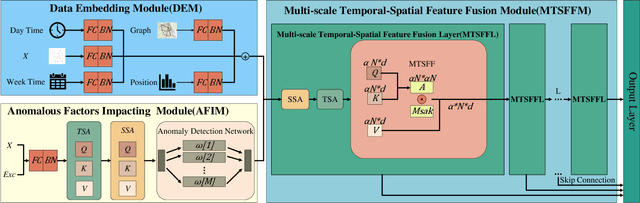
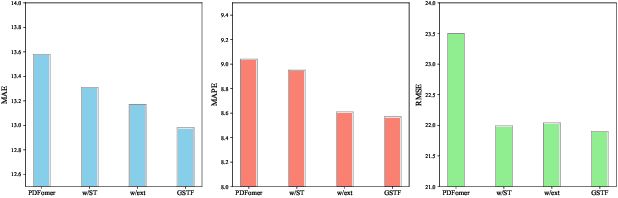
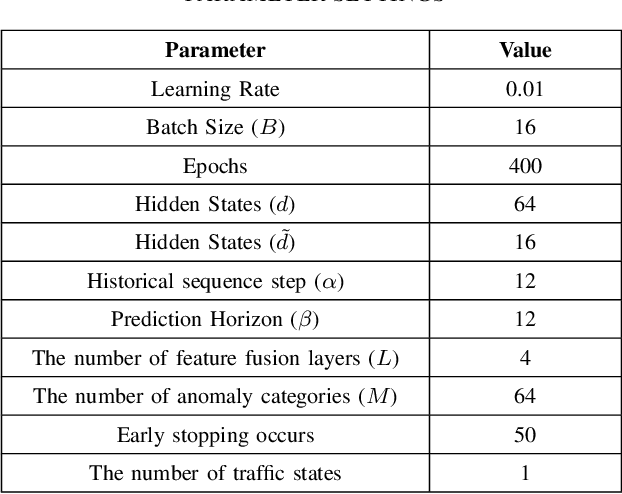
Traffic prediction is an indispensable component of urban planning and traffic management. Achieving accurate traffic prediction hinges on the ability to capture the potential spatio-temporal relationships among road sensors. However, the majority of existing works focus on local short-term spatio-temporal correlations, failing to fully consider the interactions of different sensors in the long-term state. In addition, these works do not analyze the influences of anomalous factors, or have insufficient ability to extract personalized features of anomalous factors, which make them ineffectively capture their spatio-temporal influences on traffic prediction. To address the aforementioned issues, We propose a global spatio-temporal fusion-based traffic prediction algorithm that incorporates anomaly awareness. Initially, based on the designed anomaly detection network, we construct an efficient anomalous factors impacting module (AFIM), to evaluate the spatio-temporal impact of unexpected external events on traffic prediction. Furthermore, we propose a multi-scale spatio-temporal feature fusion module (MTSFFL) based on the transformer architecture, to obtain all possible both long and short term correlations among different sensors in a wide-area traffic environment for accurate prediction of traffic flow. Finally, experiments are implemented based on real-scenario public transportation datasets (PEMS04 and PEMS08) to demonstrate that our approach can achieve state-of-the-art performance.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024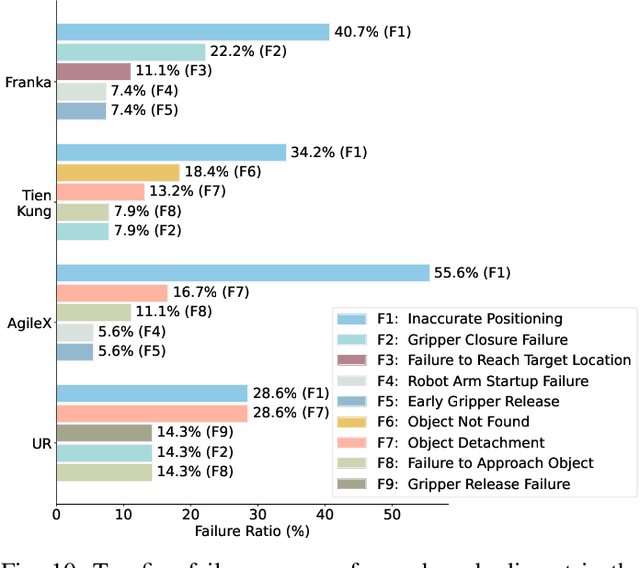
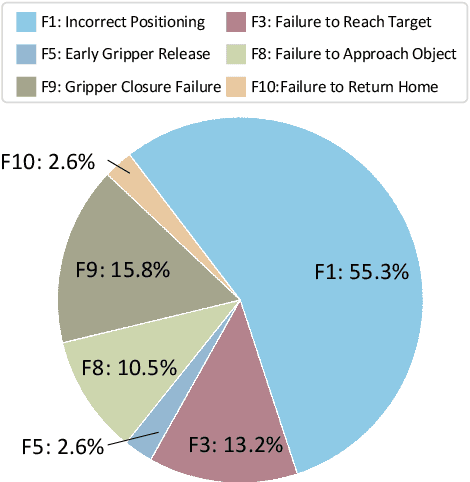
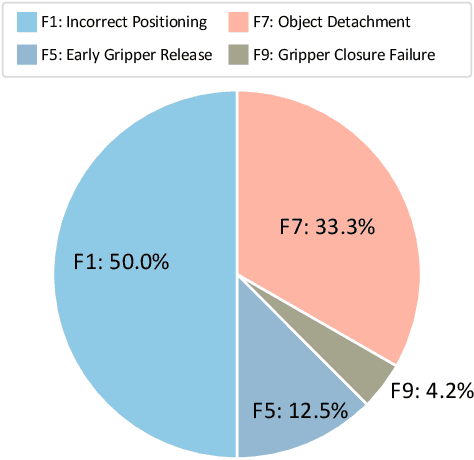
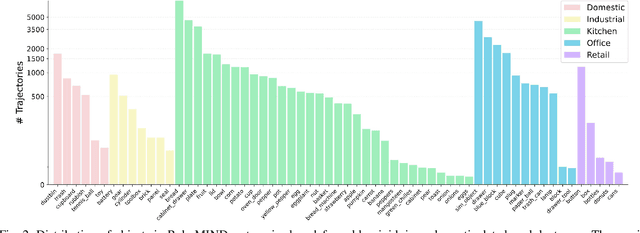
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
GazeGaussian: High-Fidelity Gaze Redirection with 3D Gaussian Splatting
Nov 20, 2024



Gaze estimation encounters generalization challenges when dealing with out-of-distribution data. To address this problem, recent methods use neural radiance fields (NeRF) to generate augmented data. However, existing methods based on NeRF are computationally expensive and lack facial details. 3D Gaussian Splatting (3DGS) has become the prevailing representation of neural fields. While 3DGS has been extensively examined in head avatars, it faces challenges with accurate gaze control and generalization across different subjects. In this work, we propose GazeGaussian, a high-fidelity gaze redirection method that uses a two-stream 3DGS model to represent the face and eye regions separately. By leveraging the unstructured nature of 3DGS, we develop a novel eye representation for rigid eye rotation based on the target gaze direction. To enhance synthesis generalization across various subjects, we integrate an expression-conditional module to guide the neural renderer. Comprehensive experiments show that GazeGaussian outperforms existing methods in rendering speed, gaze redirection accuracy, and facial synthesis across multiple datasets. We also demonstrate that existing gaze estimation methods can leverage GazeGaussian to improve their generalization performance. The code will be available at: https://ucwxb.github.io/GazeGaussian/.
MAMCA -- Optimal on Accuracy and Efficiency for Automatic Modulation Classification with Extended Signal Length
May 18, 2024With the rapid growth of the Internet of Things ecosystem, Automatic Modulation Classification (AMC) has become increasingly paramount. However, extended signal lengths offer a bounty of information, yet impede the model's adaptability, introduce more noise interference, extend the training and inference time, and increase storage overhead. To bridge the gap between these requisites, we propose a novel AMC framework, designated as the Mamba-based Automatic Modulation ClassificAtion (MAMCA). Our method adeptly addresses the accuracy and efficiency requirements for long-sequence AMC. Specifically, we introduce the Selective State Space Model as the backbone, enhancing the model efficiency by reducing the dimensions of the state matrices and diminishing the frequency of information exchange across GPU memories. We design a denoising-capable unit to elevate the network's performance under low signal-to-noise radio. Rigorous experimental evaluations on the publicly available dataset RML2016.10, along with our synthetic dataset within multiple quadrature amplitude modulations and lengths, affirm that MAMCA delivers superior recognition accuracy while necessitating minimal computational time and memory occupancy. Codes are available on https://github.com/ZhangYezhuo/MAMCA.
Domain adaptive pose estimation via multi-level alignment
Apr 25, 2024



Domain adaptive pose estimation aims to enable deep models trained on source domain (synthesized) datasets produce similar results on the target domain (real-world) datasets. The existing methods have made significant progress by conducting image-level or feature-level alignment. However, only aligning at a single level is not sufficient to fully bridge the domain gap and achieve excellent domain adaptive results. In this paper, we propose a multi-level domain adaptation aproach, which aligns different domains at the image, feature, and pose levels. Specifically, we first utilize image style transer to ensure that images from the source and target domains have a similar distribution. Subsequently, at the feature level, we employ adversarial training to make the features from the source and target domains preserve domain-invariant characeristics as much as possible. Finally, at the pose level, a self-supervised approach is utilized to enable the model to learn diverse knowledge, implicitly addressing the domain gap. Experimental results demonstrate that significant imrovement can be achieved by the proposed multi-level alignment method in pose estimation, which outperforms previous state-of-the-art in human pose by up to 2.4% and animal pose estimation by up to 3.1% for dogs and 1.4% for sheep.
A comprehensive framework for occluded human pose estimation
Jan 09, 2024Occlusion presents a significant challenge in human pose estimation. The challenges posed by occlusion can be attributed to the following factors: 1) Data: The collection and annotation of occluded human pose samples are relatively challenging. 2) Feature: Occlusion can cause feature confusion due to the high similarity between the target person and interfering individuals. 3) Inference: Robust inference becomes challenging due to the loss of complete body structural information. The existing methods designed for occluded human pose estimation usually focus on addressing only one of these factors. In this paper, we propose a comprehensive framework DAG (Data, Attention, Graph) to address the performance degradation caused by occlusion. Specifically, we introduce the mask joints with instance paste data augmentation technique to simulate occlusion scenarios. Additionally, an Adaptive Discriminative Attention Module (ADAM) is proposed to effectively enhance the features of target individuals. Furthermore, we present the Feature-Guided Multi-Hop GCN (FGMP-GCN) to fully explore the prior knowledge of body structure and improve pose estimation results. Through extensive experiments conducted on three benchmark datasets for occluded human pose estimation, we demonstrate that the proposed method outperforms existing methods. Code and data will be publicly available.