 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Fold: Dynamic Intent-Aware Context Folding for User-Centric Agents
Jan 26, 2026Large language model (LLM)-based agents have been successfully deployed in many tool-augmented settings, but their scalability is fundamentally constrained by context length. Existing context-folding methods mitigate this issue by summarizing past interactions, yet they are typically designed for single-query or single-intent scenarios. In more realistic user-centric dialogues, we identify two major failure modes: (i) they irreversibly discard fine-grained constraints and intermediate facts that are crucial for later decisions, and (ii) their summaries fail to track evolving user intent, leading to omissions and erroneous actions. To address these limitations, we propose U-Fold, a dynamic context-folding framework tailored to user-centric tasks. U-Fold retains the full user--agent dialogue and tool-call history but, at each turn, uses two core components to produce an intent-aware, evolving dialogue summary and a compact, task-relevant tool log. Extensive experiments on $τ$-bench, $τ^2$-bench, VitaBench, and harder context-inflated settings show that U-Fold consistently outperforms ReAct (achieving a 71.4% win rate in long-context settings) and prior folding baselines (with improvements of up to 27.0%), particularly on long, noisy, multi-turn tasks. Our study demonstrates that U-Fold is a promising step toward transferring context-management techniques from single-query benchmarks to realistic user-centric applications.
AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning
Dec 28, 2025Conducting reinforcement learning (RL) in simulated environments offers a cost-effective and highly scalable way to enhance language-based agents. However, previous work has been limited to semi-automated environment synthesis or tasks lacking sufficient difficulty, offering little breadth or depth. In addition, the instability of simulated users integrated into these environments, along with the heterogeneity across simulated environments, poses further challenges for agentic RL. In this work, we propose: (1) a unified pipeline for automated and scalable synthesis of simulated environments associated with high-difficulty but easily verifiable tasks; and (2) an environment level RL algorithm that not only effectively mitigates user instability but also performs advantage estimation at the environment level, thereby improving training efficiency and stability. Comprehensive evaluations on agentic benchmarks, including tau-bench, tau2-Bench, and VitaBench, validate the effectiveness of our proposed method. Further in-depth analyses underscore its out-of-domain generalization.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
Towards General Agentic Intelligence via Environment Scaling
Sep 16, 2025Advanced agentic intelligence is a prerequisite for deploying Large Language Models in practical, real-world applications. Diverse real-world APIs demand precise, robust function-calling intelligence, which needs agents to develop these capabilities through interaction in varied environments. The breadth of function-calling competence is closely tied to the diversity of environments in which agents are trained. In this work, we scale up environments as a step towards advancing general agentic intelligence. This gives rise to two central challenges: (i) how to scale environments in a principled manner, and (ii) how to effectively train agentic capabilities from experiences derived through interactions with these environments. To address these, we design a scalable framework that automatically constructs heterogeneous environments that are fully simulated, systematically broadening the space of function-calling scenarios. We further adapt a two-phase agent fine-tuning strategy: first endowing agents with fundamental agentic capabilities, then specializing them for domain-specific contexts. Extensive experiments on agentic benchmarks, tau-bench, tau2-Bench, and ACEBench, demonstrate that our trained model, AgentScaler, significantly enhances the function-calling capability of models.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
FLOW: A Feedback LOop FrameWork for Simultaneously Enhancing Recommendation and User Agents
Oct 26, 2024



Agents powered by large language models have shown remarkable reasoning and execution capabilities, attracting researchers to explore their potential in the recommendation domain. Previous studies have primarily focused on enhancing the capabilities of either recommendation agents or user agents independently, but have not considered the interaction and collaboration between recommendation agents and user agents. To address this gap, we propose a novel framework named FLOW, which achieves collaboration between the recommendation agent and the user agent by introducing a feedback loop. Specifically, the recommendation agent refines its understanding of the user's preferences by analyzing the user agent's feedback on previously suggested items, while the user agent leverages suggested items to uncover deeper insights into the user's latent interests. This iterative refinement process enhances the reasoning capabilities of both the recommendation agent and the user agent, enabling more precise recommendations and a more accurate simulation of user behavior. To demonstrate the effectiveness of the feedback loop, we evaluate both recommendation performance and user simulation performance on three widely used recommendation domain datasets. The experimental results indicate that the feedback loop can simultaneously improve the performance of both the recommendation and user agents.
GeoGPT4V: Towards Geometric Multi-modal Large Language Models with Geometric Image Generation
Jun 17, 2024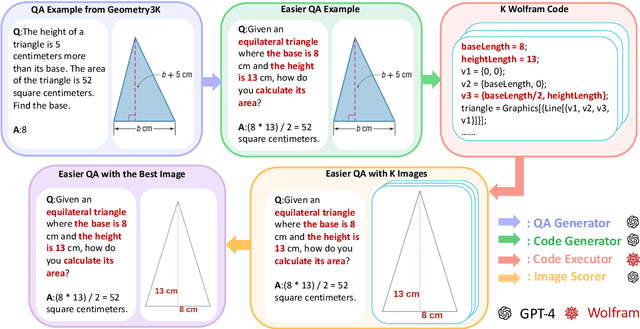
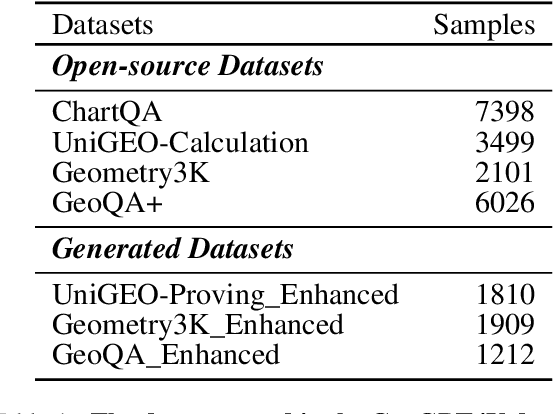
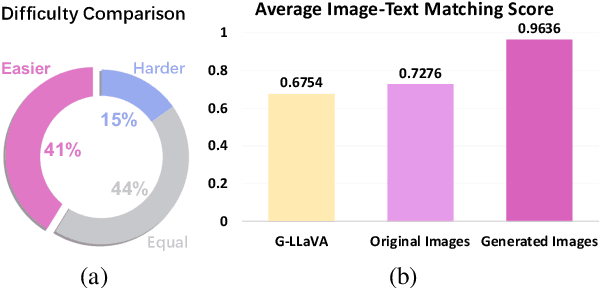
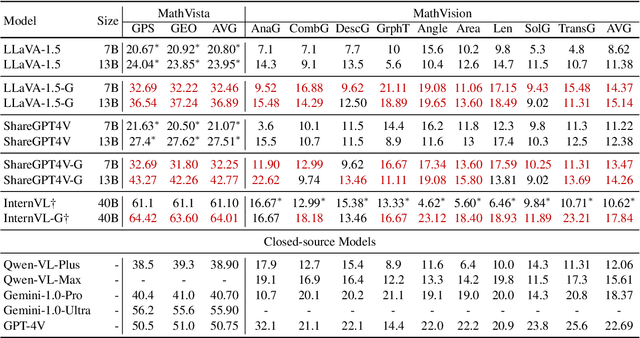
Large language models have seen widespread adoption in math problem-solving. However, in geometry problems that usually require visual aids for better understanding, even the most advanced multi-modal models currently still face challenges in effectively using image information. High-quality data is crucial for enhancing the geometric capabilities of multi-modal models, yet existing open-source datasets and related efforts are either too challenging for direct model learning or suffer from misalignment between text and images. To overcome this issue, we introduce a novel pipeline that leverages GPT-4 and GPT-4V to generate relatively basic geometry problems with aligned text and images, facilitating model learning. We have produced a dataset of 4.9K geometry problems and combined it with 19K open-source data to form our GeoGPT4V dataset. Experimental results demonstrate that the GeoGPT4V dataset significantly improves the geometry performance of various models on the MathVista and MathVision benchmarks. The code is available at https://github.com/Lanyu0303/GeoGPT4V_Project