 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025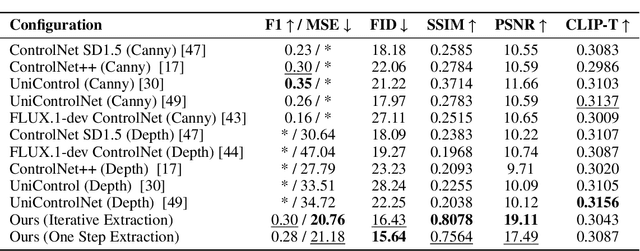
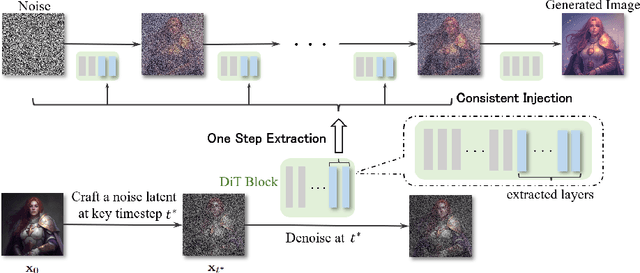
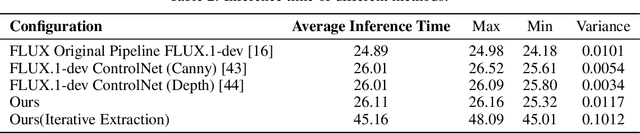

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
Leveraging Memory Retrieval to Enhance LLM-based Generative Recommendation
Dec 23, 2024



Leveraging Large Language Models (LLMs) to harness user-item interaction histories for item generation has emerged as a promising paradigm in generative recommendation. However, the limited context window of LLMs often restricts them to focusing on recent user interactions only, leading to the neglect of long-term interests involved in the longer histories. To address this challenge, we propose a novel Automatic Memory-Retrieval framework (AutoMR), which is capable of storing long-term interests in the memory and extracting relevant information from it for next-item generation within LLMs. Extensive experimental results on two real-world datasets demonstrate the effectiveness of our proposed AutoMR framework in utilizing long-term interests for generative recommendation.
Causality-Enhanced Behavior Sequence Modeling in LLMs for Personalized Recommendation
Oct 30, 2024



Recent advancements in recommender systems have focused on leveraging Large Language Models (LLMs) to improve user preference modeling, yielding promising outcomes. However, current LLM-based approaches struggle to fully leverage user behavior sequences, resulting in suboptimal preference modeling for personalized recommendations. In this study, we propose a novel Counterfactual Fine-Tuning (CFT) method to address this issue by explicitly emphasizing the role of behavior sequences when generating recommendations. Specifically, we employ counterfactual reasoning to identify the causal effects of behavior sequences on model output and introduce a task that directly fits the ground-truth labels based on these effects, achieving the goal of explicit emphasis. Additionally, we develop a token-level weighting mechanism to adjust the emphasis strength for different item tokens, reflecting the diminishing influence of behavior sequences from earlier to later tokens during predicting an item. Extensive experiments on real-world datasets demonstrate that CFT effectively improves behavior sequence modeling. Our codes are available at https://github.com/itsmeyjt/CFT.
Real-Time Personalization for LLM-based Recommendation with Customized In-Context Learning
Oct 30, 2024

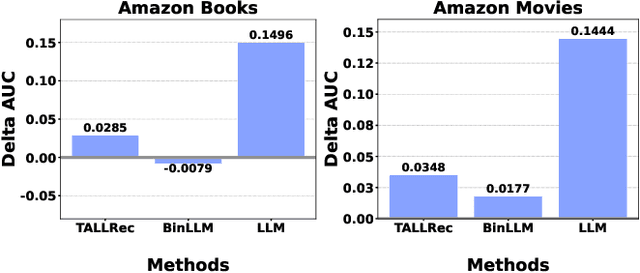

Frequently updating Large Language Model (LLM)-based recommender systems to adapt to new user interests -- as done for traditional ones -- is impractical due to high training costs, even with acceleration methods. This work explores adapting to dynamic user interests without any model updates by leveraging In-Context Learning (ICL), which allows LLMs to learn new tasks from few-shot examples provided in the input. Using new-interest examples as the ICL few-shot examples, LLMs may learn real-time interest directly, avoiding the need for model updates. However, existing LLM-based recommenders often lose the in-context learning ability during recommendation tuning, while the original LLM's in-context learning lacks recommendation-specific focus. To address this, we propose RecICL, which customizes recommendation-specific in-context learning for real-time recommendations. RecICL organizes training examples in an in-context learning format, ensuring that in-context learning ability is preserved and aligned with the recommendation task during tuning. Extensive experiments demonstrate RecICL's effectiveness in delivering real-time recommendations without requiring model updates. Our code is available at https://github.com/ym689/rec_icl.
FLOW: A Feedback LOop FrameWork for Simultaneously Enhancing Recommendation and User Agents
Oct 26, 2024



Agents powered by large language models have shown remarkable reasoning and execution capabilities, attracting researchers to explore their potential in the recommendation domain. Previous studies have primarily focused on enhancing the capabilities of either recommendation agents or user agents independently, but have not considered the interaction and collaboration between recommendation agents and user agents. To address this gap, we propose a novel framework named FLOW, which achieves collaboration between the recommendation agent and the user agent by introducing a feedback loop. Specifically, the recommendation agent refines its understanding of the user's preferences by analyzing the user agent's feedback on previously suggested items, while the user agent leverages suggested items to uncover deeper insights into the user's latent interests. This iterative refinement process enhances the reasoning capabilities of both the recommendation agent and the user agent, enabling more precise recommendations and a more accurate simulation of user behavior. To demonstrate the effectiveness of the feedback loop, we evaluate both recommendation performance and user simulation performance on three widely used recommendation domain datasets. The experimental results indicate that the feedback loop can simultaneously improve the performance of both the recommendation and user agents.
Debias Can be Unreliable: Mitigating Bias Issue in Evaluating Debiasing Recommendation
Sep 07, 2024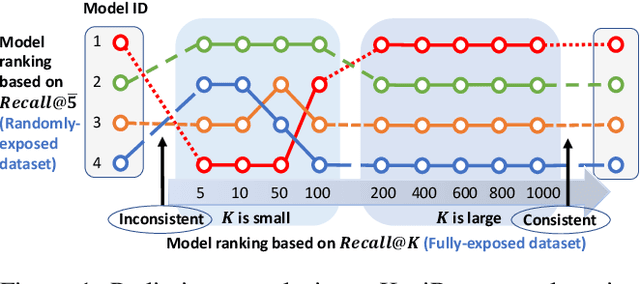
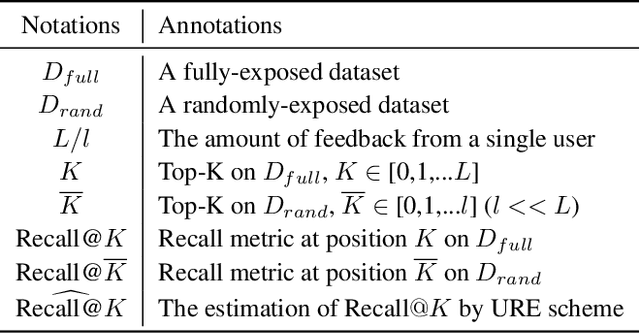
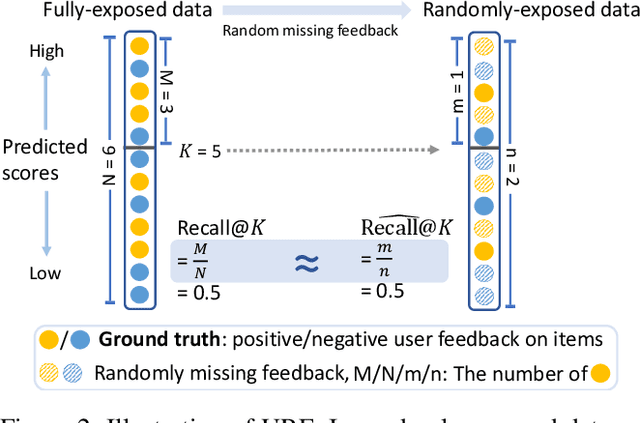

Recent work has improved recommendation models remarkably by equipping them with debiasing methods. Due to the unavailability of fully-exposed datasets, most existing approaches resort to randomly-exposed datasets as a proxy for evaluating debiased models, employing traditional evaluation scheme to represent the recommendation performance. However, in this study, we reveal that traditional evaluation scheme is not suitable for randomly-exposed datasets, leading to inconsistency between the Recall performance obtained using randomly-exposed datasets and that obtained using fully-exposed datasets. Such inconsistency indicates the potential unreliability of experiment conclusions on previous debiasing techniques and calls for unbiased Recall evaluation using randomly-exposed datasets. To bridge the gap, we propose the Unbiased Recall Evaluation (URE) scheme, which adjusts the utilization of randomly-exposed datasets to unbiasedly estimate the true Recall performance on fully-exposed datasets. We provide theoretical evidence to demonstrate the rationality of URE and perform extensive experiments on real-world datasets to validate its soundness.
Decoding Matters: Addressing Amplification Bias and Homogeneity Issue for LLM-based Recommendation
Jun 21, 2024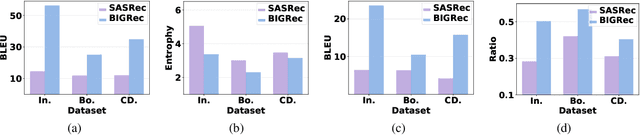
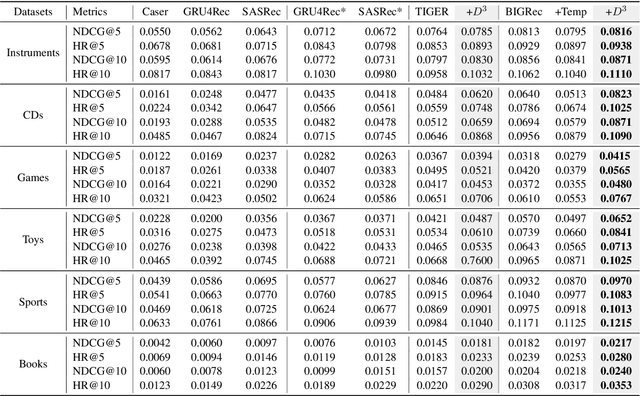
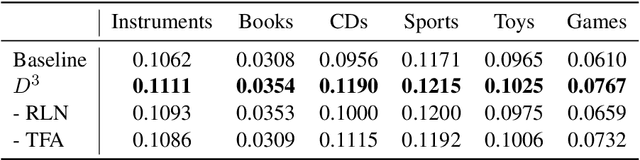
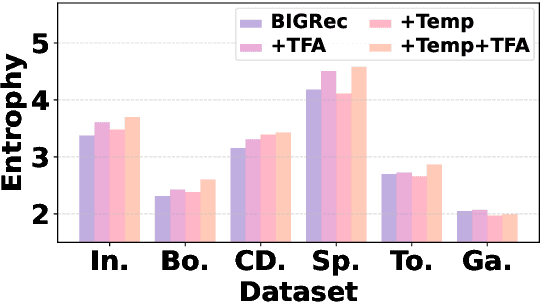
Adapting Large Language Models (LLMs) for recommendation requires careful consideration of the decoding process, given the inherent differences between generating items and natural language. Existing approaches often directly apply LLMs' original decoding methods. However, we find these methods encounter significant challenges: 1) amplification bias -- where standard length normalization inflates scores for items containing tokens with generation probabilities close to 1 (termed ghost tokens), and 2) homogeneity issue -- generating multiple similar or repetitive items for a user. To tackle these challenges, we introduce a new decoding approach named Debiasing-Diversifying Decoding (D3). D3 disables length normalization for ghost tokens to alleviate amplification bias, and it incorporates a text-free assistant model to encourage tokens less frequently generated by LLMs for counteracting recommendation homogeneity. Extensive experiments on real-world datasets demonstrate the method's effectiveness in enhancing accuracy and diversity.
GeoGPT4V: Towards Geometric Multi-modal Large Language Models with Geometric Image Generation
Jun 17, 2024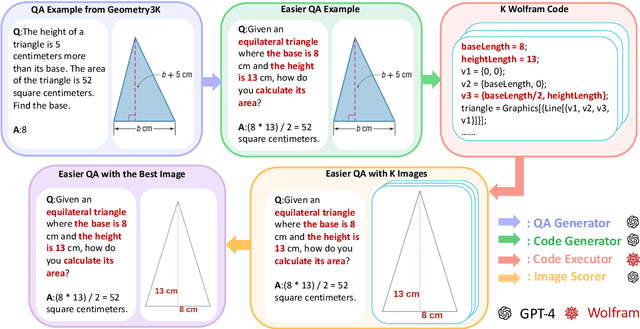
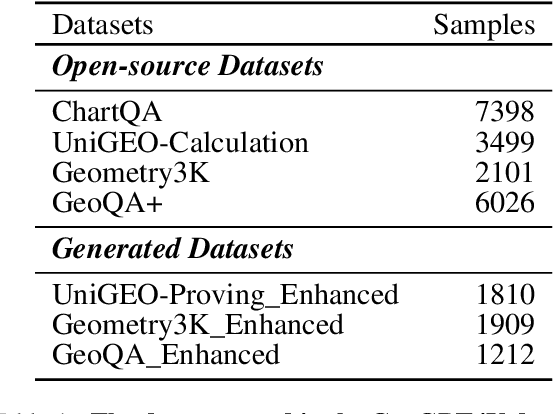
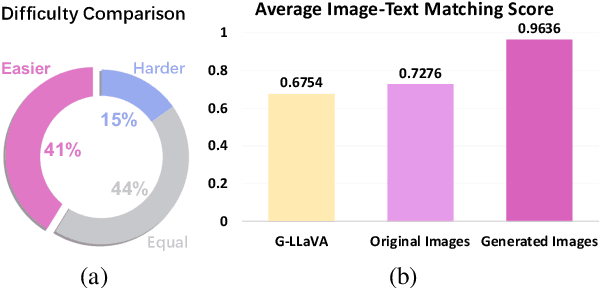
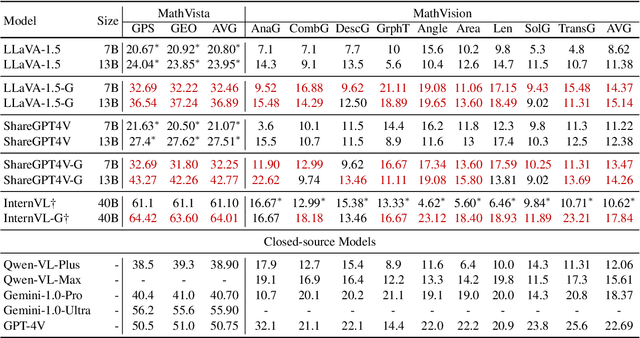
Large language models have seen widespread adoption in math problem-solving. However, in geometry problems that usually require visual aids for better understanding, even the most advanced multi-modal models currently still face challenges in effectively using image information. High-quality data is crucial for enhancing the geometric capabilities of multi-modal models, yet existing open-source datasets and related efforts are either too challenging for direct model learning or suffer from misalignment between text and images. To overcome this issue, we introduce a novel pipeline that leverages GPT-4 and GPT-4V to generate relatively basic geometry problems with aligned text and images, facilitating model learning. We have produced a dataset of 4.9K geometry problems and combined it with 19K open-source data to form our GeoGPT4V dataset. Experimental results demonstrate that the GeoGPT4V dataset significantly improves the geometry performance of various models on the MathVista and MathVision benchmarks. The code is available at https://github.com/Lanyu0303/GeoGPT4V_Project