 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
Jan 28, 2026Item indexing, which maps a large corpus of items into compact discrete representations, is critical for both discriminative and generative recommender systems, yet existing Vector Quantization (VQ)-based approaches struggle with the highly skewed and non-stationary item distributions common in streaming industry recommenders, leading to poor assignment accuracy, imbalanced cluster occupancy, and insufficient cluster separation. To address these challenges, we propose MERGE, a next-generation item indexing paradigm that adaptively constructs clusters from scratch, dynamically monitors cluster occupancy, and forms hierarchical index structures via fine-to-coarse merging. Extensive experiments demonstrate that MERGE significantly improves assignment accuracy, cluster uniformity, and cluster separation compared with existing indexing methods, while online A/B tests show substantial gains in key business metrics, highlighting its potential as a foundational indexing approach for large-scale recommendation.
UniGRec: Unified Generative Recommendation with Soft Identifiers for End-to-End Optimization
Jan 24, 2026Generative recommendation has recently emerged as a transformative paradigm that directly generates target items, surpassing traditional cascaded approaches. It typically involves two components: a tokenizer that learns item identifiers and a recommender trained on them. Existing methods often decouple tokenization from recommendation or rely on asynchronous alternating optimization, limiting full end-to-end alignment. To address this, we unify the tokenizer and recommender under the ultimate recommendation objective via differentiable soft item identifiers, enabling joint end-to-end training. However, this introduces three challenges: training-inference discrepancy due to soft-to-hard mismatch, item identifier collapse from codeword usage imbalance, and collaborative signal deficiency due to an overemphasis on fine-grained token-level semantics. To tackle these challenges, we propose UniGRec, a unified generative recommendation framework that addresses them from three perspectives. UniGRec employs Annealed Inference Alignment during tokenization to smoothly bridge soft training and hard inference, a Codeword Uniformity Regularization to prevent identifier collapse and encourage codebook diversity, and a Dual Collaborative Distillation mechanism that distills collaborative priors from a lightweight teacher model to jointly guide both the tokenizer and the recommender. Extensive experiments on real-world datasets demonstrate that UniGRec consistently outperforms state-of-the-art baseline methods. Our codes are available at https://github.com/Jialei-03/UniGRec.
Unveiling Inference Scaling for Difference-Aware User Modeling in LLM Personalization
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into users' daily lives, driving a growing demand for personalized outputs. Prior work has primarily leveraged a user's own history, often overlooking inter-user differences that are critical for effective personalization. While recent methods have attempted to model such differences, their feature extraction processes typically rely on fixed dimensions and quick, intuitive inference (System-1 thinking), limiting both the coverage and granularity of captured user differences. To address these limitations, we propose Difference-aware Reasoning Personalization (DRP), a framework that reconstructs the difference extraction mechanism by leveraging inference scaling to enhance LLM personalization. DRP autonomously identifies relevant difference feature dimensions and generates structured definitions and descriptions, enabling slow, deliberate reasoning (System-2 thinking) over user differences. Experiments on personalized review generation demonstrate that DRP consistently outperforms baseline methods across multiple metrics.
Unconditional Diffusion for Generative Sequential Recommendation
Jul 08, 2025Diffusion models, known for their generative ability to simulate data creation through noise-adding and denoising processes, have emerged as a promising approach for building generative recommenders. To incorporate user history for personalization, existing methods typically adopt a conditional diffusion framework, where the reverse denoising process of reconstructing items from noise is modified to be conditioned on the user history. However, this design may fail to fully utilize historical information, as it gets distracted by the need to model the "item $\leftrightarrow$ noise" translation. This motivates us to reformulate the diffusion process for sequential recommendation in an unconditional manner, treating user history (instead of noise) as the endpoint of the forward diffusion process (i.e., the starting point of the reverse process), rather than as a conditional input. This formulation allows for exclusive focus on modeling the "item $\leftrightarrow$ history" translation. To this end, we introduce Brownian Bridge Diffusion Recommendation (BBDRec). By leveraging a Brownian bridge process, BBDRec enforces a structured noise addition and denoising mechanism, ensuring that the trajectories are constrained towards a specific endpoint -- user history, rather than noise. Extensive experiments demonstrate BBDRec's effectiveness in enhancing sequential recommendation performance. The source code is available at https://github.com/baiyimeng/BBDRec.
DiscRec: Disentangled Semantic-Collaborative Modeling for Generative Recommendation
Jun 18, 2025Generative recommendation is emerging as a powerful paradigm that directly generates item predictions, moving beyond traditional matching-based approaches. However, current methods face two key challenges: token-item misalignment, where uniform token-level modeling ignores item-level granularity that is critical for collaborative signal learning, and semantic-collaborative signal entanglement, where collaborative and semantic signals exhibit distinct distributions yet are fused in a unified embedding space, leading to conflicting optimization objectives that limit the recommendation performance. To address these issues, we propose DiscRec, a novel framework that enables Disentangled Semantic-Collaborative signal modeling with flexible fusion for generative Recommendation.First, DiscRec introduces item-level position embeddings, assigned based on indices within each semantic ID, enabling explicit modeling of item structure in input token sequences.Second, DiscRec employs a dual-branch module to disentangle the two signals at the embedding layer: a semantic branch encodes semantic signals using original token embeddings, while a collaborative branch applies localized attention restricted to tokens within the same item to effectively capture collaborative signals. A gating mechanism subsequently fuses both branches while preserving the model's ability to model sequential dependencies. Extensive experiments on four real-world datasets demonstrate that DiscRec effectively decouples these signals and consistently outperforms state-of-the-art baselines. Our codes are available on https://github.com/Ten-Mao/DiscRec.
Unconstrained Monotonic Calibration of Predictions in Deep Ranking Systems
Apr 19, 2025Ranking models primarily focus on modeling the relative order of predictions while often neglecting the significance of the accuracy of their absolute values. However, accurate absolute values are essential for certain downstream tasks, necessitating the calibration of the original predictions. To address this, existing calibration approaches typically employ predefined transformation functions with order-preserving properties to adjust the original predictions. Unfortunately, these functions often adhere to fixed forms, such as piece-wise linear functions, which exhibit limited expressiveness and flexibility, thereby constraining their effectiveness in complex calibration scenarios. To mitigate this issue, we propose implementing a calibrator using an Unconstrained Monotonic Neural Network (UMNN), which can learn arbitrary monotonic functions with great modeling power. This approach significantly relaxes the constraints on the calibrator, improving its flexibility and expressiveness while avoiding excessively distorting the original predictions by requiring monotonicity. Furthermore, to optimize this highly flexible network for calibration, we introduce a novel additional loss function termed Smooth Calibration Loss (SCLoss), which aims to fulfill a necessary condition for achieving the ideal calibration state. Extensive offline experiments confirm the effectiveness of our method in achieving superior calibration performance. Moreover, deployment in Kuaishou's large-scale online video ranking system demonstrates that the method's calibration improvements translate into enhanced business metrics. The source code is available at https://github.com/baiyimeng/UMC.
Measuring What Makes You Unique: Difference-Aware User Modeling for Enhancing LLM Personalization
Mar 04, 2025Personalizing Large Language Models (LLMs) has become a critical step in facilitating their widespread application to enhance individual life experiences. In pursuit of personalization, distilling key preference information from an individual's historical data as instructional preference context to customize LLM generation has emerged as a promising direction. However, these methods face a fundamental limitation by overlooking the inter-user comparative analysis, which is essential for identifying the inter-user differences that truly shape preferences. To address this limitation, we propose Difference-aware Personalization Learning (DPL), a novel approach that emphasizes extracting inter-user differences to enhance LLM personalization. DPL strategically selects representative users for comparison and establishes a structured standard to extract meaningful, task-relevant differences for customizing LLM generation. Extensive experiments on real-world datasets demonstrate that DPL significantly enhances LLM personalization. We release our code at https://github.com/SnowCharmQ/DPL.
Causality-Enhanced Behavior Sequence Modeling in LLMs for Personalized Recommendation
Oct 30, 2024



Recent advancements in recommender systems have focused on leveraging Large Language Models (LLMs) to improve user preference modeling, yielding promising outcomes. However, current LLM-based approaches struggle to fully leverage user behavior sequences, resulting in suboptimal preference modeling for personalized recommendations. In this study, we propose a novel Counterfactual Fine-Tuning (CFT) method to address this issue by explicitly emphasizing the role of behavior sequences when generating recommendations. Specifically, we employ counterfactual reasoning to identify the causal effects of behavior sequences on model output and introduce a task that directly fits the ground-truth labels based on these effects, achieving the goal of explicit emphasis. Additionally, we develop a token-level weighting mechanism to adjust the emphasis strength for different item tokens, reflecting the diminishing influence of behavior sequences from earlier to later tokens during predicting an item. Extensive experiments on real-world datasets demonstrate that CFT effectively improves behavior sequence modeling. Our codes are available at https://github.com/itsmeyjt/CFT.
GradCraft: Elevating Multi-task Recommendations through Holistic Gradient Crafting
Jul 29, 2024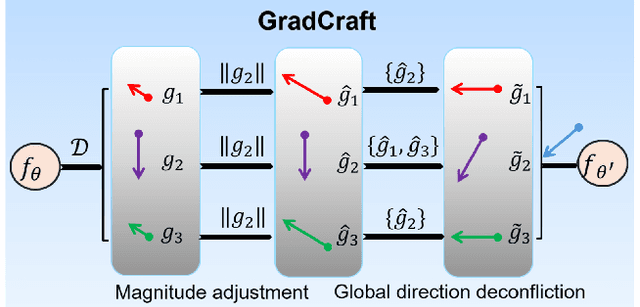

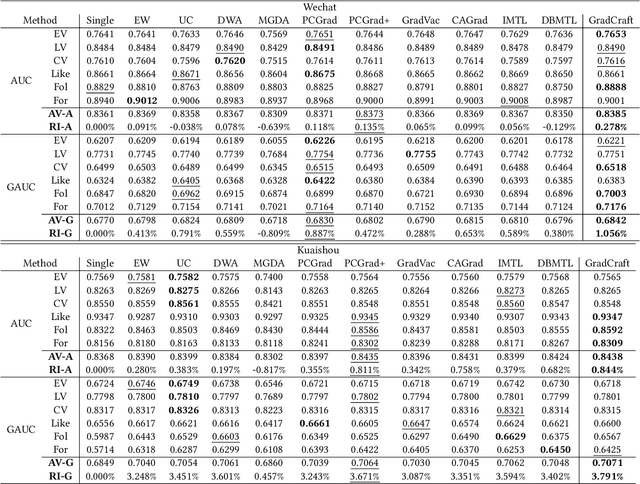
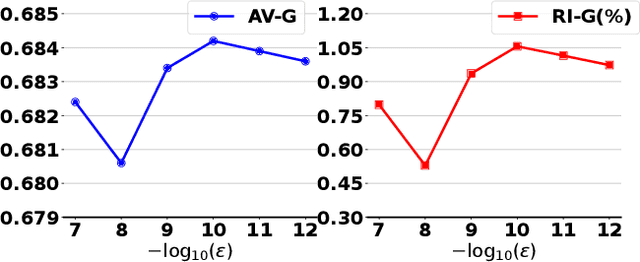
Recommender systems require the simultaneous optimization of multiple objectives to accurately model user interests, necessitating the application of multi-task learning methods. However, existing multi-task learning methods in recommendations overlook the specific characteristics of recommendation scenarios, falling short in achieving proper gradient balance. To address this challenge, we set the target of multi-task learning as attaining the appropriate magnitude balance and the global direction balance, and propose an innovative methodology named GradCraft in response. GradCraft dynamically adjusts gradient magnitudes to align with the maximum gradient norm, mitigating interference from gradient magnitudes for subsequent manipulation. It then employs projections to eliminate gradient conflicts in directions while considering all conflicting tasks simultaneously, theoretically guaranteeing the global resolution of direction conflicts. GradCraft ensures the concurrent achievement of appropriate magnitude balance and global direction balance, aligning with the inherent characteristics of recommendation scenarios. Both offline and online experiments attest to the efficacy of GradCraft in enhancing multi-task performance in recommendations. The source code for GradCraft can be accessed at https://github.com/baiyimeng/GradCraft.
LabelCraft: Empowering Short Video Recommendations with Automated Label Crafting
Dec 18, 2023Short video recommendations often face limitations due to the quality of user feedback, which may not accurately depict user interests. To tackle this challenge, a new task has emerged: generating more dependable labels from original feedback. Existing label generation methods rely on manual rules, demanding substantial human effort and potentially misaligning with the desired objectives of the platform. To transcend these constraints, we introduce LabelCraft, a novel automated label generation method explicitly optimizing pivotal operational metrics for platform success. By formulating label generation as a higher-level optimization problem above recommender model optimization, LabelCraft introduces a trainable labeling model for automatic label mechanism modeling. Through meta-learning techniques, LabelCraft effectively addresses the bi-level optimization hurdle posed by the recommender and labeling models, enabling the automatic acquisition of intricate label generation mechanisms.Extensive experiments on real-world datasets corroborate LabelCraft's excellence across varied operational metrics, encompassing usage time, user engagement, and retention. Codes are available at https://github.com/baiyimeng/LabelCraft.