 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
ELASTIC: Efficient Linear Attention for Sequential Interest Compression
Aug 20, 2024



State-of-the-art sequential recommendation models heavily rely on transformer's attention mechanism. However, the quadratic computational and memory complexities of self attention have limited its scalability for modeling users' long range behaviour sequences. To address this problem, we propose ELASTIC, an Efficient Linear Attention for SequenTial Interest Compression, requiring only linear time complexity and decoupling model capacity from computational cost. Specifically, ELASTIC introduces a fixed length interest experts with linear dispatcher attention mechanism which compresses the long-term behaviour sequences to a significantly more compact representation which reduces up to 90% GPU memory usage with x2.7 inference speed up. The proposed linear dispatcher attention mechanism significantly reduces the quadratic complexity and makes the model feasible for adequately modeling extremely long sequences. Moreover, in order to retain the capacity for modeling various user interests, ELASTIC initializes a vast learnable interest memory bank and sparsely retrieves compressed user's interests from the memory with a negligible computational overhead. The proposed interest memory retrieval technique significantly expands the cardinality of available interest space while keeping the same computational cost, thereby striking a trade-off between recommendation accuracy and efficiency. To validate the effectiveness of our proposed ELASTIC, we conduct extensive experiments on various public datasets and compare it with several strong sequential recommenders. Experimental results demonstrate that ELASTIC consistently outperforms baselines by a significant margin and also highlight the computational efficiency of ELASTIC when modeling long sequences. We will make our implementation code publicly available.
Leveraging Watch-time Feedback for Short-Video Recommendations: A Causal Labeling Framework
Jun 30, 2023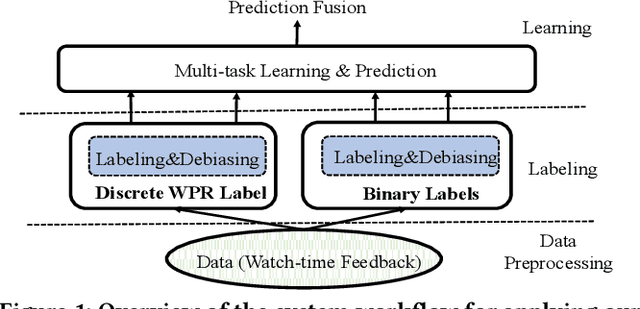

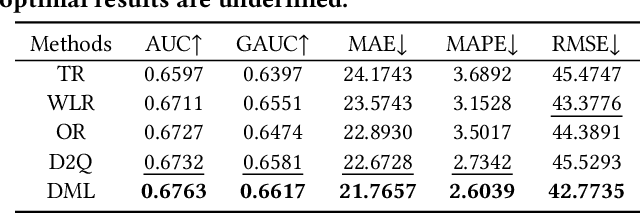
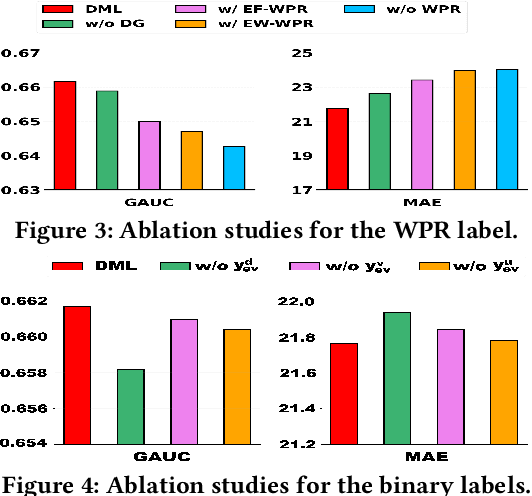
With the proliferation of short video applications, the significance of short video recommendations has vastly increased. Unlike other recommendation scenarios, short video recommendation systems heavily rely on feedback from watch time. Existing approaches simply treat watch time as a direct label, failing to effectively harness its extensive semantics and introduce bias, thereby limiting the potential for modeling user interests based on watch time. To overcome this challenge, we propose a framework named Debiasied Multiple-semantics-extracting Labeling (DML). DML constructs labels that encompass various semantics by utilizing quantiles derived from the distribution of watch time, prioritizing relative order rather than absolute label values. This approach facilitates easier model learning while aligning with the ranking objective of recommendations. Furthermore, we introduce a method inspired by causal adjustment to refine label definitions, thereby reducing the impact of bias on the label and directly mitigating bias at the label level. We substantiate the effectiveness of our DML framework through both online and offline experiments. Extensive results demonstrate that our DML could effectively leverage watch time to discover users' real interests, enhancing their engagement in our application.